







1. 本篇文章所用数据:
文本数据——size(2, 3, 5) (N, C, L) 例如:我爱吃苹果 你爱吃吗? 可以理解为: 两句话,每句话五个字,每个字的特征长度为3(批次大小为2,每一批有五个特征,每个特征尺寸为3),即batch:2 ,channel:3 , length:5
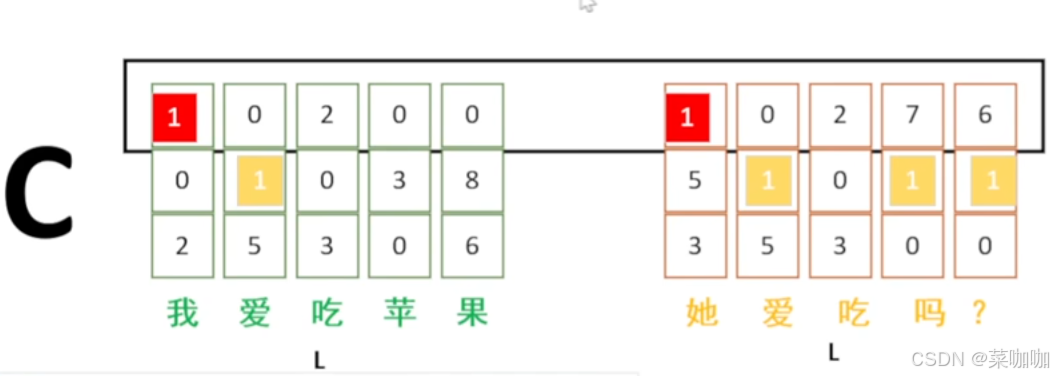
图1 文本数据batch normalization的示意图
2. 五种归一化方式的概念及理解:
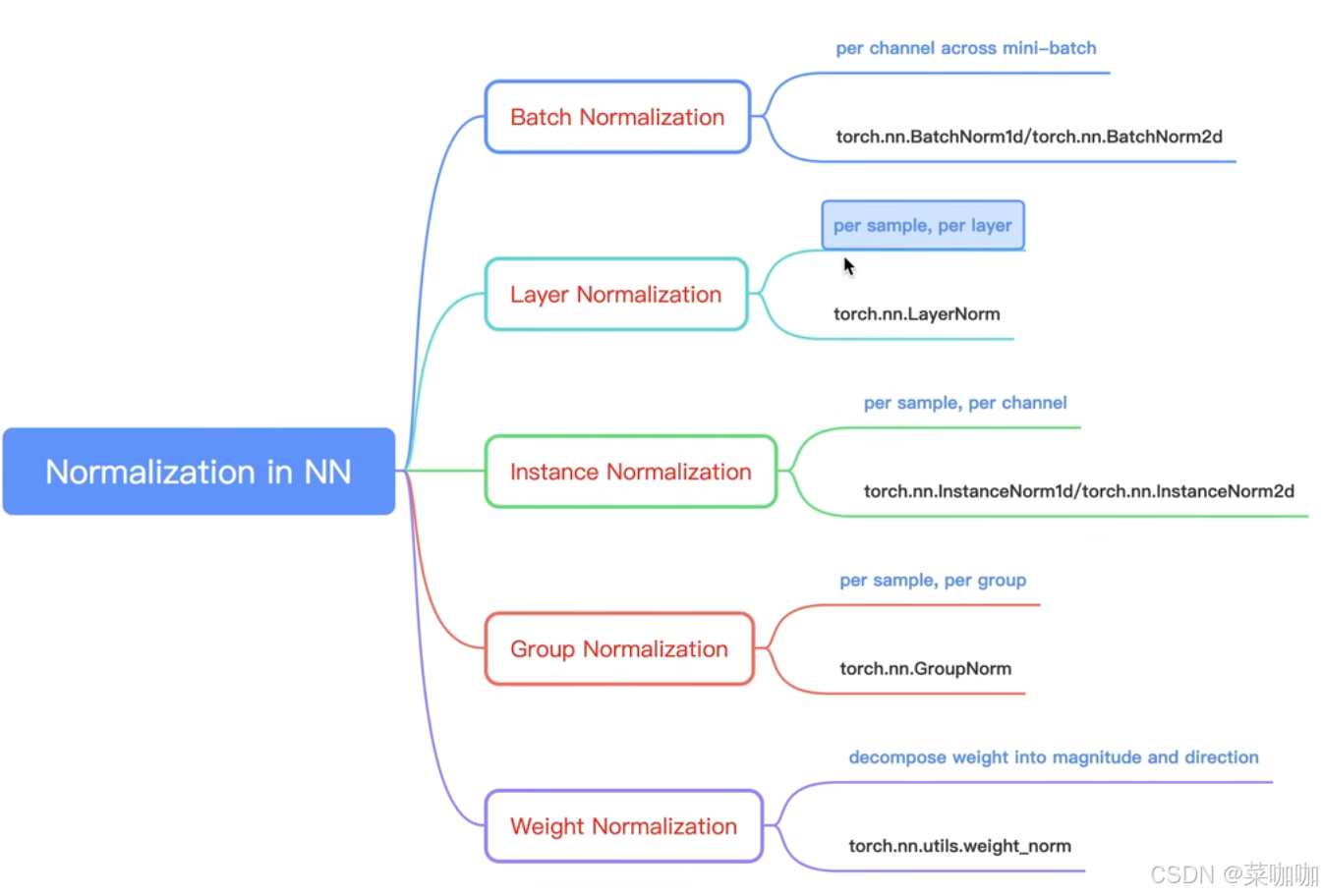
图2 五种归一化方式的理解
2.1 BatchNormalization
对多个batch的多个length的每个channel进行归一化,即对于(2, 3, 5)尺寸的数据,会有3个mean和3个stdvar。即每次归一化是以图1中黑色矩形框选的内容作为一个单元。
ps:对于nlp任务而言,基本不使用BN方法,一方面是因为nlp任务中不同的词条长度不同,即难以保持length这个参数是一样的,很不方便使用BN;另一方面是因为,同一句子中的同一个字的特征表示可能完全不同,或者同一句子中的不同字特征完全一样,例如图1中的”我“和”她“特征就是一样的,但是实际上这是完全不同的含义,因此nlp任务中很少使用BN。但是对于图像中的像素来讲就没有这种烦恼,因此更多是图像领域在使用BN。
代码实现如下:
import torch
import torch.nn as nn
batch_size = 2 # batch数
channel = 3 # 句子中每个字的特征长度
length = 5 # 句子长度
torch.manual_seed(5)
inputX = torch.randn(batch_size, length, channel) # N*L*C
#- 1.batch normalization的实现
#= 调用batch_norm API
batch_norm_op = torch.nn.BatchNorm1d(channel, affine=False)
bn_re = batch_norm_op(inputX.transpose(-1, -2)).transpose(-1, -2)
print(bn_re)
#= 手写 batch_norm
bn_mean = inputX.mean(dim=(0, 1),keepdim=True)
print(bn_mean)
bn_std = inputX.std(dim=(0, 1), unbiased=Fa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









