










CRF三大问题举例计算(以词性标注举例)
目录
0. 相关设定
观测序列O为:“我-参加-面试”(已分词)
当前词性集包含{PN(代词),VV(动词),NN(名词)}
“我”有PN,NN的可能词性(如:古代“我”也指兵器)
“参加” 有VV,NN的可能性(如:感谢您的“参加”)
“面试”有VV,NN的可能性(如:参加“面试”、“面试”求职者)
1. 学习问题(Learning problem)
问题描述
已知观测序列O,求最优的W=(λ,μ)
解决方式:梯度下降法
CRF对状态之间的转移 和 观测对状态的影响,分别由二元(局部)特征函数 t(yi-1, yi, X) 和一元(节点)函数 s(yi, Xi) 来描述。即能够转移或者能够标注,函数值为1(如:t(yi-1 = VV, yi = PN, X) == 1, s(yi = PN,xi = ‘我’) == 1)。两类特征函数分别具有参数λ,μ,并且每个特定位置的函数参数都不同,这些参数为问题1中所要学习的参数
不妨将
- λk * t(yj-1, yj, X) 称为转移分数 T[j-1, j]
- μl * s(yj, Xi) 称为发射分数E[j, i]
- 观测下标 = i到状态下标 = j的分数称为S[j, i]
- S[i, i] = T[i-1, i] + E[i, i] + S[i-1, i-1]
则状态序列总分数score(X, Y) = S[n, n] = ΣT[i-1, i] + ΣE[i, i] (n为序列长度)
定义某种由观测序列X求得的状态序列Y的出现概率为P(Y|X) = exp[score(X,Y)] / Σ exp[score(X,Y)]。分母为每种可能的状态序列的score的 总和。令P(Y|X)最大时,或者说令-log[P(Y|X)] 最小的Yi,对应的Wi=(λ,μ),为最优参数,此时的Yi为最合适的状态序列。将**-log[P(Yi|X)]** 作为损失函数,即可按梯度下降法进行参数Wi的求解。
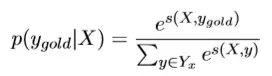
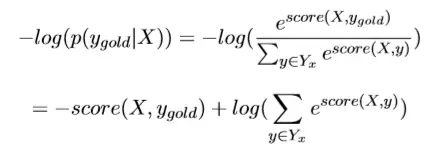
整体流程
1.随机初始化各参数W0
2.根据训练集真实Y序列与所有可能求出的Y序列对应的score计算损失函数
3.进行梯度下降,迭代更新参数
4.确定全局最优点对应的参数Wi
score计算的流程
假设梯度下降法求得下一步迭代的μl和λk,则易求发射分数矩阵E和转移分数矩阵T
E:发射分数矩阵(E[i, i] = s(yi, Xi) * μl)
如图所示
E[0, 0]∈ {s(y0=PN, x0=‘我’)x0.5, s(y0=NN, x0=‘我’)x0.1}
E[1, 1]∈ {s(y1=VV, ‘x1=参加’)x0.3, s(y1=NN, x1=‘参加’)x0.2}
E[2, 2]∈ {s(y2=VV, x2=‘面试’)x0.2, s(y2=NN, x2=‘面试’)x0.4}
l∈[1,6]
| 我(i=0) | 参加(i=1) | 面试(i=2) | |
|---|---|---|---|
| PN | 0.5 | 0 | 0 |
| VV | 0 | 0.3 | 0.2 |
| NN | 0.1 | 0.2 | 0.4 |
T:转移分数矩阵(T[i-1, i] = t(yi-1, yi) * λk)
如图所示
T[0, 1]∈{t(y0=PN, y1=VV)x0.3, t(y0=VV, y1=PN)x0.2, t(y0=VV, y1=NN)x0.5, t(y0=NN, y1=VV)x0.2, t(y0=NN, y1=NN)x0.1}
T[1, 2]∈{t(y0=PN, y1=VV)x0.3, t(y0=VV, y1=PN)x0.1, t(y0=VV, y1=NN)x0.6, t(y0=NN, y1=VV)x0.2}
K∈[1, 9]
| index 0->1 | PN(i=1) | VV(i=1) | NN(i=1) |
|---|---|---|---|
| PN(i=0) | 0 | 0.3 | 0 |
| VV(i=0) | 0.2 | 0 | 0.5 |
| NN(i=0) | 0 | 0.2 | 0.1 |
| index 1->2 | PN(i=2) | VV(i=2) | NN(i=2) |
|---|---|---|---|
| PN(i=1) | 0 | 0.3 | 0 |
| VV(i=1) | 0.1 | 0 | 0.6 |
| NN(i=1) | 0 | 0.2 | 0 |
所有取值大于0的分数
E[0, 0]∈ {s(y0=PN, x0=‘我’)x0.5, s(y0=NN, x0=‘我’)x0.1}
E[1, 1]∈ {s(y1=VV, ‘x1=参加’)x0.3, s(y1=NN, x1=‘参加’)x0.2}
E[2, 2]∈ {s(y2=VV, x2=‘面试’)x0.2, s(y2=NN, x2=‘面试’)x0.4}
T[0, 1]∈{t(y0=PN, y1=VV)x0.3, t(y0=VV, y1=PN)x0.2, t(y0=VV, y1=NN)x0.5, t(y0=NN, y1=VV)x0.2, t(y0=NN, y1=NN)x0.1}
T[1, 2]∈{t(y0=PN, y1=VV)x0.3, t(y0=VV, y1=PN)x0.1, t(y0=VV, y1=NN)x0.6, t(y0=NN, y1=VV)x0.2}
K∈[1, 9]
存在形成观测序列O的部分可能的状态序列I及分数计算(略去了起始为VV的可能,)
| E[0, 0] | S[0, 0] | T[0, 1] | E[1, 1] | S[1, 1] | T[1, 2] | E[2, 2] | S[2, 2] | 备注 |
|---|---|---|---|---|---|---|---|---|
| (PN:我)0.5 | 0.5 | (PN-VV)0.3 | (VV:参加)0.3 | 0.5+0.3+0.3=1.1 | (VV-PN)0.1 | (PN:面试)0 | 1.1+0.1+0=1.2 | 存在E为0 |
| (PN:我)0.5 | 0.5 | (PN-VV)0.3 | (VV:参加)0.3 | 0.5+0.3+0.3=1.1 | (VV-NN)0.6 | (NN:面试)0.4 | 1.1+0.6+0.4=2.1 | |
| (NN:我)0.1 | 0.1 | (NN-VV)0.2 | (VV:参加)0.3 | 0.1+0.2+0.3=0.6 | (VV-PN)0.1 | (PN:面试)0 | 0.6+0.1+0=0.7 | 存在E为0 |
| (NN:我)0.1 | 0.1 | (NN-VV)0.2 | (VV:参加)0.3 | 0.1+0.2+0.3=0.6 | (VV-NN)0.6 | (NN:面试)0.4 | 0.6+0.6+0.4=1.6 | |
| (NN:我)0.1 | 0.1 | (NN-NN)0.1 | (NN:参加)0.2 | 0.1+0.1+0.3=0.5 | (NN-VV)0.2 | (VV:面试)0.2 | 0.5+0.2+0.2=0.9 |
注:如上图所示,最优的序列只可能从1,3,4行状态序列中取,因为0,2行存在E为0,其实路径中E为0和T为0都不是最优解(基于贪心),只是在计算总score时会去计算(总score需要计算全部的路径)
2. 概率推断问题(marginal probability inference problem)
问题描述
已知当前观测序列X,算出状态序列中每个位置所对应标注的概率P(yi | X) yi∈当前词性集,如P(y1=VV|X={“我”“参加”“面试”})
解决方式:前向-后向算法
本质是上述可能性计算中所有可能的状态序列中y1=VV的概率,中间确定,左右两端不定,所以当前总分数s[1, 1]=s[0,0] + T[0, 1] (且index1必须是词性是VV) + E[1, 1](且必须词性是VV),后续T[1, 2] (且index2必须是词性是VV)
求出s后,P(Y|X) = exp[s] / Σ exp[score(X,Y)]即求出结果
由于过程存在子问题重复,且后向也可递推,可用前向-后向递推,动态规划减少计算量,降低复杂度
3. 解码问题(MAP inference problem)
问题描述
已知当前观测序列X, 已知当前W=(λ,μ),找到一个最有可能的序列Y,即:Y^=argmaxP(Y|X),或者说当前句子最可能的词性标注方案是?
解决方式:维特比算法
本质是上述可能性序列概率最大的一个(例如非规范化分数=2.1的那个),注意不考虑E T为0的序列(贪心)
由于过程存在子问题重复,可用动态规划减少计算量,降低复杂度
4. 与HMM三大问题解法异同
差异
- 一是解决了HMM的观测独立性限制特征选择,使得前序观测序列的输入会影响当前观测序列的输入,体现在HMM中一个转移矩阵便可各个状态之间不考虑输入位置进行转移,而CRF中会出现(序列长度-1)个与当前位置相关的转移矩阵(如本文的index0->1矩阵,index1->2矩阵)
- 二是解决了MEMM由于齐次马尔可夫性导致的label bias问题,体现在进行了全局归一化处理,必须计算全部路径的score
- 三是在概率推断和解码问题上,HMM作为生成式模型,对问题的条件概率分布建模,而 HMM 是生成模型,对联合概率分布建模,必须求出联合概率才能累加出结果;在学习问题上,HMM采用EM算法,基于统计从语料中计算参数,CRF采用梯度下降的方法,基于损失函数更新参数
共性
- 在概率推断和解码问题上,还是能采用前向-后向算法和维特比算法进行动归式的求解
5. 后记
下面几个链接是笔者学习过程中觉得非常不错的文章和视频,分享给大家,也希望对我的文章的内容多批评指正
B站:手推讲解的白板推导CRF系列课程, by shuhuai008
Github:【NLP】从隐马尔科夫到条件随机场, by Maxma
知乎:通俗的解释条件随机场(CRF)模型, by 忆臻















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









