







描述
使用RNN,实现通过 s i n ( x ) sin(x) sin(x)预测 c o s ( x ) cos(x) cos(x)。
这是pytorch-handbook中的一个样例,具体网址如下:
实现代码
import numpy as np
import torch.nn as nn
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
# 解决 plt 不输出图片的问题
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
#
class Net(nn.Module):
def __init__(self, input_size, hidden_size):
super(Net, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True # 表示输入数据第一维是批大小
)
# 循环神经网路后加一个全连接网络来处理输出
self.out = nn.Linear(hidden_size, 1)
def forward(self, x, h_state):
output, h_state = self.rnn(x, h_state)
'''
由于每个时刻的 x 都需要一个输出
因此将output所有时刻的隐状态都作为全连接层的输入
'''
outs = self.out(output)
return outs, h_state
def train(
epochs=60, # 训练批次
input_size=1, # 每个x的维数
hidden_size=64, # 隐状态的维度
time_steps=20, # 每次创建 20 个数
h_state=None # 初始化 h0
):
net = Net(input_size=input_size, hidden_size=hidden_size)
# 优化器选择 Adam
optimizer = optim.Adam(net.parameters())
# 损失函数选择 MSE
loss_function = nn.MSELoss()
for epoch in range(epochs):
# 创建数据
start, end = epoch * np.pi, (epoch + 1) * np.pi
steps = np.linspace(start, end, time_steps, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps)
# 将数据维度拓展为[batch, time_steps, input_size]
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
# 前向传播
y_pred, h_state = net(x, h_state)
'''
h_state = h_state.data 会重置 h_state的状态,让其能继续计算梯度
若删除,会出现如下错误
RuntimeError: Trying to backward through the graph a second time (or directly access saved variables after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved variables after calling backward.
'''
h_state = h_state.data
# 梯度下降
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print('epochs:{}, loss:{:4f}'.format(epoch + 1, loss))
# flatten(),将数据打平成一维
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, y_pred.data.numpy().flatten(), 'b-')
plt.title('epochs:{}, loss:{:4f}'.format(epoch + 1, loss))
plt.show()
if __name__ == '__main__':
train()
结果展示
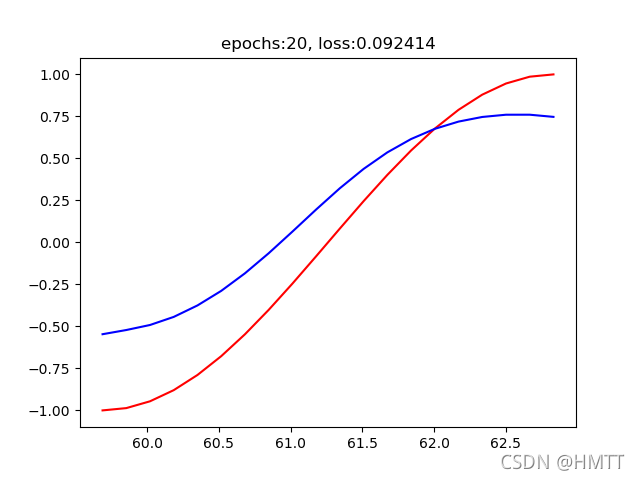
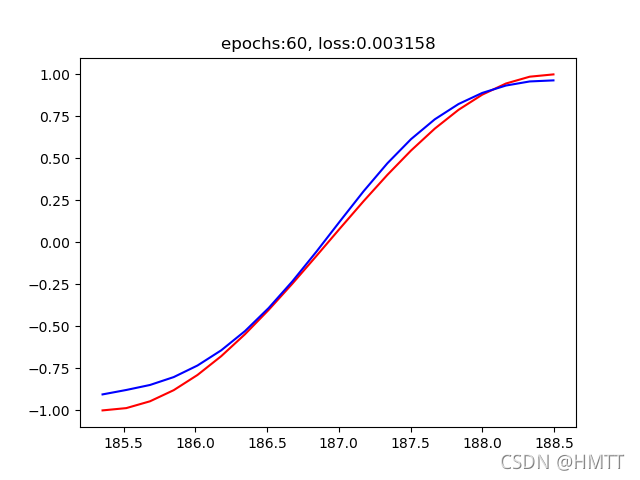
输出结果:
epochs:20, loss:0.092414
epochs:40, loss:0.011706
epochs:60, loss:0.003158
拟合图片:

注意
- 这里的训练过程可以看作是一次小批量梯度下降。并没有用同一数据进行多次训练。
- 里面的h_state的作用与一般的h_0不同,主要用来保存上次预测的隐状态。














 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









