







Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。 Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件,因而tensorboard和tensorflow程序在不同的进程中运行。 TensorBoard给我们提供了极其方便而强大的可视化环境。它可以帮助我们理解整个神经网络的学习过程、数据的分布、性能瓶颈等等。
安装
直接安装即可,使用pip install tensorboard
注:pytorch 1.1以后的版本内置了SummaryWriter 函数,所以不需要再安装tensorboardx了
页面介绍
tensorboard针对不同的类型数据区分多个标签,每一个标签页面代表不同的类型。简单介绍如下:
-
SCALAR
对标量数据进行汇总和记录,通常用来可视化训练过程中随着迭代次数准确率(val acc)、损失值(train/test loss)、学习率(learning rate)、每一层的权重和偏置的统计量(mean、std、max/min)等的变化曲线
-
IMAGES
可视化当前轮训练使用的训练/测试图片或者 feature maps
-
GRAPHS
可视化计算图的结构及计算图上的信息,通常用来展示网络的结构
-
HISTOGRAMS
可视化张量的取值分布,记录变量的直方图(统计张量随着迭代轮数的变化情况)
-
PROJECTOR
全称Embedding Projector 高维向量进行可视化
注:节选自pytorch中文手册https://github.com/zergtant/pytorch-handbook
创建SummaryWriter
在使用Tensorboard前,需要创建一个SummaryWriter 对象,常用的方法有三种,如下:
from torch.utils.tensorboard import SummaryWriter
# 默认使用 "runs/时间" 路径来保存日志
writer = SummaryWriter()
# 将日志保存在相应目录
writer = SummaryWriter("./logs")
# 使用 "runs/时间-comment" 路径来保存日志
writer = SummaryWriter(comment="abc")
SCALAR
使用add_scalar来记录数值。
add_scalar(tag, scalar_value, global_step=None, walltime=None)
- tag:字符串。数据名称。
- scalar_value:浮点型。数值。
- global_step:整形,可选。训练的step
- walltime:浮点型,可选。默认为
time.time()
一般用add_scalar来记录损失 loss、正确率 accurary、学习率 learning rate的变化,用来监控训练过程。
示例
先执行这段代码,将其存储在runs/2 中
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="runs/2")
for i in range(10):
writer.add_scalar("loss", (10 - i) ** 2, global_step=i)
writer.add_scalar("accurary", i**2 / 100, global_step=i)
writer.close()
再执行下面代码,将其存储在run/3中
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="runs/3")
for i in range(10):
writer.add_scalar("loss", (10 - i) ** 3, global_step=i)
writer.add_scalar("accurary", i**3 / 1000, global_step=i)
writer.close()
然后执行tensorboard --logdir=runs 运行结果如下图:

可见两个结果都存储成功,且通过左边的多选框中可以选择显示的数据。
IMAGES
使用add_image来记录数值。
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
- tag:字符串。数据名称。
- img_tensor:torch.Tensor。图像数据。
- global_step:整形,可选。训练的step
- walltime:浮点型,可选。默认为
time.time() - dataformats:图像数据格式,默认为
'CHW',即 Channel x Height x Width,还可以是'CHW'、'HWC'或'HW'等
import os
import time
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
# 这里的logs要与--logdir的参数一样
writer = SummaryWriter(log_dir='./logs')
transform_toTensor = transforms.Compose([
transforms.ToTensor()
])
imgs_dirt = "imgs/Kyaru"
imgs_filenames = os.listdir(imgs_dirt)
print(imgs_filenames)
for idx, filename in enumerate(imgs_filenames):
img = Image.open(os.path.join(imgs_dirt, filename))
img_tensor = transform_toTensor(img)
writer.add_image(
tag="Kyaru", # 数据名称
img_tensor=img_tensor, # 图像数据
global_step=idx, # 训练的step
walltime= time.time(), # 记录发生的时间,默认time.time()
dataformats="CHW" # 图像数据的格式,默认为 'CHW',即 Channel x Height x Width,还可以是 'CHW'、'HWC' 或 'HW' 等
)
# 下面是添加一张猫图片,将其命名为cat
cat_img = Image.open('Felis_silvestris_catus_lying_on_rice_straw.jpg')
cat_img_tensor = transform_toTensor(cat_img)
writer.add_image("cat",cat_img_tensor)
writer.close()# 执行close立即刷新,否则将每120秒自动刷新
多个step效果展示
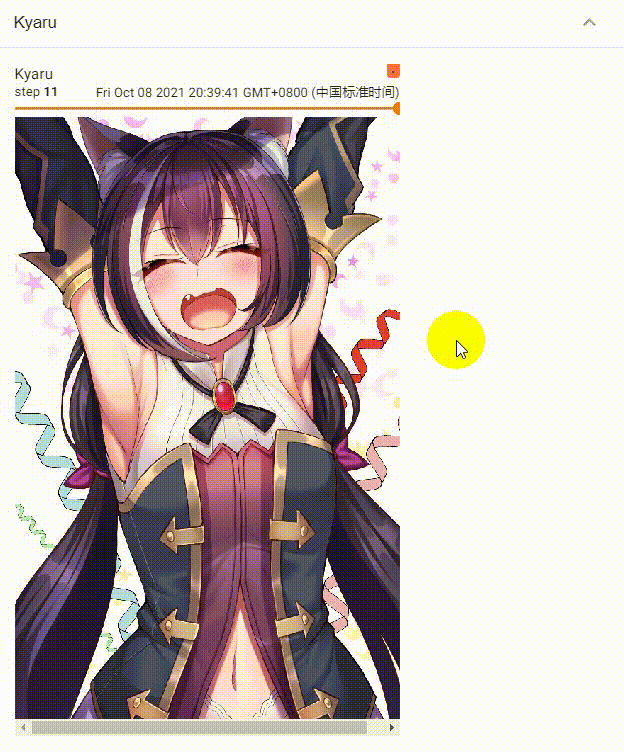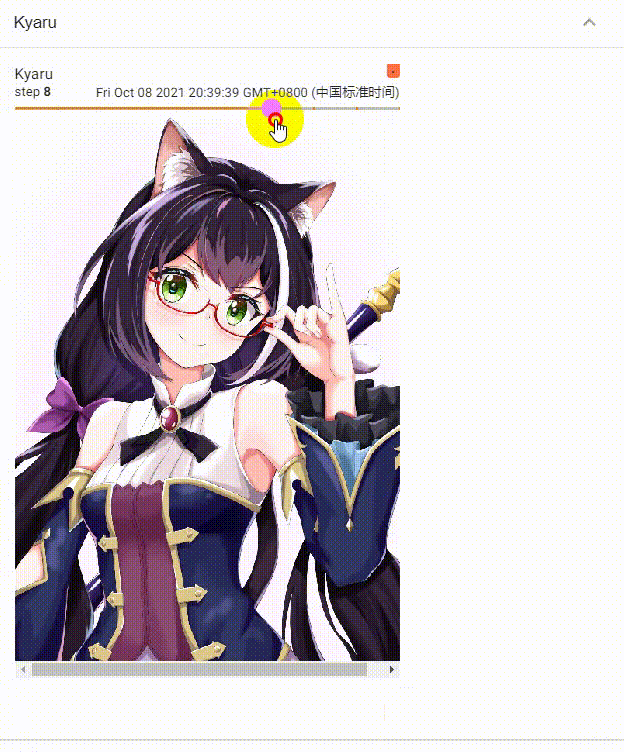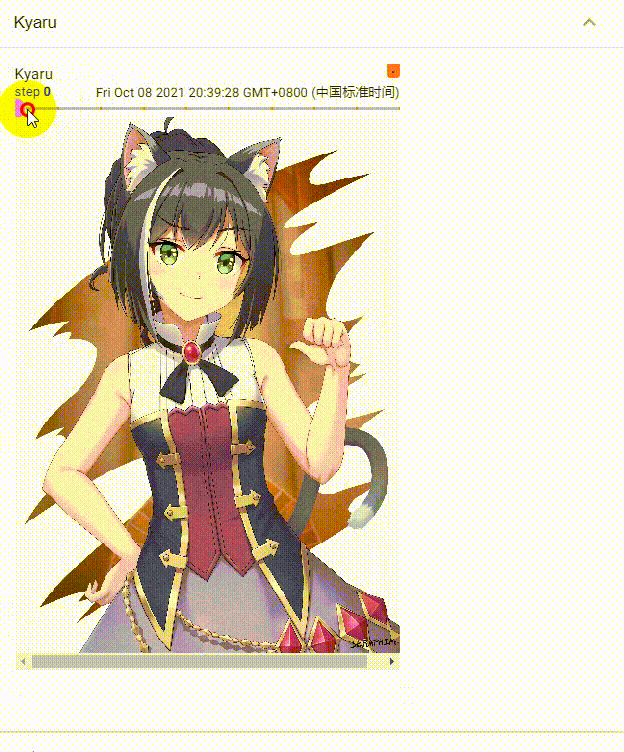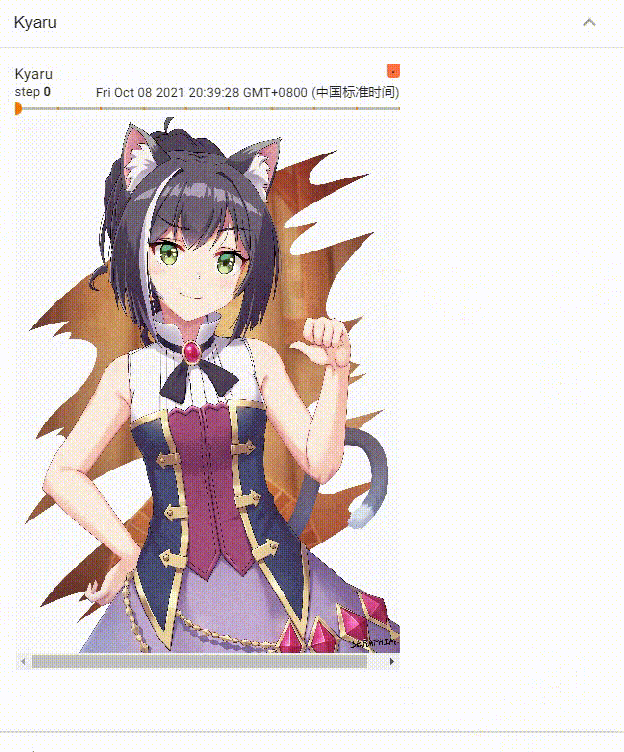
单个step效果展示

GRAPHS
使用add_graph来可视化神经网络
add_graph(model, input_to_model=None, verbose=False, **kwargs)
- model:torch.nn.Module。需要可视化的网络模型
- input_to_model:torch.Tensor或其列表,默认为
None。输入神经网络的变量或一组变量 - verbose:布尔,默认为
False。是否为信息详细模式。
下面将使用LeNet作为样例来可视化神经网络:
import torch
from torch.utils.tensorboard import SummaryWriter
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 维输入图像通道,6 维输出通道
# 卷积核为 5x5 的卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
# 6 维输入图像通道,16 维输出通道
# 卷积核为 5x5 的卷积核
self.conv2 = nn.Conv2d(6, 16, 5)
# 最后的三层全连接
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 用 2x2 的窗口对第一层卷积进行 Max pooling池化操作
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 对第二层卷积进行同样操作
# 如果池化窗口形状为正方形,可以只输入一个数
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# 将 x 打平成一维向量
x = x.view(-1, self.num_flot_features(x))
# 全连接层的前向传播
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flot_features(self, x):
"""
计算除批次外的所有维度
用来确定打平后的维度
如 x.shape = [100, 28, 28]
返回值为 28 * 28
:param x: 数据
:return: 除第一维外的所有维度之积
"""
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
writer = SummaryWriter(comment="graph")
input_ = torch.randn(1, 1, 32, 32)
writer.add_graph(
model=net,
input_to_model=input_
)
writer.close()
输出结果:

注意:input_to_model需要传入模型的合法输入,若不输入则会报错。
HISTOGRAMS
使用add_histogram记录一组数据的直方图。
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
- tag:字符串。数据名称。
- values:torch.Tensor,numpy.array 或 string。用来构建直方图的数据。
- global_step:整形,可选。训练的step
- walltime:浮点型,可选。默认为
time.time() - max_bins:整形,可选。最大分桶数。
示例:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter(log_dir="runs/histogram1")
writer.add_histogram('histogram1', np.random.normal(0, 1, 1000))
writer.add_histogram('histogram1', np.random.normal(0, 2, 1000))
writer.add_histogram('histogram1', np.random.normal(0, 3, 1000))
writer.close()
writer = SummaryWriter(log_dir="runs/histogram2")
writer.add_histogram('histogram2', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('histogram2', np.random.normal(0, 2, 1000), global_step=2)
writer.add_histogram('histogram2', np.random.normal(0, 3, 1000), global_step=3)
writer.close()


以上就是直方图的示例,相同global_step的图像会叠加在一起,若要使图像分开显示,要设置不同的global_step。
除此之外,还能通过切换左上角的选项来实现一些其他效果。用于不同的需求。

PROJECTOR
使用add_embedding来记录数值。
add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)
- tag:字符串。数据名称。
- metadata:torch.Tensor列表 或 numpy.array。一个一维列表,。
- global_step:整形,可选。训练的step
- walltime:浮点型,可选。默认为
time.time() - dataformats:图像数据格式,默认为
'CHW',即 Channel x Height x Width,还可以是'CHW'、'HWC'或'HW'等
from torch.utils.tensorboard import SummaryWriter
import torchvision
writer = SummaryWriter('runs/embedding_example')
mnist = torchvision.datasets.MNIST('mnist', download=True)
writer.add_embedding(
mnist.train_data.reshape((-1, 28 * 28))[:100,:],
metadata=mnist.train_labels[:100],
label_img = mnist.train_data[:100,:,:].reshape((-1, 1, 28, 28)).float() / 255,
global_step=0
)

注意:有可能打开tensorboard会提示No scalar data was found。这需要在右上角将模式调整为PROJECTOR。

其他
更多详细可以参考官方文档https://tensorboardx.readthedocs.io/en/latest/tensorboard.html
本文大量参考了博客https://blog.csdn.net/bigbennyguo/article/details/87956434 ,一篇非常好的文章,让我受益匪浅。















 4549
4549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









