










panda 读取csv ,dataframe.shape
## 通过Pandas对于数据进行读取 (pandas是一个很友好的数据读取函数库)
Train_data = pd.read_csv('datalab/231784/used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('datalab/231784/used_car_testA_20200313.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)
阅读dataframe 样例
Train_data.head()
Test_data.head().append(Test_data.tail())
#查看头和尾

数据信息查看
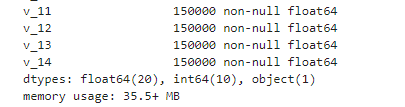
## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
Train_data.info()

 统计信息查看
统计信息查看
## 通过 .describe() 可以查看数值特征列的一些统计信息
Train_data.describe()

选择特征(列)
查看选择的列的标题名称
numerical_cols = Train_data.select_dtypes(exclude = 'object').columns
print(numerical_cols)
categorical_cols = Train_data.select_dtypes(include = 'object').columns
print(categorical_cols)

通过索引值提取dataframe里的数据
feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']]
feature_cols = [col for col in feature_cols if 'Type' not in col]
## 提前特征列,标签列构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
X_test = TestA_data[feature_cols]
print('X train shape:',X_data.shape)
print('X test shape:',X_test.shape)
填补缺失值
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)
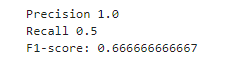
sklearn 自带评价指标
## Precision,Recall,F1-score
from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
print('Precision',metrics.precision_score(y_true, y_pred))
print('Recall',metrics.recall_score(y_true, y_pred))
print('F1-score:',metrics.f1_score(y_true, y_pred))
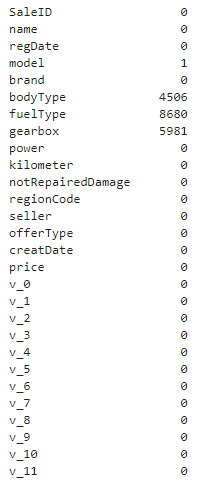
缺失值查看
## 1) 查看每列的存在nan情况
Train_data.isnull().sum()
pandas自带plot
# nan可视化
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
#索引
missing.sort_values(inplace=True)
missing.plot.bar()

缺失值可视化
import missingno as msno
# 可视化看下缺省值
msno.matrix(Test_data.sample(250))
msno.bar(Test_data.sample(1000))


替换缺失值,用replace方法
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
统计值的分布
Train_data['price'].value_counts()
对值进行处理在放到模型里
# log变换 z之后的分布较均匀,可以进行log变换进行预测,这也是预测问题常用的trick
plt.hist(np.log(Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()

。。。。
后面过多,十分繁琐,直接参照天池教程
原教程写得非常好,是数据挖掘的通用步骤
从0到1打比赛4步走














 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









