







一、分类概念

分类要找一个function函数,输入对象x的特征,输出为该对象在n个类别中的哪一个类别里。
-
例子1:信用评分【二分类问题】
- 输入:收入,储蓄,行业,年龄,信用指数……
- 输出:是否给予贷款
-
例子2:医疗诊断【多分类问题】
- 输入:当前症状,年龄,性别,既往病史……
- 输出:患了哪种疾病
二、回归模型 VS 概率模型
1、回归模型
在解决分类问题时,假设还不了解怎么做,但之前已经学过了 regression。就把分类当作回归硬解。 举一个二分类的例子,假设所分类对象的特征 x,判断属于类别1或者类别2,把这个当作回归问题。
- 类别1:相当于target是1。
- 类别2:相当于target是-1。
然后训练模型:因为是个数值,如果数值比较接近 1,就当作类别1,如果数值接近 -1,就当做类别2。

- 左图:绿色是分界线,红色叉叉就是 Class2 的类别,蓝色圈圈就是 Class1 的类别。
- 右图:紫色是分界线,红色叉叉就是Class2 的类别,蓝色圈圈就是 Class1 的类别。训练集添加有很多的距离远大于1的数据后,分界线从绿色偏移到紫色。
这样用回归的方式硬训练可能会得到紫色的这条。直观上就是将绿色的线偏移一点到紫色的时候,就能让右下角的那部分的值不是那么大了。但实际是绿色的才是比较好的,用回归硬训练并不会得到好结果。此时可以得出用回归的方式定义,对于分类问题来说是不适用的。
2、概率模型
(1)概率与分类的关系

如上图所示,假设已知红色方框的值,当我们给出一个x,就可以计算出它是属于那个类型的,
P
(
C
1
∣
x
)
\mathrm{P}\left(\mathrm{C}_{1} \mid \mathrm{x}\right)
P(C1∣x)和
P
(
C
2
∣
x
)
\mathrm{P}\left(\mathrm{C}_{2} \mid \mathrm{x}\right)
P(C2∣x),哪个类别的概率大就属于哪个类别。接下来就需要从训练集中估测红色方框中的值。因为有了这个模型,就可以生成一个 x,可以计算某个 x 出现的概率,知道了x 的分布,就可以自己产生 x 。
(2)高斯分布
高斯分布可被当作一个 function,输入就是一个向量 x,输出就是选中x的概率(实际上高斯分布不等于概率,只是和概率成正比,这里简单说成概率)。 function由期望
μ
\mu
μ和协方差矩阵
∑
\sum
∑决定。
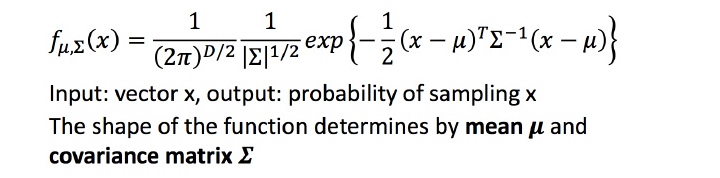
下图第一张的例子是说同样的
∑
\sum
∑,不同的
μ
\mu
μ,概率分布的最高点的位置是不同的。下图第二张的例子是同样的
μ
\mu
μ,不同的
∑
\sum
∑,概率分布的最高点是一样的,但是离散度是不一样的。


假设通过79个点估测出了期望
μ
\mu
μ和协方差矩阵
∑
\sum
∑。期望是图中的黄色点,协方差矩阵是红色的范围。现在给一个不在79个点之内的新点,用刚才估测出的期望和协方差矩阵写出高斯分布的
f
u
n
c
t
i
o
n
f
μ
,
Σ
(
x
)
function \ f_{μ,Σ}(x)
function fμ,Σ(x),然后把 xx 带进去,计算出被挑选出来的概率。

(3)最大似然估计
首先对于这79个点,任意期望和协方差矩阵构成的高斯分布,都可以生成这些点。当然,像图中左边的高斯分布生成这些点,比右边高斯分布生成这些点的几率要大。那给一个
μ
\mu
μ和
∑
\sum
∑,它生成这79个点的概率为图中的
L
(
μ
,
∑
)
L(\mu,\sum)
L(μ,∑),
L
(
μ
,
∑
)
L(\mu,\sum)
L(μ,∑) 也称为样本的似然函数。

将使得
L
(
μ
,
∑
)
L(\mu,\sum)
L(μ,∑)最大的
L
(
μ
,
∑
)
L(\mu,\sum)
L(μ,∑) 记做
(
μ
∗
,
∑
∗
)
(\mu^∗,\sum^∗)
(μ∗,∑∗),
(
μ
∗
,
∑
∗
)
(\mu^∗,\sum^∗)
(μ∗,∑∗) 就是所有
L
(
μ
,
∑
)
L(\mu,\sum)
L(μ,∑) 的 Maximum Likelihood(最大似然估计)。

直接对
L
(
μ
,
∑
)
L(\mu,\sum)
L(μ,∑)求两个偏微分,求偏微分是0的点。
(4)分类模型

根据上图,可看出我们已经得到需要计算的值了,接下来就可以进行分类了。

左上角的图中蓝色点是类别1,红色点是类别2,图中的颜色:越偏向红色代表是类别1 的可能性越高,越偏向蓝色代表是类别2的可能性越低。
右上角在训练集上进行分类的结果,红色就是 P(C1|x)P(C1|x) 大于0.5的部分,是属于类别1,相对蓝色属于类别2。右下角是放在测试集上进行分类的结果。
(5)模型优化
通常来说,不会给每个高斯分布都计算出一套不同的最大似然估计,协方差矩阵是和输入feature大小的平方成正比,所以当feature很大的时候,协方差矩阵是可以增长很快的。此时考虑到model参数过多,容易Overfitting,为了有效减少参数,给描述这两个类别的高斯分布相同的协方差矩阵。如下图所示。


根据模型优化得到右图新的结果,分类的boundary是线性的,所以也将这种分类叫做 linear model。如果考虑所有的属性,发现正确率提高到了73%。
三、概率模型-建模三部曲
实际做的就是要找一个概率分布模型,可以最大化产生data的likelihood。

后验概率
将 P(C1|x)整理,得到一个 σ(z),这叫做Sigmoid function。

数学推导:

根据
∑
1
\sum_1
∑1等于
∑
2
\sum_2
∑2等于
∑
\sum
∑,化简得到:
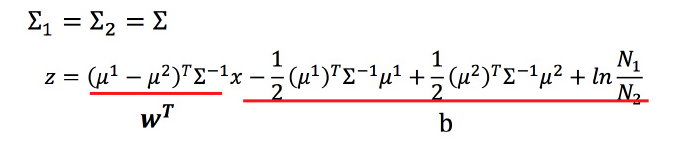
最终得到:
P
(
C
1
∣
x
)
=
σ
(
w
⋅
x
+
b
)
P
(
C
1
∣
x
)
=
σ
(
w
⋅
x
+
b
)
P(C 1 \mid x)=\sigma(w \cdot x+b) P(C 1 \mid x)=\sigma(w \cdot x+b)
P(C1∣x)=σ(w⋅x+b)P(C1∣x)=σ(w⋅x+b)
从这个式子也可以看出上述当共用协方差矩阵的时候,为什么分界线是线性的。















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









