







🌻 回归问题和分类问题区别与联系
①回归问题通常用来预测一个值,其输出的y是连续值。如预测房价、未来的天气情况等等。回归可以看作是对真实值的一种逼近预测。
②分类问题是用于将事物打上一个标签,其输出的y通常为离散值。如判断一幅图片上的动物是一只猫还是一只狗。分类并没有逼近的概念,最终正确结果只有一个,是猫或者是狗。而且分类的问题输出的维度有限,但是回归问题输出的维度原则上无限。
(一)分类问题概念
-
分类问题:要找一个函数,输入对象的特征,输出是该对象属于 n个类别中的哪一个
-
分类案例
 | 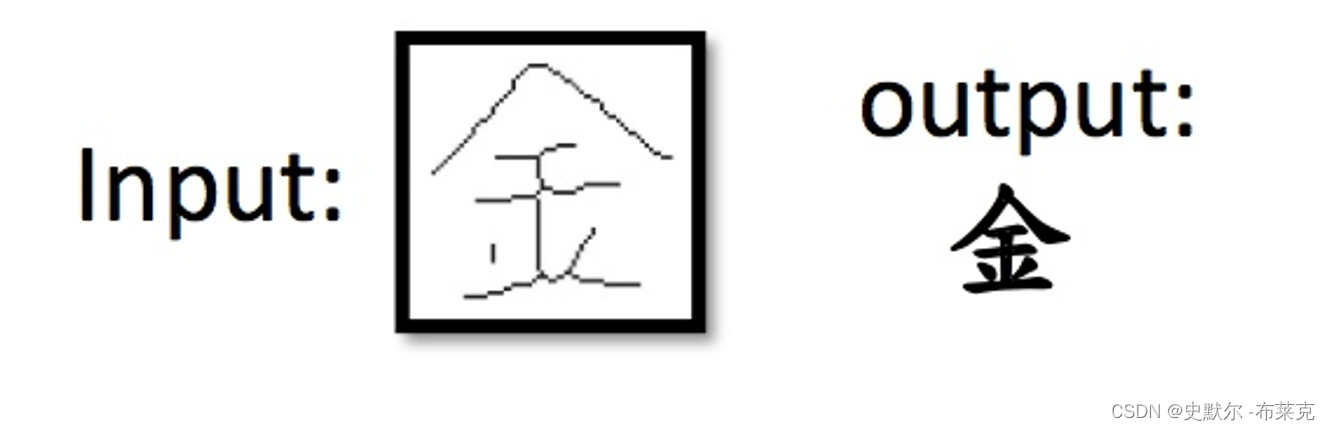 |
(二)分类方法:回归模型&概率模型
1.回归模型
我们之前只学了回归,我们现在就用回归硬解
举例 🌰:利用回归中的多元线性模型 ,
是输入的特征,y是结果(如果是1类别y=1;如果是2类别y=-1);然后求让损失函数最小的
得到了函数 ;输入待测的值然后得到如果输出比较接近 1,就当作类别1,如果数值接近 −1,就当做类别2⇒相当于用零做分界线(生成的函数如下图所示)
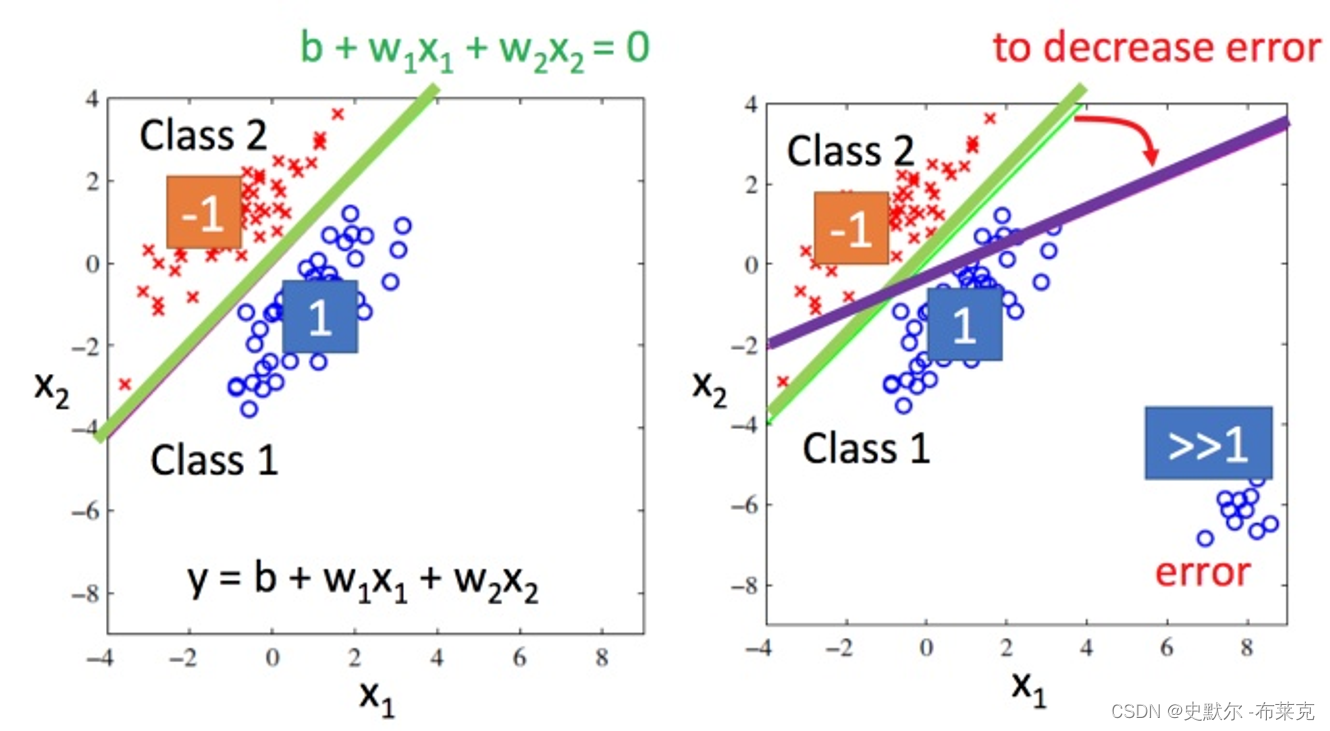
💚 回归模型用于分类时的问题:
①回归模型在(上面右图)有远离的值的时候对于模型(函数)的影响非常大,实际上绿色的才是比较好的效果。
②还有一个问题:比如多分类,类别1当作target1(值为1),类别2当作target2(值为2),类别3当作target3(值为3)…如果这样做的话,就会认为类别2和类别3是比较接近的,误认为它们是有某种关系的;其实并不存在这种联系.
2.概率模型
1.引入
首先我们来看一个概率学的问题
| 直观理解就是求解我抽到了蓝球,这个球是来自B1的概率=我选择B1的概率P(B1),又在B1里抽了个篮球的概率P(Blue∣B1),除以我抽到篮球的情况的总共的概率和(从B1里抽到篮球和从B2里抽到篮球的概率和P(Blue∣B1)P(B1)+P(Blue∣B2)P(B2)) | 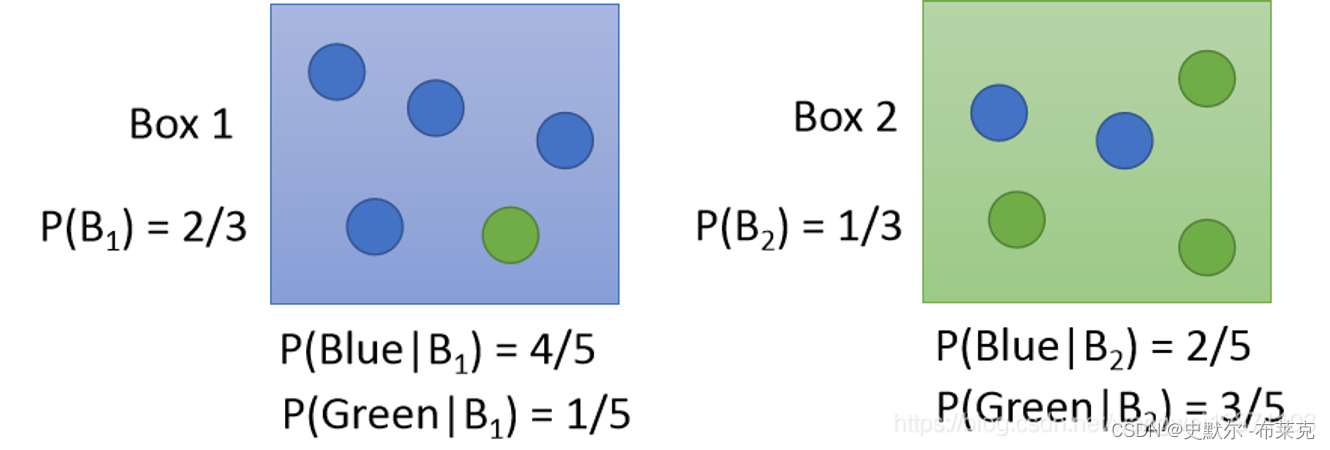 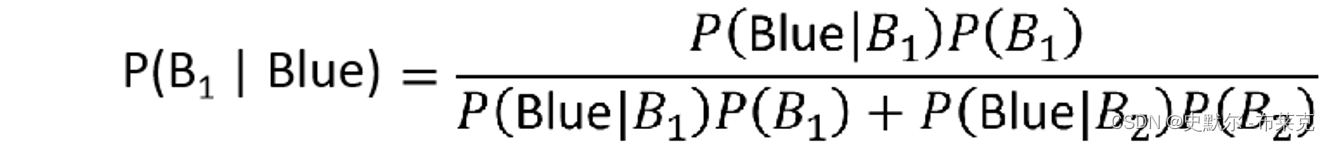 |
| 推广到二分类: 某个样本出现的概率可以是所有类别产生的概率的和,如果我们知道所有的样本出现的概率,我们就知道了这个样本的分布,那我们就可以用这个分布进行采样,产生样本,这个就叫做生成模型。 我们可以求得给定任意的x,是来自分类C1的概率 |  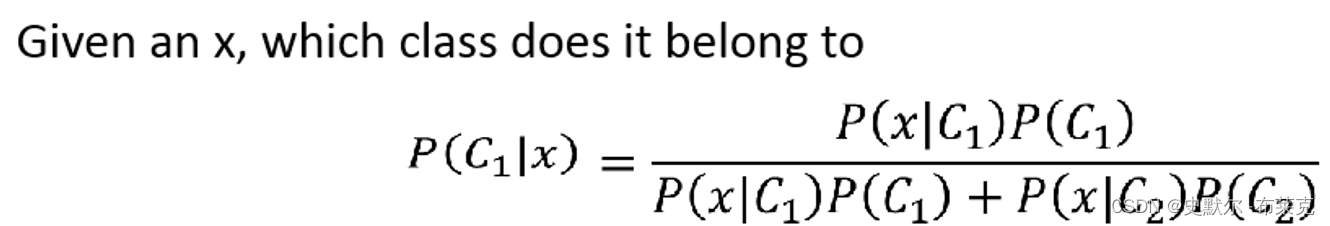 |
2.详细步骤
 3. 💚重要的思考与总结
3. 💚重要的思考与总结

总结:


















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









