







【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
本文依据蘑菇的一些特征参数,使用SVM训练模型,用于检测蘑菇是否有毒( p )或者可以吃(e). 为两个类别的分类问题。
目录
1. 导入并查看数据
关注GZH:阿旭算法与机器学习,回复:“ML34”即可获取本文数据集、源码与项目文档
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 导入数据
mush_df = pd.read_csv('mushrooms.csv')
mush_df.head()
| class | cap-shape | cap-surface | cap-color | bruises | odor | gill-attachment | gill-spacing | gill-size | gill-color | ... | stalk-surface-below-ring | stalk-color-above-ring | stalk-color-below-ring | veil-type | veil-color | ring-number | ring-type | spore-print-color | population | habitat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | p | x | s | n | t | p | f | c | n | k | ... | s | w | w | p | w | o | p | k | s | u |
| 1 | e | x | s | y | t | a | f | c | b | k | ... | s | w | w | p | w | o | p | n | n | g |
| 2 | e | b | s | w | t | l | f | c | b | n | ... | s | w | w | p | w | o | p | n | n | m |
| 3 | p | x | y | w | t | p | f | c | n | n | ... | s | w | w | p | w | o | p | k | s | u |
| 4 | e | x | s | g | f | n | f | w | b | k | ... | s | w | w | p | w | o | e | n | a | g |
5 rows × 23 columns
每个特征的含义如下:
- cap-shape: bell=b,conical=c,convex=x,flat=f, knobbed=k,sunken=s
- cap-surface: fibrous=f,grooves=g,scaly=y,smooth=s
- cap-color: brown=n,buff=b,cinnamon=c,gray=g,green=r, pink=p,purple=u,red=e,white=w,yellow=y
- bruises?: bruises=t,no=f
- odor: almond=a,anise=l,creosote=c,fishy=y,foul=f, musty=m,none=n,pungent=p,spicy=s
- gill-attachment: attached=a,descending=d,free=f,notched=n
- gill-spacing: close=c,crowded=w,distant=d
- gill-size: broad=b,narrow=n
- gill-color: black=k,brown=n,buff=b,chocolate=h,gray=g, green=r,orange=o,pink=p,purple=u,red=e, white=w,yellow=y
- stalk-shape: enlarging=e,tapering=t
- stalk-root: bulbous=b,club=c,cup=u,equal=e, rhizomorphs=z,rooted=r,missing=?
- stalk-surface-above-ring: fibrous=f,scaly=y,silky=k,smooth=s
- stalk-surface-below-ring: fibrous=f,scaly=y,silky=k,smooth=s
- stalk-color-above-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o, pink=p,red=e,white=w,yellow=y
- stalk-color-below-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o, pink=p,red=e,white=w,yellow=y
- veil-type: partial=p,universal=u
- veil-color: brown=n,orange=o,white=w,yellow=y
- ring-number: none=n,one=o,two=t
- ring-type: cobwebby=c,evanescent=e,flaring=f,large=l, none=n,pendant=p,sheathing=s,zone=z
- spore-print-color: black=k,brown=n,buff=b,chocolate=h,green=r, orange=o,purple=u,white=w,yellow=y
- population: abundant=a,clustered=c,numerous=n, scattered=s,several=v,solitary=y
- habitat: grasses=g,leaves=l,meadows=m,paths=p, urban=u,waste=w,woods=d
- class:表示分类,p有毒,e没毒
1.1 将特征转为One-Hot编码
# 将值从字母转换为数字-onehot编码
mush_df_encoded = pd.get_dummies(mush_df)
mush_df_encoded.head()
| class_e | class_p | cap-shape_b | cap-shape_c | cap-shape_f | cap-shape_k | cap-shape_s | cap-shape_x | cap-surface_f | cap-surface_g | ... | population_s | population_v | population_y | habitat_d | habitat_g | habitat_l | habitat_m | habitat_p | habitat_u | habitat_w | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
5 rows × 119 columns
1.2 分离特征数据与标签数据
# 将特征和类别标签分布赋值给 X 和 y
X_mush = mush_df_encoded.iloc[:,2:]
y_mush = mush_df_encoded.iloc[:,1] #0表示没毒,1表示有毒
2. 训练SVM模型
建立pipeline训练管道
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
# 先进行特征降维,然后再建立模型
pca = PCA(n_components=0.9, whiten=True, random_state=42) # 保证降维后的数据保持90%的信息
svc = SVC(kernel='linear', class_weight='balanced')
model = make_pipeline(pca, svc)
将数据分为训练和测试数据
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(X_mush, y_mush,random_state=41)
调参:通过交叉验证寻找最佳的 C (控制间隔的大小)
from sklearn.model_selection import GridSearchCV
param_grid = {'svc__C': [1, 5, 10, 50]}
grid = GridSearchCV(model, param_grid)
%time grid.fit(Xtrain, ytrain)
print(grid.best_params_)
Wall time: 11.3 s
{'svc__C': 50}
使用训练好的SVM做预测
model = grid.best_estimator_
yfit = model.predict(Xtest)
生成性能报告
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, Xtest, yfit, cv=5)
print(scores.mean())
0.9965517241379309
from sklearn.metrics import classification_report
print(classification_report(ytest, yfit,
target_names=['p','e']))
precision recall f1-score support
p 1.00 1.00 1.00 1047
e 1.00 0.99 1.00 984
accuracy 1.00 2031
macro avg 1.00 1.00 1.00 2031
weighted avg 1.00 1.00 1.00 2031
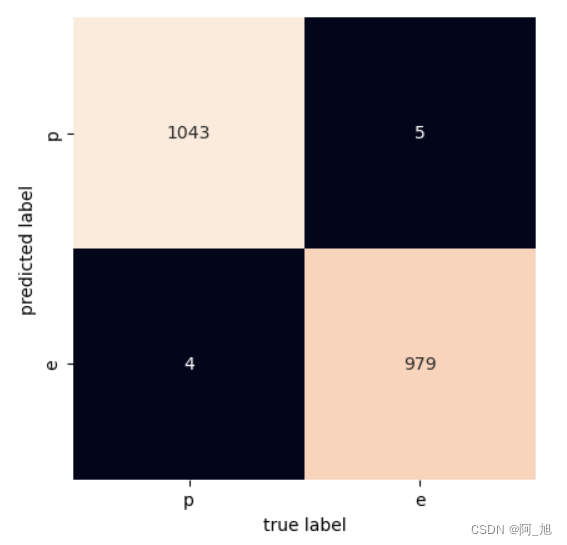
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(ytest, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=['p','e'],
yticklabels=['p','e'])
plt.xlabel('true label')
plt.ylabel('predicted label')
Text(113.9222222222222, 0.5, 'predicted label')
如果文章对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,回复:“ML34”即可获取本文数据集、源码与项目文档,欢迎共同学习交流


















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











