







前言
sliced就是投影,sliced wasserstein由于计算成本小,可作为差异度量指导特征生成器和分类器的优化。
本文可分为三步:
- 在有标记的源域上训练生成器G,两个分类器C1,C2。
- 固定G,在目标域上训练C1,C2最大化SWD,为了找到在特定任务决策边界支持之外的目标样本,由计算W1(p1,p2)转化为计算SWD:
1)首先得到目标域样本在C1,C2上的输出p1,p2。
2)从单位球Sd-1取样θ1,θ2,…,θm,在每个θ上得到投影的N个目标域样本,将每个θm上的N的样本进行排序,排序后,将Rθµα(i)赋给Rθνβ(i),可得到一维Wasserstein距离的最佳耦合,分类器输出p1和p2之间沿径向投影的1-wasserstein距离的一维变分公式(即SWD),见EQ8。 - 固定C1,C2,训练G,在目标域上最小化SWD,实现域适应。
Introduction
- 本文通过利用特定于任务的决策边界和Wasserstein度量实现领域之间的特征分布对齐。
- 提出的切片Wasserstein差异(SWD)旨在捕捉特定于任务的分类器的输出之间不相似的自然概念,SWD 直接度量目标样本与源样本的支持程度。
- 本文致力于改进在这种基于网络内对抗学习的方法中起核心作用的差异度量,本文方法旨在通过利用Wasserstein度量来最小化在特定任务分类器之间移动边际分布的成本。
3.Methods
首先在3.1节介绍无监督域自适应设置。其次,我们在第3.2节简要回顾了最优运输的概念。最后,我们在3.3节详细介绍了如何用切片Wasserstein差异训练所提出的方法。
3.1 Framework Setup
当两个数据分布Xs和Xt足够接近时,只需将注意力集中在最小化联合概率分布P(Xs, Ys)的经验风险上。
根据最大分类器差异(Maximum Classifier difference, MCD)框架,我们训练了一个特征生成器网络G和分类器网络C1和C2,它们接受从G生成的特征,并分别生成相应的logits p1(y|x)、p2(y|x)(如图1所示)。
(logits即为全连接层输出)
优化过程包括三个步骤:
(1)在源域{Xs, Ys}上训练生成器G和分类器(C1, C2)对源样本进行正确的分类:

Ls可以是任何损失函数,如交叉熵损失或均方误差损失。
(2)固定生成器G,更新分类器(C1, C2),使在目标集Xt上两个分类器输出的差异最大化,识别出任务特定决策边界支持之外的目标样本:
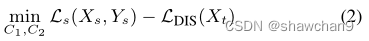
其中LDIS(Xt)为差异损失。
在此步骤中还加入Ls(Xs, Ys)以保留源域信息。
(3)冻结两个分类器的参数并更新生成器G,使两个分类器在目标集Xt上的输出差异最小化:

这一步使目标域特征簇更接近源域。
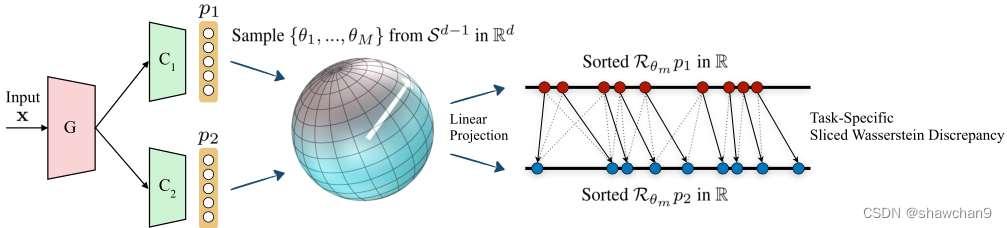
图1:提出的切片Wasserstein差异(SWD)计算的说明。SWD的设计目的是在任务特定分类器C1和C2之间捕获Rd(d维空间)中概率度量p1和p2的不相似性。SWD通过在单位球Sd−1上的均匀度量上使用径向投影的Wasserstein度量的变分公式直接实现端到端训练,为检测远离源支持的目标样本提供了具有几何意义的指导。详情请参阅第3.3节。
3.2. Optimal Transport and Wasserstein Distance
在上述MCD框架中,域自适应的有效性完全取决于差异损失的可靠性。没有差异损失的学习,本质上是去掉训练过程中的第2步和第3步,只是在源域上进行监督学习。
设Ω为概率空间,µ,ν为P(Ω)中的两个概率测度,Monge问题寻求代价最小的输运图T: Ω→Ω
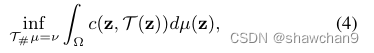
其中T# µ= ν表示从µ到ν的一对一推进,∀Borel子集A⊂Ω, c: Ω × Ω→R+是一个geodesic度量,可以是线性的,也可以是二次的。
Kantorovitch提出了公式4的一个松弛版本,它寻求一个联合概率分布γ∈P(Ω × Ω)的运输方案,使得:
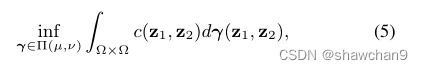
其中Π(µ,ν)={ γ∈P(Ω×Ω) | π1 # γ=µ,π2 # γ=ν}和π1和π2表示Ω×Ω到Ω的两个边缘投影。解 γ* 称为最优传输计划或最优耦合。
当q≥1时,P(Ω)中µ与v之间的q- wasserstein距离定义为
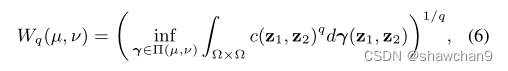
这是由最优运输计划引起的最小成本。在我们的方法中,我们使用1-Wasserstein距离,也称为earth mover距离(EMD)。
3.3. Learning with Sliced Wasserstein Discrepancy

为了充分利用两方面的优势——结合Wasserstein差异利用特定任务的决策边界来对齐源和目标的分布,我们提出通过使用切片Wasserstein差异将W1(p1, p2)集成到我们的框架中,分类器输出p1和p2之间沿径向投影的1-Wasserstein距离的一维变分公式。
我们将切片1-Wasserstein差异(SWD)定义为
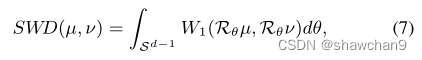
其中Rθ表示概率测度µ或ν上的一维线性投影运算,θ是Rd中单位球Sd−1上的均匀测度,使得积分Sd−1 dθ = 1。这样,计算切片Wasserstein差异等价于求解几个具有封闭解的一维最优输运问题。
具体而言,设α和β为N个样本的N个一维线性投影排列,使∀0≤i<N−1, Rθµα(i) ≤ Rθµα(i+1) 和 Rθνβ(i) ≤ Rθνβ(i+1) ,利用排序算法将Rθµα(i)赋给Rθνβ(i),可得到使这种一维Wasserstein距离最小的最佳耦合γ* 。对于离散概率度量,我们的SWD可以写成:
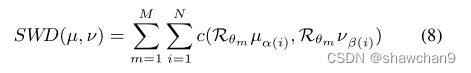
M为随机抽样θ,c为二次损失。我们提出的SWD本质上是原始Wasserstein距离的变分版本,但计算成本低很多。

















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









