







前言
本文的目标是在未配对的数据集上训练生成目标域风格的源域图片G(x);同时也要翻转过来,生成源域风格的目标域图片F(y),比如 相片到莫奈风格绘画。
目标函数由三部分组成:
- 基于对抗的源域到目标域GAN损失函数
- 同样,基于对抗的目标域到源域GAN损失函数
- 循环一致性损失函数用于正则化映射,提高泛化能力,衡量F(G(x))与x的差异和G(F(y))与y的差异,这一步我理解为确保模型正常工作,防止过拟合。
为什么选择PatchGAN?(马尔可夫判别器)
为了能更好得对图像的局部做判断,作者提出PatchGAN的结构,也就是说把图像等分成patch,分别判断每个Patch的真假,最后再取平均!作者最后说,文章提出的这个PatchGAN可以看成所以另一种形式的纹理损失或样式损失。在具体实验时,不同尺寸的patch,最后发现70x70的尺寸比较合适。
Introduction

图1.给定任意两个无序图像集合X和Y,我们的算法学会自动将图像从一个“翻译”到另一个,反之一样。(左)来自Flickr的莫奈绘画和风景照片;(中)来自ImageNet的斑马和马;(右)来自Flickr的公园夏季和冬季照片。示例应用(底端):使用一组著名艺术家的画作,我们的方法学习将自然照片渲染成各自的风格。
本文提出了一种在缺乏训练集对齐图像对示例的情况下学习将图像从源域X转换到目标域Y的方法。目标是学习一个映射G: X→Y,使得来自G(X)的图像分布与使用对抗损失的分布Y难以区分。
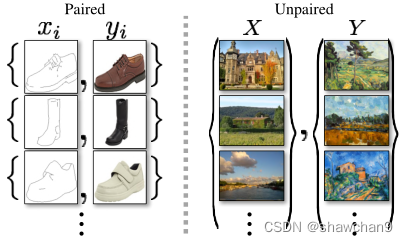
图2.成对训练数据(左)由训练样例{xi, yi}N i=1组成,其中xi和yi之间存在对应关系。相反,我们采用未配对的训练数据(右),由源集{xi}N i=1 (xi∈X)和目标集{yj}M j=1 (yj∈Y)组成,不提供关于哪个xi匹配哪个yj的信息。
我们有一个转化器G: X→Y和另一个转化器F: Y→X,那么G和F应该是彼此的逆。利用循环一致性损失,使得F (G(x))≈x和G(F (y))≈y。
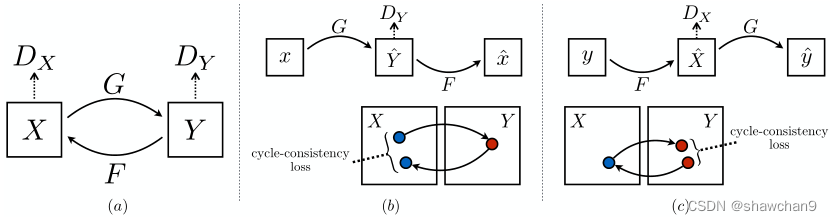
图3:(a)我们的模型包含两个映射函数G: X→Y和F: Y→X,以及相关的对抗判别器DY和DX。DY促进G将X转换为与Y域无法区分的输出,对于DX和F也是一样的。为了进一步正则化映射(提高泛化能力),我们引入了两个周期一致性损失,从而想到了这样的想法:如果我们从一个域转换到另一个域,然后再转换回来,我们应该到达我们开始的地方:(b)正向周期一致性损失:x→G(x)→F (G(x))≈x,以及©反向周期一致性损失:y→F (y)→G(F (y))≈y。
Formulation
本文目标包含两项:
1)对抗损失,用于将生成的图像分布与目标域中的数据分布匹配。
2)循环一致性损失,防止学习到的映射G和F相互矛盾。
Adversarial Loss
对于映射函数G: X→Y及其鉴别器DY,表示为:
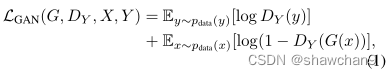
鉴别器D将真实分布Y判定为1,生成数据判定为0.
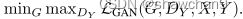
生成器F:Y->X同理:
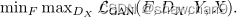
Cycle Consistency Loss
正向循环一致性:x→G(x)→F (G(x))≈x;反向循环一致性:y→F (y)→G(F (y))≈y。
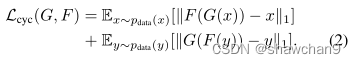

图4:输入图像x,输出图像G(x)和各种实验的重建图像F (G(x))。从上到下:照片↔塞尚,马↔斑马,冬季→夏季Yosemite公园,航空照片↔谷歌地图。
Full Objective
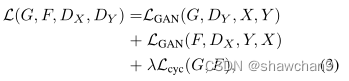
其中λ控制了两个目标的相对重要性,设λ=10。我们的目标是解决:
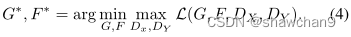
实施细节
对于LGAN(公式1),我们将负对数似然目标替换为最小二乘损失。这种损失在训练过程中更加稳定,并产生更高质量的结果。
对于GAN损失LGAN(G, D, X, Y),我们训练G最小化Ex∼pdata(X)[(D(G(X))−1)^2 ], 训练D最小化 Ey∼pdata(Y)[ (D(Y)−1) ^2 ]+ Ex∼pdata(X)[D(G(X))^2 ]。
对于绘画→照片,我们发现引入一个额外的损失来使得映射保留输入和输出图像之间的颜色构成。当提供目标域的真实样本作为生成器的输入时,将生成器正则化到接近恒等映射:即L identity(G, F) = Ey∼pdata(y)[||G(y)−y||1] + Ex∼pdata(x)[||F(x)−x||1]。

图9.一致性映射损失L identity对莫奈绘画→照片的影响。L identity有助于保存输入绘画的颜色。
如果没有Lidentity,生成器G和F可以在不需要的时候随意地改变输入图像的色调。
L identity(G, F) = Ey∼pdata(y)[||G(y)−y||1] + Ex∼pdata(x)[||F (x)−x||1]














 4559
4559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









