







前言
- 第一步为目标域样本分配伪标签,根据目标域样本与源域中心的距离得到类概率,对每个样本的最大类概率求均值得到阈值,若样本最大类概率大于阈值,则为可见集;反之,为不可见集,同时也得到了可见集目标域样本的伪标签;再根据目标域可信样本更新类中心。根据kmeans算法肘部法则得到不可见样本的类别数K,目标域样本总的类个数为Ks+K
- 保持结构的部分对齐。根据目标域同一类别样本求均值得到Ks+K个类的类原型,分别对源域和目标域样本设置一个损失函数,最小化源域(目标域)样本和对应的类的类中心的距离,同时最大化样本与其他类中心的距离,得到一个特征空间z,从而对齐源和目标域,实现域适应。
- 使用可视化结构进行属性传播,目的是通过视觉-语义映射GA恢复不可见集样本语义属性,此处公式我感觉是种固定用法。语义属性ai的每个维度表示一个特定的语义特征,利用源域和目标域可见集样本进行训练更新GA
- 4.利用视觉-语义联合特征训练分类器C(分为K+1个类)和二项分类器D(分为可见或不可见)
Introduction
本文定义了语义恢复开集域自适应(SR-OSDA)问题,SR-OSDA旨在通过从辅助源数据中恢复语义属性来发现新的目标类:在源数据的指导下学习视觉特征和语义属性之间的关系,这些关系可以传输到目标数据,并可解释性地发现不可见的类。
框架概述
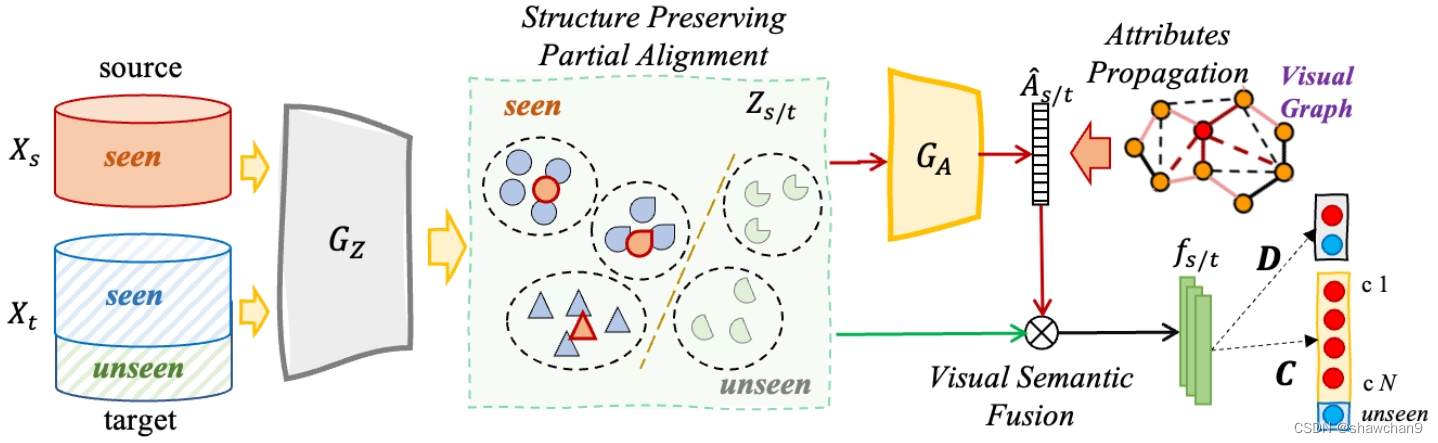
图1.对提出的框架进行说明:Xt包含Xs的一些看不见的类别。以卷积神经网络(如ResNet[16])为骨干,提取视觉特征Xs/t,输入GZ,通过部分对齐学习域不变特征 Zs/t。然后 GA将 Zs/t映射到语义属性 As。最后的分类任务融合了视觉-语义特征,一个是D,从目标数据中识别可见/不可见,另一个是C,将所有跨域数据识别为k +1个类(即k个可见+1个不可见的大类别)。
图1所示目标发现框架同时从源域中观察到的类别中识别目标域数据,并从源域中恢复未知目标类的可解释语义属性。为实现这一目标,本文设计了三个模块,分别解决了跨域移位、语义属性预测和任务驱动的开放集分类问题。
具体来说,源数据通过部分对齐适应目标域特征空间,同时保留目标结构。利用源数据和具有自信伪属性的目标数据训练连接主不变特征空间zi s/t和语义属性空间ai s/t之间的投影器GA(·)。
由于目标数据是完全无标签的,三个模块都依赖于目标域中的标签信息,我们**首先讨论了如何通过设计渐进的看见-看不见分离阶段获得目标样本的伪标签。**我们将目标样本分为Ks个可见类别和K个不可见类别,其中K可采用肘部法则。下面,我们将介绍渐进式看见-看不见分离和我们提出的框架中的三个关键模块。
渐进的看见-看不见分离
本节描述了基于视觉特征空间将目标域数据分离为可见集和不可见集的初始化策略。我们应用原型分类器来测量每个目标样本与所有源类原型[35]之间的相似性。对于每个目标样本xi t和源 Ks原型{µc|Ks c=1},概率预测定义为:
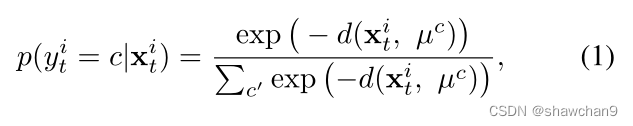
其中d(·)为距离函数,分母为对类进行遍历,采用最高概率预测pi t作为xi t的伪标签~yi t。接下来,我们采用阈值 τ 逐步将所有目标样本分为可见集Ds t和不可见集Du t。Ds t和Du t的样本数分别记为Ns t和Nu t。我们将 τ 定义为所有目标样本的最高概率预测的平均值,即:
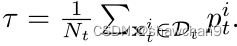
基于此,我们可以构建两个集合为:
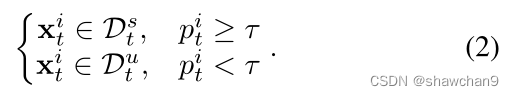
由于域偏移,只使用源域数据不能准确地识别可见集和未可见集。因此,我们可以通过加入新标记的目标样本来逐步更新可见集的原型。
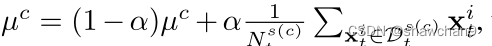
其中Ds© t表示一组自信预测为~yi t =c的目标样本, α是控制跨域原型混合的小值。
得到所见集合Ds t中的所有伪标签后,我们还需要探索Du t中更具体的知识,为此,我们采用K-means聚类算法将Du t分成K个簇,簇心为{η k1,···,η K}。这样,我们可以得到所有可见类别和不可见类别的原型Rx={μ1,···,µKs,η k1,···,η K}。
结构保持部分对齐
考虑到我们的目标是揭示目标领域中不可见的类别,那么保存目标领域数据的结构知识就变得更加重要。因此,我们不是将源数据和目标数据映射到一个新的域不变特征空间中,而是寻求通过部分对齐将源数据与目标域分布对齐。
具体而言,借助目标域伪标签~Yt,对于伪标签空间中包含 Ks+K 个类别的每个类c,类原型可计算为特征 z空间中的类中心,即:只是针对目标数据的类原型
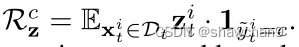
为了解决域差异,我们将每个源样本对齐到其特定的目标样本中心,并与其他目标样本中心保持距离,如下所示:这一步是对源域样本操作
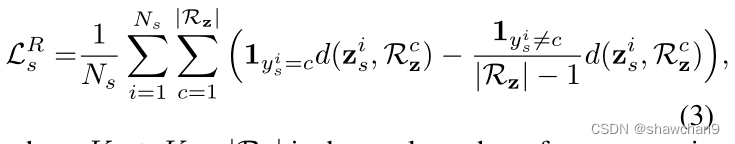
其中Ks+K=|Rz|为总的原型数量。
以下损失函数使类内目标样本更紧凑,同时使得类间目标样本更有判别力:可理解为双层循环,先对目标样本遍历,再对类别遍历,若伪标签为c,则最小化与类c原型的距离;若伪标签不为c,最大化与其他类别原型距离,这一步是对目标域样本操作
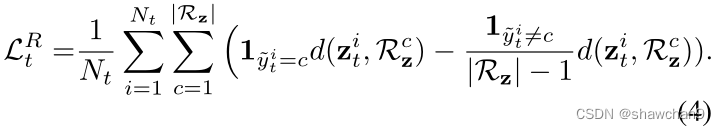
这两个损失函数有助于对齐源和目标,以获得域不变的视觉特征,并对目标样本寻求更多的判别知识。结构保持部分域适应的目标函数为LR=LR s+LR t
使用可视化结构进行属性传播
本节的目标是通过视觉语义投影 GA(·)恢复不可见的目标样本语义属性。然而,只有源域中可见类的属性知识可用于训练,而来自未见类别的目标样本则没有办法优化GA(·),这可能导致投影仪GA(·)在处理未见目标类别样本时偏向于可见类别。为此,我们提出了属性传播机制,将可视化图知识聚合为语义描述投影,有利于属性从可见类传播到不可见类。
其中,对于一个训练批次的特征zi = GZ(xi),邻接矩阵A计算为 Aij=exp(−d2 ij /σ2),其中Aii = 0,∀i, dij =||zi−zj||2为(zi, zj)的距离。σ2=Var(d2ij),σ是稳定训练的比例因子,同标准化。由视觉特征投影的属性重构为:
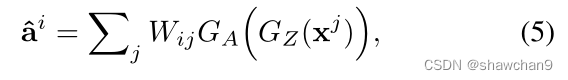
其中L = D-1/2A D-1/2,Dii=(对j求和)Aij , W=(I(单位矩阵)−βL)−1.β为固定的比例因子,D为对角矩阵。
在语义属性传播之后,在可视化图的引导下,将组件细化为相邻组件的加权组合。这有利于属性投影仪避免过度拟合到看可见的类别,同时消除不需要的噪音[32]。
在通过属性传播对投影属性进行细化后,我们在两个域的可见类别上优化属性投影GA(·)为:
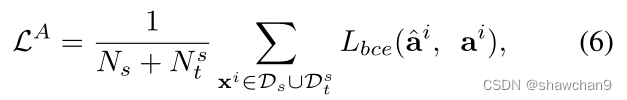
其中Lbce(·)为二元交叉熵损失。语义属性ai∈Rda的每个维度表示一个特定的语义特征,而^ai描述了输入样本具有特定特征的预测概率。
视觉-语义融合识别
为了同时利用视觉和语义描述的多模态优势,我们通过将语义判别信息ai传达到视觉特征zi中(fi=zi⊕ai)来探索视觉和语义的联合表示,fi为联合特征。
ground truth(ai),pseudo attributes(~ai),predict attributes(^ai).将三种因素都考虑在内,并将获得如下的各种联合声明:
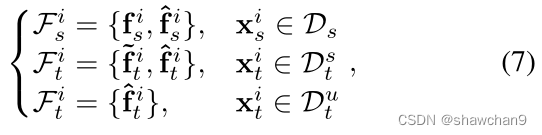
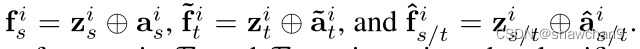
将Fs 和Ft 中的所有联合特征输入分类器C(·)和D(·),对框架进行优化。分类器C(.)的交叉熵分类损失构造为:
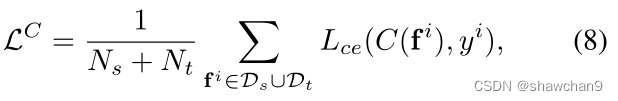
yi为Ks个源标签和Ks +1个目标标签。还训练了一个二进制分类器D(·),将目标域分为可见和不可见的子集,优化公式:
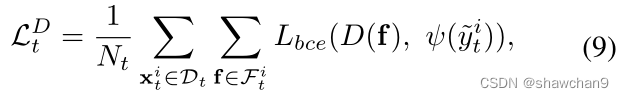
其中ψ(~yi t)表示目标样本xi t来自可见类别(ψ(~yi t) = 0, xi t∈Ds t),还是来自不可见类别(ψ(~yi t)=1, xi t∈Du t)。
然后在源域和目标域上用视觉和语义联合表示得到分类监督目标函数LT=LC+LD t。
总体目标函数
将结构保留部分自适应、语义属性传播与预测、视觉-语义表示联合识别结合起来,得到总体目标函数为:
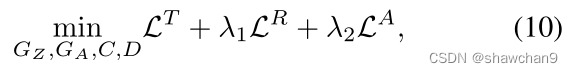
通过最小化目标,通过视觉-语义联合表示监督和属性传播,将源数据中的语义描述知识聚合到未标记的目标域。同时,跨域局部自适应促进了目标域内视觉结构的识别。















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









