







摘要:在现实的识别/分类任务中,由于受到各种客观因素的限制,在训练一个识别器或分类器摘
0.摘要:
- 原因与场景:在现实的识别/分类任务中,训练模型的时候可能并没有所有类别的训练集。因此,这样训练出来的模型在没有出现过的类出现时,一般会失效。
- 解决方案:开放集识别就是要既能识别训练集中出现过的类,也要识别训练集中没有出现过的类。
- 后面还有相关的比较:包括样本、一次样本(少样本)识别/学习技术、带有拒绝选项的分类、开放世界识别等。
————————————————
目录
1.引言:
1.1类似的学习概念还包括:
- Life-long learning终身学习(一机多能)[1],[2]:一个网络结构、方法能够胜任所有的任务,类似于Continuous Learning,Never ending Learning,Incremental Learning,Multi-task learning。
- transfer learning迁移学习[3],[4],[5]
- domain adaptation域适应[6],[7]
- zero-shot(从样本学描述,借助描述进行分类) [8],[9],[10],one-shot (few-shot) [11],[12],[13],[14],[15],[16],[17],[18],[19],[20]识别/学习(只用几个样本进行分类,用的方法是度量两个样本是否属于同一类)
- 开放集识别/分类[21],[22],[23]。
————————————————
1.2考虑不同的四种样本
前面的已知未知表示是否有标记样本(标记信息)。
后面的已知未知表示能不能说明这个类别是什么类,以及这个类长什么样(描述信息)。
- 注意:标记信息并不能标记所有样本,而描述信息可以描述所有样本。例如,我只标记了十张马的照片,但并不能标记所有马的照片,并不能说明这个类就是马了,更不能说明马都长成这些样子。但描述信息可以说明所有马的共性特点,可以说这个类是马,以及马长什么样。
- 注意:具体这个描述信息是仅仅告诉你这个类是什么(明确类),或者还包括这个类长什么样要看具体设置(明确类含义)。
- 注意:可以理解成类标记打在样本上(样本级),描述信息描述在类上(类级)。通常的分类是对样本进行分配类标记(样本级),当样本缺少类标记时,不能学习样本到类标记的映射,此时可以学习样本到描述的映射,来匹配类的描述,再根据匹配结果分配类标记。
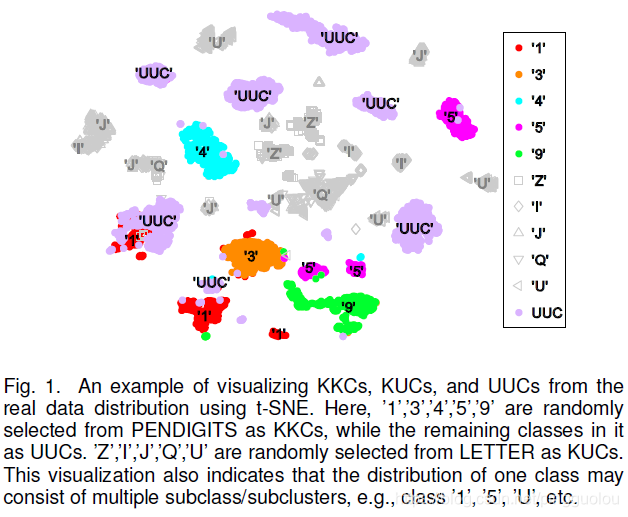
- 已知的已知类(KKCs):有类标记信息,有类别描述信息的样本;有类标记,并告诉你这个类是什么,或者还告诉你这个类都长什么样。
- 已知的未知类(KUCs):有类标记信息,无类别描述信息的样本;有类标记,但不告诉你这个类是什么,也不告诉你这个类都长什么样。
- 未知的已知类(UKCs):无类标记信息,有类别描述信息的样本;没有类标记,但告诉有这么个类,还告诉你这个类都长什么样。
- 未知的未知类(UUCs):无类标记信息,无类别描述信息的样本;没有类标记,也不告诉有什么类,更不告诉什么类都长什么样了。
————————————————
1.3这些学习概念与这四类样本的关系。
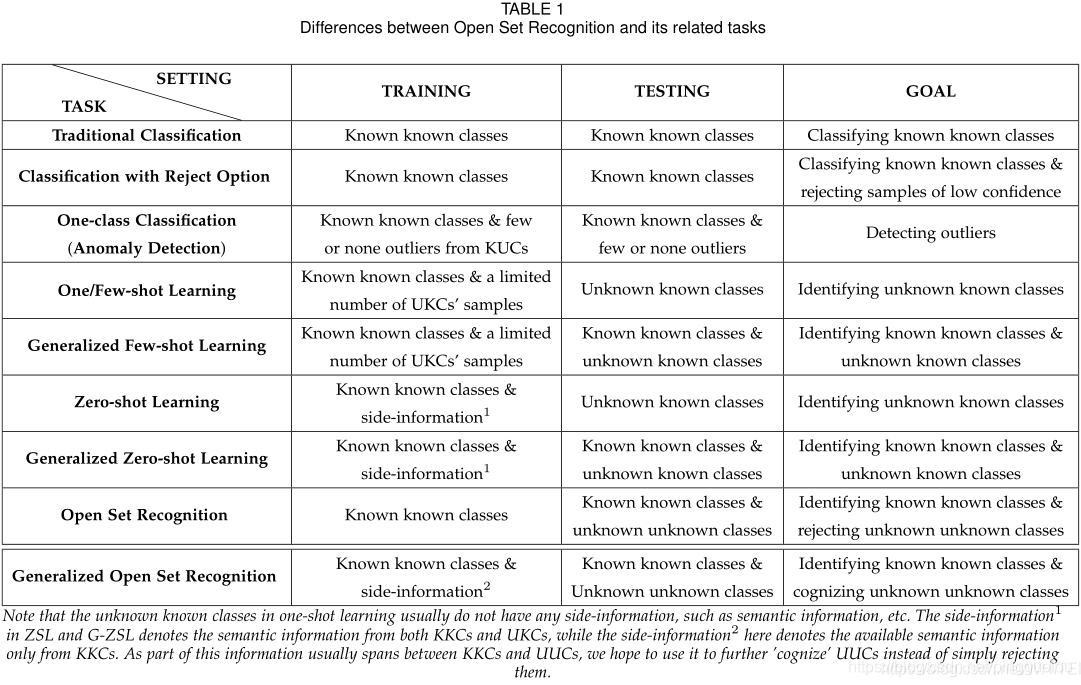
传统分类:对明确类的正常标记样本进行训练与分类。(描述信息这里只指明确类)
带拒绝选项的分类:对明确类的正常标记样本进行训练与分类,如果分类结果置信度低的话,拒绝这个分类结果,可以待人工二次判断。(描述信息这里只指明确类)
异常检测:对明确类的正常标记样本进行训练(或还包括少量没有明确类的异常样本),对有明确类的正常样本和没有明确类的异常样本进行分类。(描述信息这里只指明确类)
one/few-shot学习(参考人脸识别中的人脸比对):对明确类含义的正常标记样本进行训练,以及迁移到只有类描述的样本上训练,最后在有类描述的样本上进行分类(描述信息这里只指明确类含义)
zero-shot:对明确类含义的正常标记样本进行训练,通过学习类别描述的方式来学习分类(样本—>类别描述—>类),对具有类别描述信息的样本进行分类,期望也能通过样本—>类别描述—>类实现分类。(描述信息这里只指明确类含义)
open-set:对明确类的正常标记样本进行训练,对有明确类的正常样本和拒绝其他非明确类的样本。(描述信息这里只指明确类)
2.基本符号&相关定义
2.1开放空间风险的定义
开放空间风险即将开放空间 O(远离已知数据的未知空间)中的样本标注为已知类别带来的风险,它被形式化为开放空间 O 相对于整体测度空间![]() 的相对测度,计算如下
的相对测度,计算如下
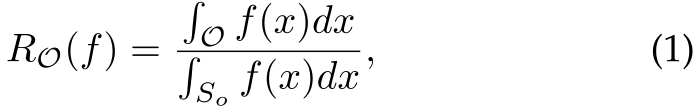
2.2开放性的定义
开放性openness 用来定义开放空间(或者说开放识别问题)的开放程度,令 、
和
分别表示:待识别类的集合、训练中使用的类的集合和测试中使用的类的集合。则对应的问题开放性O为:
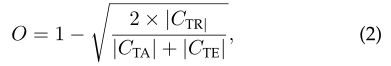
考虑到考虑以下简单的情况:,
,
,
会导致O < 0,其次,也考虑问题的开放性应该只取决于
知识和
知识,而不是
、
和
三个方面的知识。对开放性公式重新校准为:
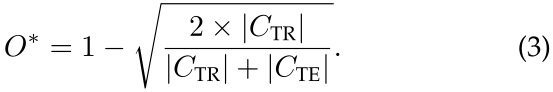
2.3开放集识别问题
开放集识别问题就是既要最小化传统的经验风险,也要最小化上面提出的开放空间风险。换句话说,开放集识别的目标就是找到一个可测量的识别函数f 来最小化以下开放集风险的(其中后一项为经验风险,V为为训练数据):![]()
3.OSR技术分类
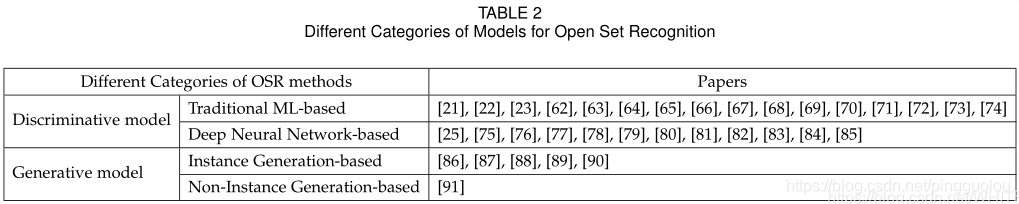
现有技术都是在一定的约束下,从判别和生成的角度对OSR建模进行了探索。 根据建模形式,这些模型可进一步分为四类(见表2):
- 基于传统ML (TML)的判别方法
- 基于深度神经网络(DNN)的判别方法
- 基于实例的生成方法
- 基于非实例的生成方法
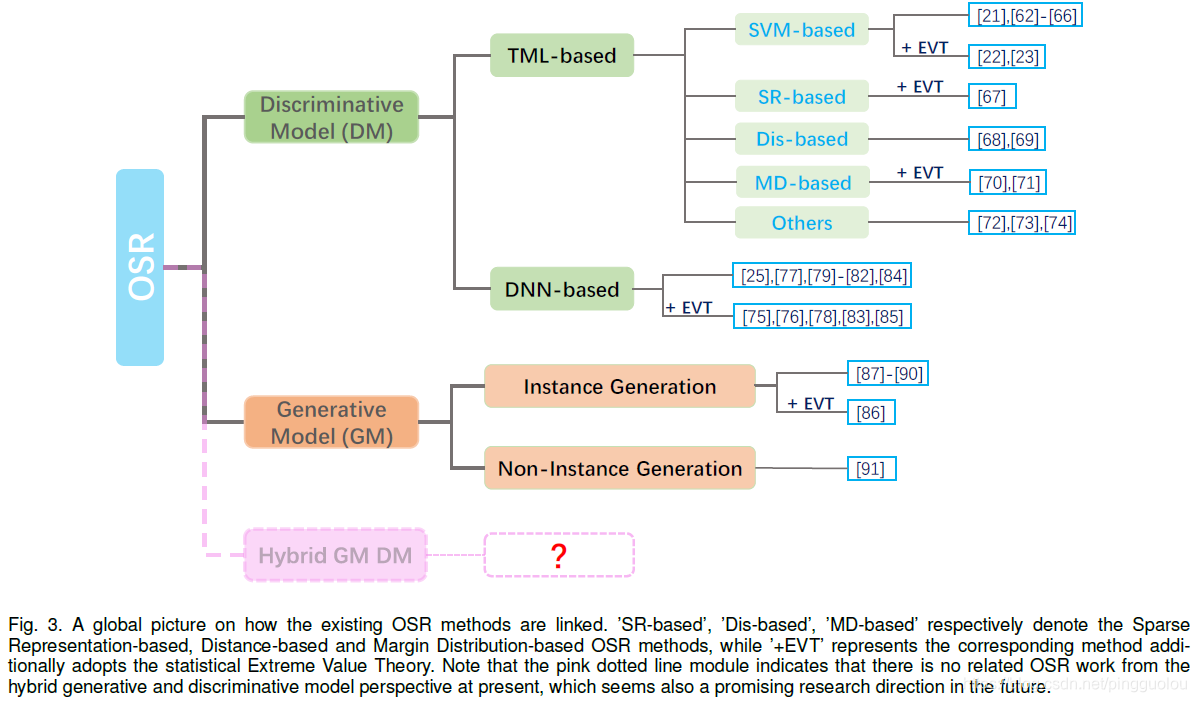
3.1基于传统ML (TML)的判别方法
3.1.1基于SVM
- Scheirer等人首先提出了1-vs-Set,该机制在建模中纳入了开放空间风险项,以解释超出KKCs合理支持范围的空间。具体来说,他们在得分空间中加入另一个与SVM得到的分离超平面相平行的超平面,从而在特征空间中形成一个一定厚度的厚片slab。线性核厚片模型的开放空间风险定义如下:
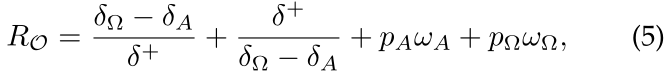 。其中
。其中 和
表示对应超平面的边缘距离,而“
”是解释所有正样本所需的间隔。用户指定参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5009
5009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









