









两个特征的样本进行线性回归,它的公式可以是简单的
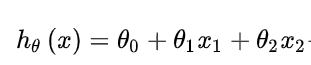
用直线分类,也可以用下图的二次、三次的组合去拟合更复杂的曲线。
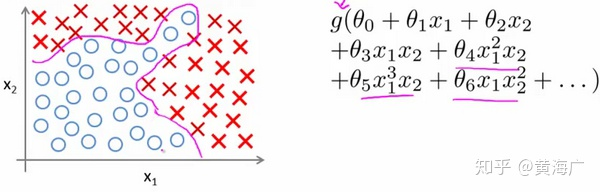
不过,如果特征变多了,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合 ![[公式]](https://img-blog.csdnimg.cn/8e5f6e221fe64b05ae7a81d64d3a0111.png)
,我们也会有接近5000个组合而成的特征。
而且,假使我们输入的都是50x50像素的小图片(而且是灰度图),并且我们将所有的像素视为特征,则会有 2500个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约2500*2500/2个(接近3百万个)特征。普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。


我啰嗦几句。
回忆一下g(x)

a1是4个x输入后经过g函数的输出,输入前的参数Θ存在第1行里,挨个取用。
输入层有多少个值决定了参数一行有多少个数,输出层的数量则是参数矩阵的行数。所以截图里的使用基本上就是矩阵的存储排列。
有多少层神经网络决定了有多少个参数矩阵。
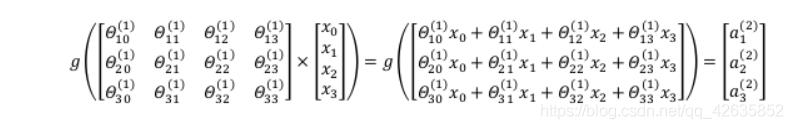
你看这里只用了一列输入,也就是一组样本,但我们要对整个训练集都算一遍,所以要多几列。
单独讲一讲神经网络的特性吧
神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)。



还能组合一下,猜一猜效果?试试看把这个写成矩阵公式
下面的图里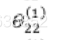 这个位置的参数错了,是-20
这个位置的参数错了,是-20

 所以,我们原本只能依靠自己采集到的样本值来试图拟合出一个合适的曲线,而如果我们有了神经网络,神经网络就会自顾自地优化我们给他的样本的特征,然后神经网络用他自己优化出来的样本值【中间层的值】去拟合函数。
所以,我们原本只能依靠自己采集到的样本值来试图拟合出一个合适的曲线,而如果我们有了神经网络,神经网络就会自顾自地优化我们给他的样本的特征,然后神经网络用他自己优化出来的样本值【中间层的值】去拟合函数。
有多个种类要分就是最终有多个输出。

好嘛,我们现在知道了输入之后会输出什么了。老流程,下一步是代价函数 评价模型质量。

再啰嗦几句给自己看。
y只有1或者0 神经网络中的yk是指第k个输出是1或是0. 而且对于每一行特征,输入都得算遍k个输出的概率值,找最大的概率值作为模型选择的输出值 再去和实际的y去比较。把k设为1的话就是上面那个普通的二元分类问题。
前面的负号只是因为log函数要反向所以带负号,实际效果仍然是输出值越靠近样本值 代价越小。
后面的是m个样本取平均,λ是防止过拟合的比例参数,n是公式中θ的数量 不包括常数项;同样的,神经网络的三个求和符号也只是为了遍历所有公式里的每个θ(排除了每一层 的常数项θ0)【L-1层,j行该层输出数量,i列该层输入数量】【大概吧】每层的Θ都有(输入数量*输出数量)那么多,但是输入层的常数项不用计算代价所以不包括,输出层的常数项属于下一层的 没有θ 所以也不包括。【好像跟公式微妙地对不上,为什么Sl+1呢。。怎么没 个例子。。】
再下一步,求偏导 找代价函数的最小值。
之前我们在计算神经网络预测结果的时候我们采用了一种正向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层的输出。现在,为了计算代价函数的偏导数 ,我们需要采用一种反向传播算法。对,反向传播算法不是什么恐怖的东西,就是跟第一篇里写的梯度下降是同样目的的东西。但是第一篇里就一条公式,哪怕是多几次方、多几个特征、多一堆样本,也只不过是一条公式,而这里每一层都是一条公式,我们如果想要从输出倒推输入就得经过所有的公式。
好了 开始
我们有了代价函数,我们需要代价函数的偏导,然后用偏导==0来获得能取得最小代价的Θ系列。
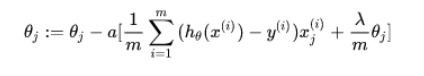 这个是普通逻辑回归求导后的梯度下降公式。
这个是普通逻辑回归求导后的梯度下降公式。
先得算出从第二层开始的每一层的误差,有了这个误差基本值才能算偏导数
假设总共四层,最后一层输出可以和样本的值相减取误差。但是第3层的误差就只能靠第四层的误差和导数来推算

如果输出值不止一个,那么每个输出都会要求倒数第二层的数要怎样怎样,那时候要给倒数第二层【以及接下来的层数】的求出的代价函数值取平均值,然后再用来算接下来的前一层。
3B1B
计算公式微妙地不一样,不过这里的比较简单【算误差的时候没有呈上S函数的导数,而且没用到代价函数啊】,可以先看看
这个讲链式法则讲得清楚
这里有个良心大佬开源了资料
备注:
















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









