






以下所言,皆是我一家之词,不足之处,还望海涵与指正,在此感谢!
一、正则表达式的作用
个人感觉,正则表达式可以匹配或获取某一段有规律的字符串。
举个小例子:
假如这是一组 数据,想获取 methodName 对应的内容,使用正则表达式就很方便
[2021-07-01 16:22:10.475] [{"result":"Y","methodName":"UserVisitorList.getLastClue", "log_time":0}]
[2021-07-01 16:22:20.006] [{"result":"Y","methodName":"BatchKafkb740c8dc.start", "log_time":0}]
[2021-07-01 16:42:20.006] [{"result":"Y","methodName":"BatchKafkb740c8dc.start", "log_time":0}]
import org.springframework.core.io.ClassPathResource;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.*;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
/**
* 读取文件内容
*/
public class FileUtils {
// 分析16:40:00之前的数据内容
public static int time = 164000;
/**
* 读取文件内容
*/
public static List<Map.Entry<String,Integer>> readFile(String path) {
ClassPathResource classPathResource = new ClassPathResource(path);
List<Map.Entry<String,Integer>> list=new ArrayList<Map.Entry<String,Integer>>();
Map<String, Integer> statisticsMap = new HashMap<String, Integer>();
try {
InputStream stream = classPathResource.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(stream, "UTF-8"));
String line;
while ((line = br.readLine()) != null) {
String regex_01 = "[0-2][0-9][:]\\d{2}[:]\\d{2}";
Pattern pattern_01 = Pattern.compile(regex_01);
// 获取 xx:xx:xx 形式的匹配内容
Matcher matcher_01 = pattern_01.matcher(line);
if (matcher_01.find()) {
char[] matchStr = matcher_01.group().toCharArray();
// 算法 将日期转化成其对应整数形式:例,将00:50:00 转化成 5000
String str = getTimeString(matchStr);
// 大于代表是16:40:00之后的日志,其之后的日志也不符合条件故直接返回
if (Integer.parseInt(str) > time) {
br.close();
stream.close();
// 将获得的结果按照value值从大到小排序
list.addAll(statisticsMap.entrySet());
FileUtils.ValueComparator vc=new ValueComparator();
Collections.sort(list,vc);
return list;
} else {
// 正则表达式
String regex_02 = "(?i)(?<=methodName\":\")[^\"]*(?=\")";
Pattern pattern_02 = Pattern.compile(regex_02);
// 直接获取 "methodName":"$value" 中的value值
Matcher matcher_02 = pattern_02.matcher(line);
// value值做HashMap 的 key, value 是 其出现次数
if (matcher_02.find()) {
// $value第一次出现,则get() == null
if (statisticsMap.get(matcher_02.group()) == null) {
statisticsMap.put(matcher_02.group(),1);
} else {
// 之后,$value 没出现一次, value + 1
statisticsMap.put(matcher_02.group(),statisticsMap.get(matcher_02.group()) + 1);
}
}
}
}
}
br.close();
stream.close();
} catch (IOException e) {
e.printStackTrace();
}
// 将获得的结果按照value值从大到小排序
list.addAll(statisticsMap.entrySet());
FileUtils.ValueComparator vc=new ValueComparator();
Collections.sort(list,vc);
return list;
}
private static String getTimeString (char[] matchStr) {
boolean flag_01 = false;
boolean flag_02 = true;
String str = "";
for (int i = 0; i < matchStr.length; i++) {
if (flag_01 && matchStr[i] != ':') {
flag_02 = false;
str += matchStr[i];
}
if (flag_02 && (matchStr[i] != '0') && (matchStr[i] != ':')) {
str += matchStr[i];
flag_01 = true;
}
}
// 这是00:00:00时的日志,不能直接转化成整数进行匹配
if (str == "") {
str = "0";
}
return str;
}
private static class ValueComparator implements Comparator<Map.Entry<String,Integer>>
{
public int compare(Map.Entry<String,Integer> m,Map.Entry<String,Integer> n)
{
return n.getValue()-m.getValue();
}
}
public static void main(String[] args) {
List<Map.Entry<String,Integer>> list = FileUtils.readFile("core-service-digest.log.2021-07-01");
Iterator<Map.Entry<String,Integer>> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
这个代码质量并不好,做项目时是有很多地方可以完善,这儿我只提一下:
1 reggex 和 pattern 可以从 while 中提出来,设置static 方法去保存或执行
2 应该在 finally 区去关闭资源
二、使用方法
上面例子已经给出了
// 构建正则表达式
String regex_01 = "[0-2][0-9][:]\\d{2}[:]\\d{2}";
// 我理解为预编译
Pattern pattern_01 = Pattern.compile(regex_01);
// 获取 xx:xx:xx 形式的匹配内容
Matcher matcher_01 = pattern_01.matcher(line);
// 检查是否有匹配的内容
if (matcher_01.find()) {
// 获取匹配的内容
matcher_01.group();
}
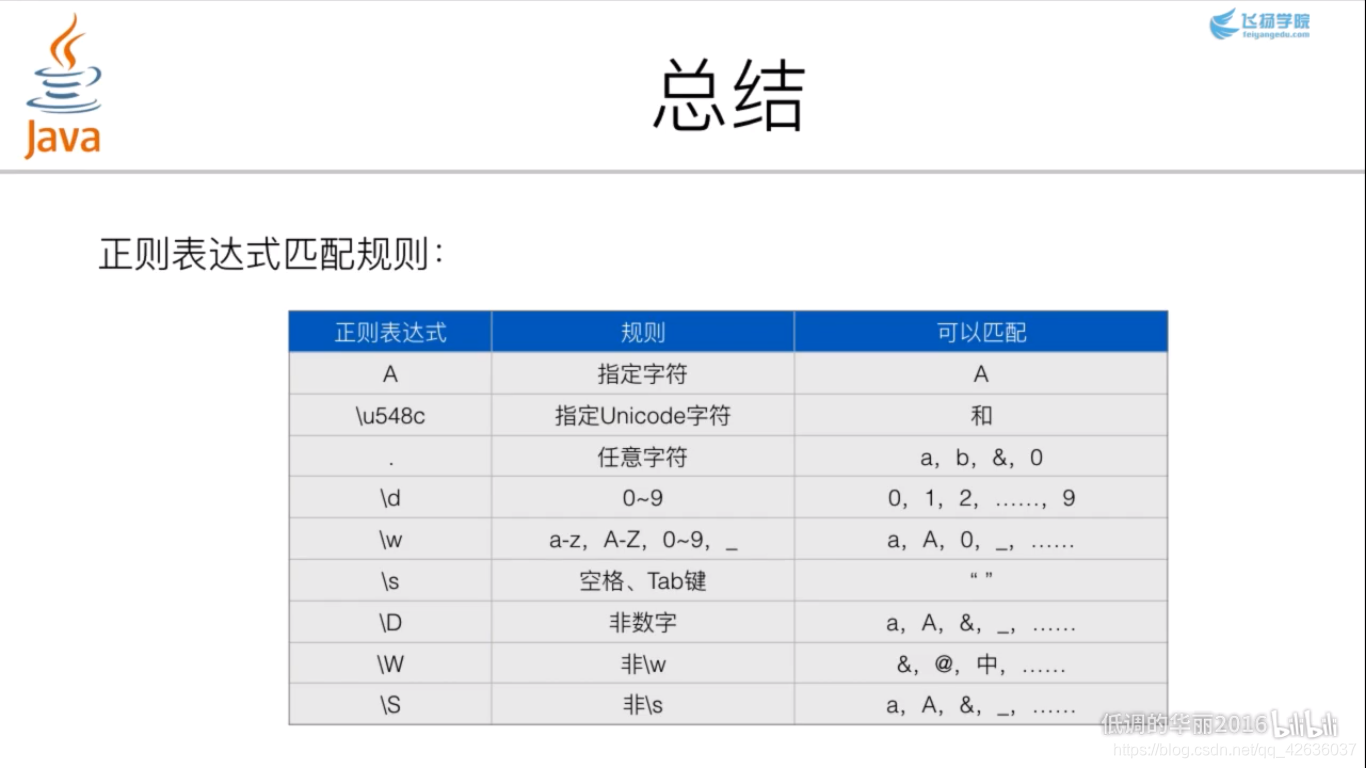
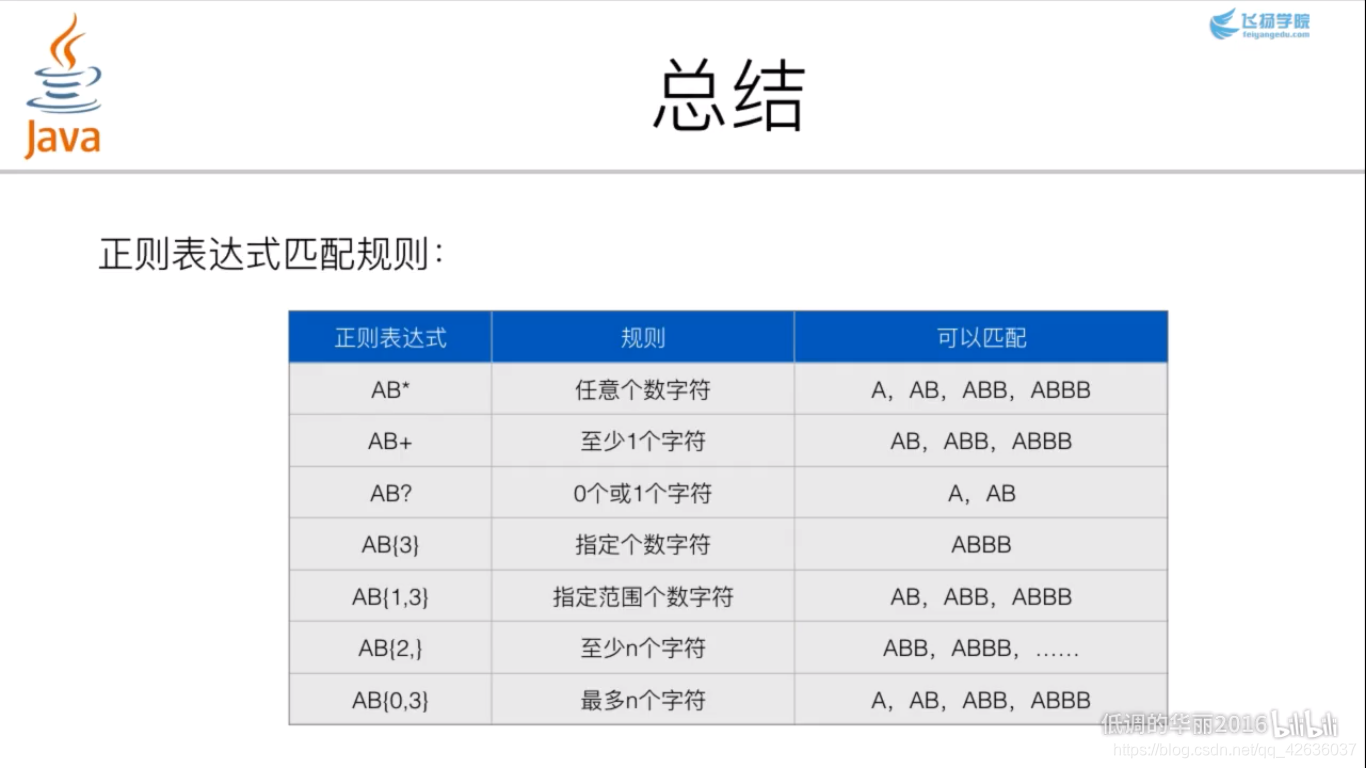
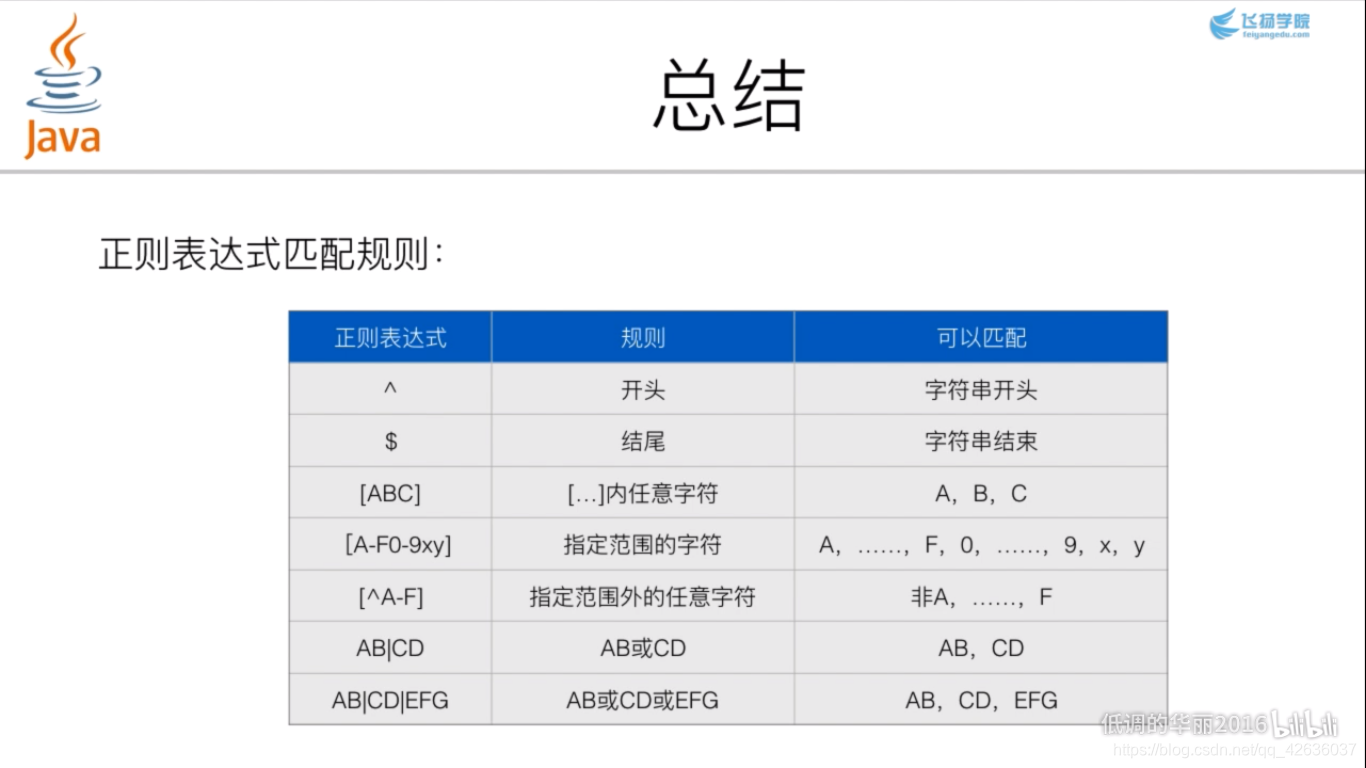
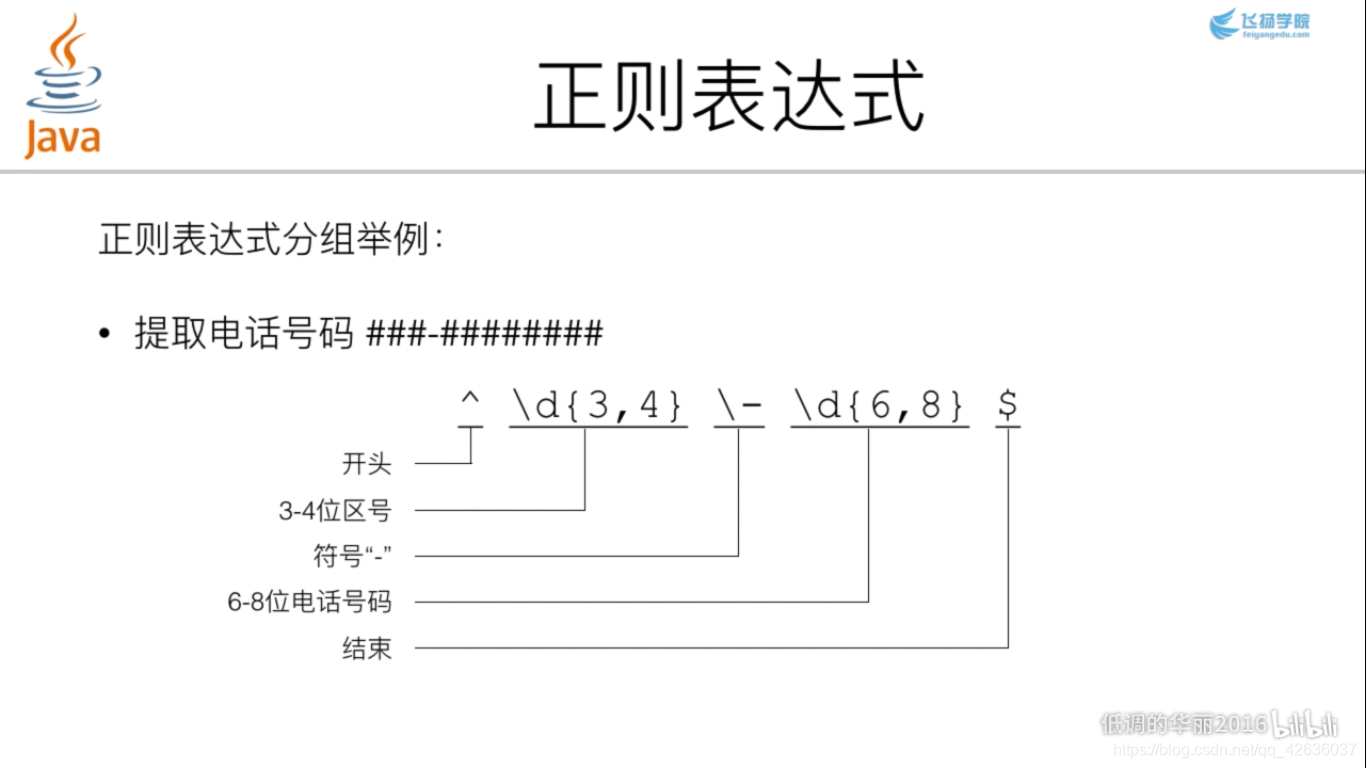
三、正则表达式的基础用法
在此,郑重感谢飞扬学院,更多更详细的内容,可以去B站搜索学习。十分钟就基本可以。这样之后用起来就很方便,也能基本看懂别人写的内容


















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









