







聚类
聚类是指将数据集的样本划分为不同的子集,这些子集互不相交,且总和为整个数据集。
一个常用的距离
- 明可夫斯基距离(Minkowski distance):是欧式距离(Euclidean distance)和曼哈顿距离(Manhattan distance) 的推广
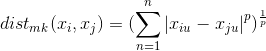
- 欧式距离(p=2时):
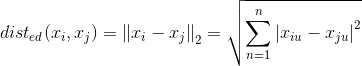
- 曼哈顿距离(p=1时):
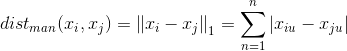
k均值算法
用了欧式距离,通过优化迭代求近似解,算法如下:

首先在数据集中随机抽取k个值作为初始均值,然后定义k个空列表用来盛放后面分好类的数据。用欧式距离考察每个向量与每个均值的距离,与哪个均值最接近就划分到哪个类中。当遍历完所有的向量后,得到一组分好的类。这时计算此时的各类的均值向量,再次重复距离考察,不断重复这个过程,直至均值向量不再更新,便认为最终分好了类别。但k-means对初值敏感,不同的初值会得到不同的结果。
实现代码:https://github.com/ethan-sui/k-means (代码很傻,仅仅实现,后期有时间会改)















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









