






 本文详细指导了如何下载ChatGLM2-6B模型及相关包,部署过程,以及在Ubuntu上测试、web界面交互和模型微调的方法。
本文详细指导了如何下载ChatGLM2-6B模型及相关包,部署过程,以及在Ubuntu上测试、web界面交互和模型微调的方法。
1.下载chatglm相关文件以及部署:
1)需要下载的文件ChatGLM2-6B
下载ChatGLM2-6B:
指令:git clone https://github.com/THUDM/ChatGLM2-6B
![]() (注:如果上面代码下载不了,请输入如下代码(git clone https://ghproxy.com/起到代理服务的作用):
(注:如果上面代码下载不了,请输入如下代码(git clone https://ghproxy.com/起到代理服务的作用):
git clone https://ghproxy.com/https://github.com/THUDM/ChatGLM2-6B
![]()
2)下载配套的包:
进入刚下载好的ChatGLM2-6B界面;
指令:cd ChatGLM2-6B
直接使用如下命令安装配套的包;
指令:pip install -r requirements.txt
![]()
ChatGLM2-6B文件是辅助文件,不包含模型,接下来我们下载模型
3)部署模型(由于网络不稳定,建议多次输入执行命令)
git clone https://huggingface.co/THUDM/chatglm2-6b
![]()
进入刚下载好的chatglm2-6b目录;
cd chatglm2-6b
![]()
将chatglm2中pytorch_model-0000X-of-00007.bin的文件删掉,重新下载,下载命令如下:
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00001-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00002-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00003-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00004-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00005-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00006-of-00007.bin
wget https://huggingface.co/THUDM/chatglm2-6b/resolve/main/pytorch_model-00007-of-00007.bin
目前huggingface国内网站登不上去,可以先通过huggingface下载文件到本地,再上传到服务器上,如果是腾讯云服务器,用vscode远程连接以后,将文件拖拽到vscode即可实现从本地到服务器上的传输。
2.如何使用chatglm
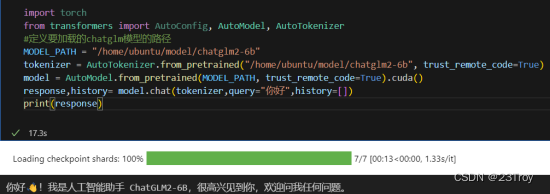
1)测试自己的chatglm是否可以运行,写一个.py或者.ipynb文件,代码如下:
import torch
from transformers import AutoConfig, AutoModel, AutoTokenizer
#定义要加载的chatglm模型的路径
MODEL_PATH = "/home/ubuntu/model/chatglm2-6b"
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).cuda()
response,history= model.chat(tokenizer,query="你好",history=[])
print(response)
#出现如下字段则表明可以使用chatglm2-6b模型。
你好(鼓掌)!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
2)在ubuntu系统上直接进行问答:
cd 到目录ChatGLM2-6B下,改变文件的加载路径,使用如下命令:
python3 cli_demo.py
加载成功后便可在系统上直接与chatglm交流。
![]()
3)在界面上与chatglm进行问答(自带web_demo.py,web_demo2.py)
使用web_demo.py
cd 到目录ChatGLM2-6B下,使用如下命令:
python3 web_demo.py
![]()
注意:由于我们使用的是云服务器,因此不可能在本地(127.0.0.1)进行页面展示。所以打开文件web_demo.py,修改最后一行代码如下
demo.queue().launch(share=False, inbrowser=True) ----->
demo.queue().launch(share=False, inbrowser=True, server_name="0.0.0.0")
![]()
这样就能通过服务器的ip地址访问web界面。一般默认端口是7860,如果想要修改端口需要确保安全组允许端口访问。


如何使用web_demo2.py
cd 到目录ChatGLM2-6B下,使用如下命令:
streamlit run web_demo2.py --server.port 7860
注意:由于我们使用的是云服务器,腾讯云默认端口为7860,所以我们这里设定端口为7860
如何进行微调:
chatglm自带ptuning的微调方式:
cd 到目录ChatGLM2-6B下,再cd到ptuning,在当前文件夹下找到train.sh再修改参数
这里应用的是网上的图片,实际参数大家根据自己的情况进行修改
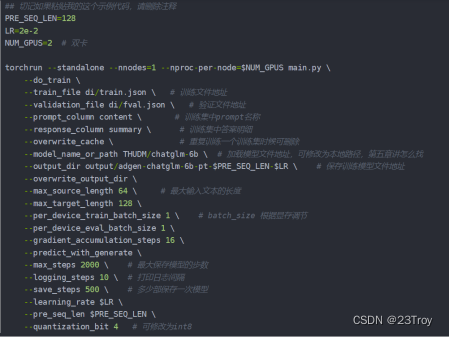
使用如下命令即开始训练数据:
![]()

















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









