







本篇文章介绍yolo目标检测数据集的一般格式,及如何借助labelimg标注软件对图片进行标注。最后对数据集进行划分,并将数据集组织为ultralytics框架可用的目录结构,使数据集能够利用ultralytics框架对yolo3、yolo5、yolo8、yolo9、yolo10等进行训练。
1.安装labelimg标注软件
安装该标注软件较为简单,需要事先安装好Python。安装好python之后,直接在命令行窗口通过pip即可安装labelimg标注软件
pip install labelImg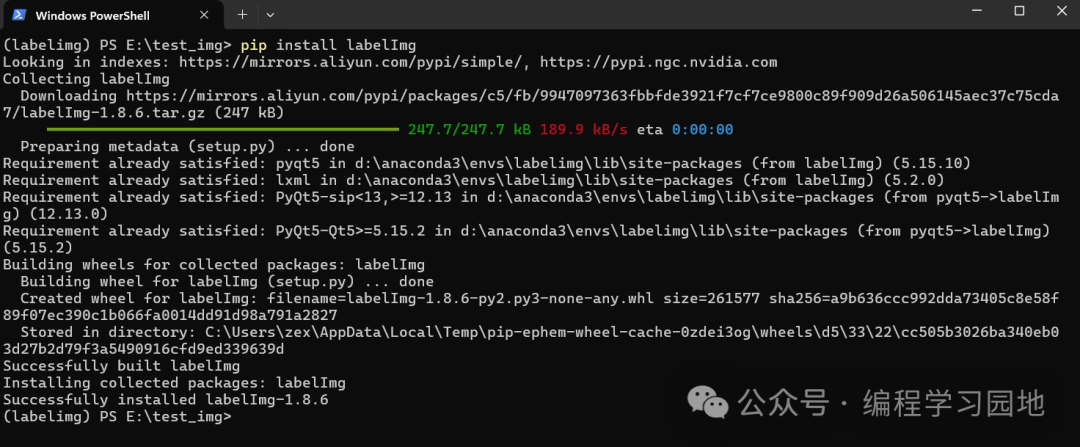
安装好之后,接着直接在命令行中输入labelimg命令,即可启动labelimg软件,接着系统会自动弹窗显示软件界面,有了界面即可点击界面中的按钮对图片进行标注。
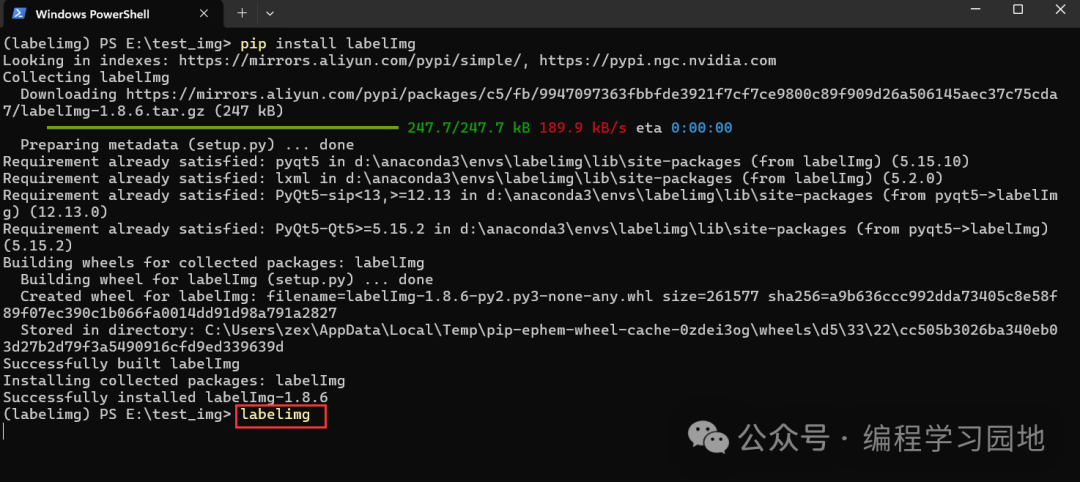
2、对图片进行标注
下面以test_img文件夹(该目录下有一些施工人员的图片)下的图片为例,介绍一下如何用labelimg标注软件对图片进行标注,我们的标注目标是对戴安全帽的人和未戴安全帽的人头部进行标注,戴安全帽标签为helmet、未戴安全帽标签为head。

首先,点击 Open Dir 按钮,弹出文件夹选择,选择我们实现准备好的图片
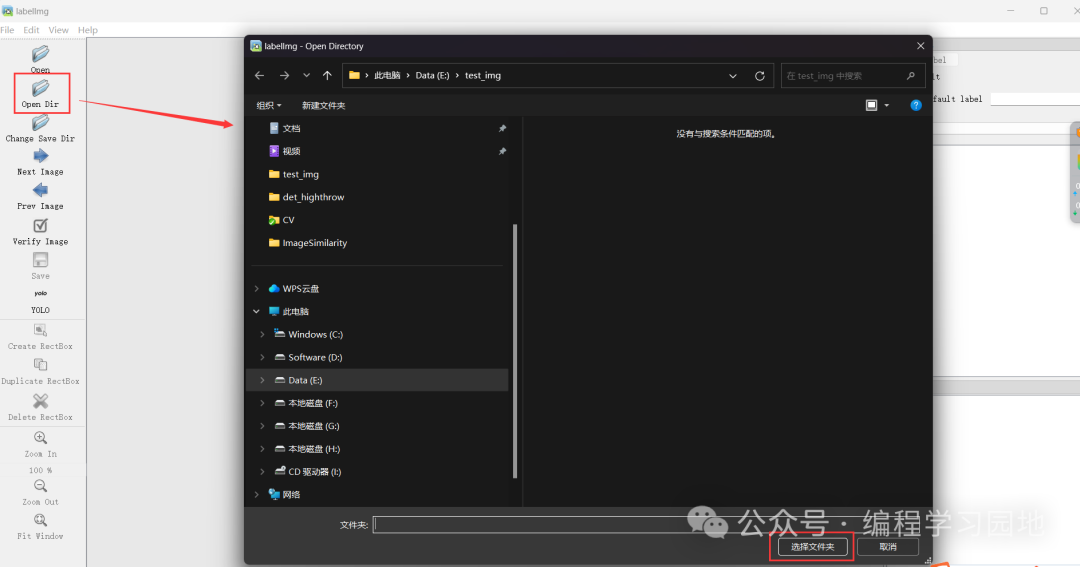
接着labelimg界面中会显示选中的文件夹下第一张图片

标注之前需要选择数据集保存的格式,这里有三种格式:yolo、ml、voc,我们这里选择yolo格式,点击下图的按钮进行切换选择。

紧接着点击‘Create RectBox’按钮,然后按住鼠标左键不放并拖动鼠标,对目标进行拉框标注,框好之后松开鼠标左键自动弹出标签选择框(如下图步骤3),在输入框中输入标签即可(注意标签名称不能为中文及特殊字符,只能是英文或者数字)。最后点击左侧工具栏的'Save按钮'对当前标注好的图片进行保存,保存的文件为.txt文本
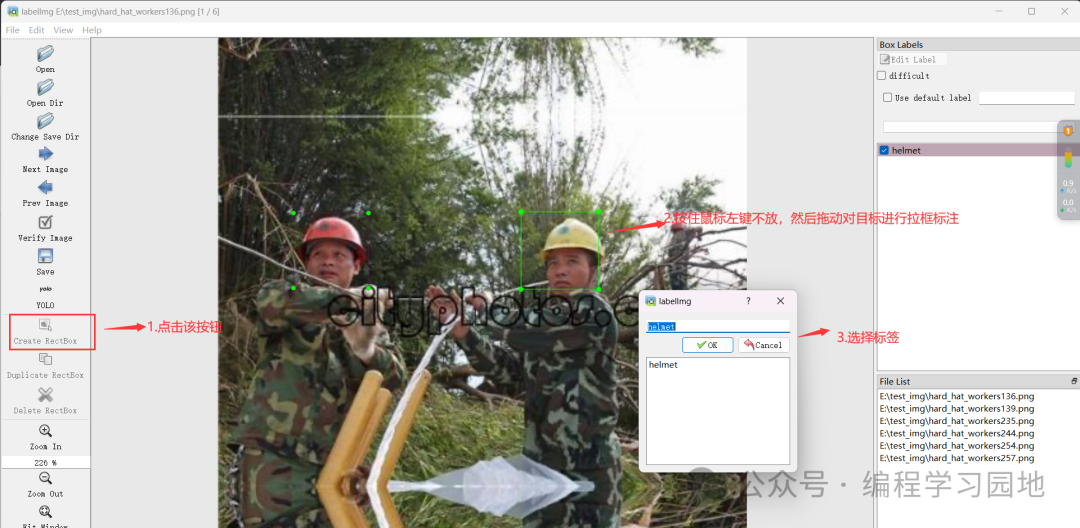
标注完并保存当前标注好的图片之后,点击左侧工具栏 ‘Next Image’对下一张图片进行标注,保存,依次往复。下面一段视频为整个步骤的实操演示:
3、标注文件结构内容分析
标注好之后,该目录下会多出一系列的.txt文本文件,图片及txt文件都存放在一个目录中,注意每张图片及其对应的txt标注文件的文件名是一模一样的,即图片和标签文件一一对应。
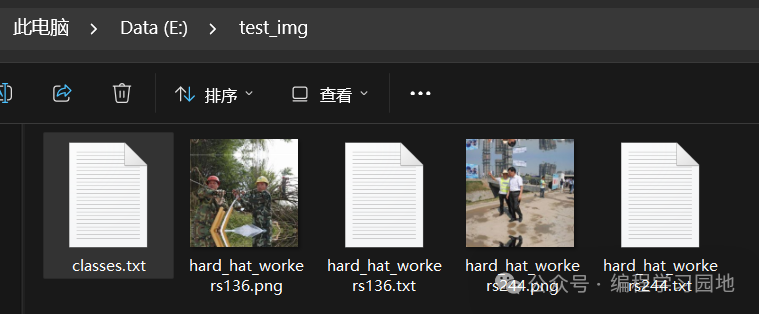
其中,classes.txt中记录了该数据集的所有标签
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











