






在进行YOLO训练模型前最重要的一步就是创建自己的数据集,接下来讲介绍创建数据集的详细步骤。
目录
官网链接附上:YOLO官网链接,一定一定要学会看文档!!!

一、收集数据源
- 图片尺寸:YOLO 模型可以接受不同尺寸的图片作为输入。然而,为了获得最佳性能,建议将图片的尺寸调整为模型所期望的输入尺寸。对于 YOLOv5,常见的输入尺寸是 640x640 像素。你可以使用图像处理库(如 OpenCV)来调整图片的大小。
- 图片数量:数据集的大小对于模型的性能和泛化能力有很大影响。通常,更多的图片可以提供更多的信息,有助于模型学习到不同的场景和物体变化。一般来说,建议准备至少几百张到几千张图片,以确保模型有足够的多样性来进行学习。
- 图片质量:确保图片的质量良好,清晰可见,并且包含你想要检测的物体。避免使用模糊、低分辨率或有噪声的图片,因为这可能会影响模型的准确性。
- 多样性:尽量收集具有多样性的图片,包括不同的场景、光照条件、物体姿态和比例等。这样可以帮助模型更好地适应各种实际情况,提高泛化能力。
- 标注准确性:对于每张图片,需要进行准确的标注,标记出物体的位置和类别。标注的准确性对于模型的训练至关重要,因为模型将根据标注来学习物体的特征和位置。
- 数据增强:为了增加数据集的多样性,可以应用数据增强技术,如随机旋转、翻转、缩放、裁剪等。这可以帮助模型更好地应对不同的视角和变化,减少过拟合的风险。
- 数据集划分:将数据集划分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于调整超参数和监控模型的性能,测试集用于最终评估模型的准确性。
- 类别均衡:如果你的数据集中存在类别不平衡的情况(某些类别的样本数量远远多于其他类别),可以考虑采取一些措施来平衡类别分布,例如过采样或欠采样。
二、进行数据标注
常用软件:
- Labelimg:
labelImg是一种矩形标注工具,常用于目标识别和目标检测,其标记数据输出为.xml和.txt。 - Labelme:
labelme是一种多边形标注工具,可以准确地将轮廓标注出来,常用于分割,其标记输出格式为json。
注:Labelimg闪退问题,如果你安装的是3.10以上的python版本,可以尝试安装低版本的python来尝试打开
软件安装:
首先确保已经在电脑上安装了python或者已经创建了conda虚拟环境:安装Python和Anaconda虚拟环境
由于labelimg和labelme是基于pyqt开发的且图像处理需要使用PIL,因此先安装以下两个库:
pip install pyqt5 # 安装pyqt5
pip install pillow # 安装PIL库接着就可以安装标注软件了
pip install labelimg # 安装labelimg
pip install labelme # 安装labelme,如果出现错误可以在labelme后面添加版本号试试 labelme==3.16.2如果安装太慢可以使用国内镜像下载:
pip install 需要安装的库 -i https://pypi.tuna.tsinghua.edu.cn/simple # 这里提供的是清华的镜像至此安装过程就结束了,接下来介绍软件的使用。
直接在刚刚安装的cmd输入 labelimg/labelme 就能够打开软件,如果显示 不是内部或外部命令,也不是可运行的程序或批处理文件。
那就找到你所安装的python文件夹下的Scripts文件夹中的labelimg/labelme.py文件进行双击打开。
也可以在电脑的搜索框中直接搜索labelimg/labelme打开。
软件使用:
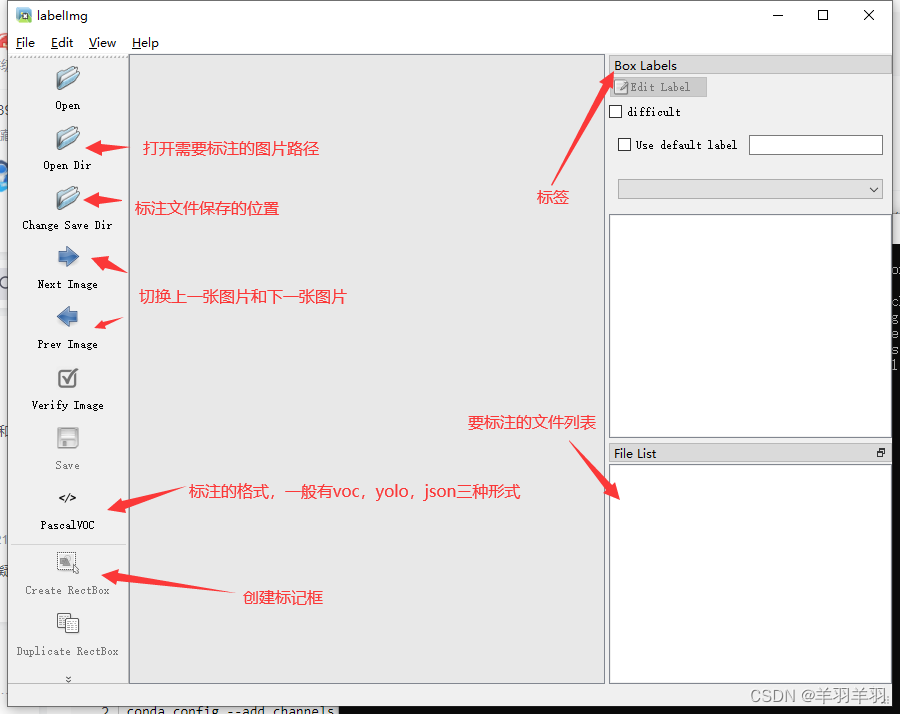
两个软件的快捷键和使用都相差不大,labelimg可以选择标注的格式
labelimg
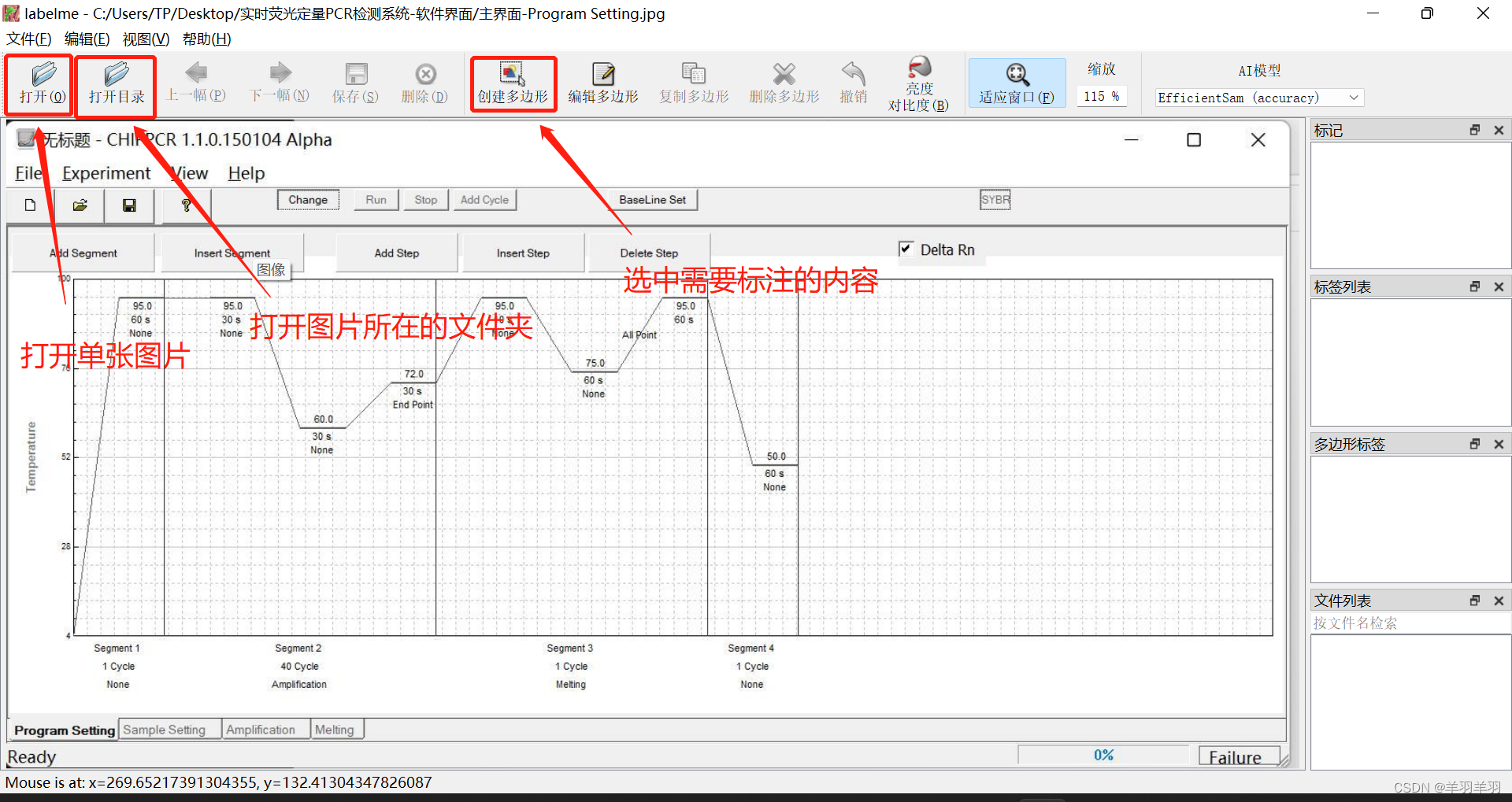
labelme
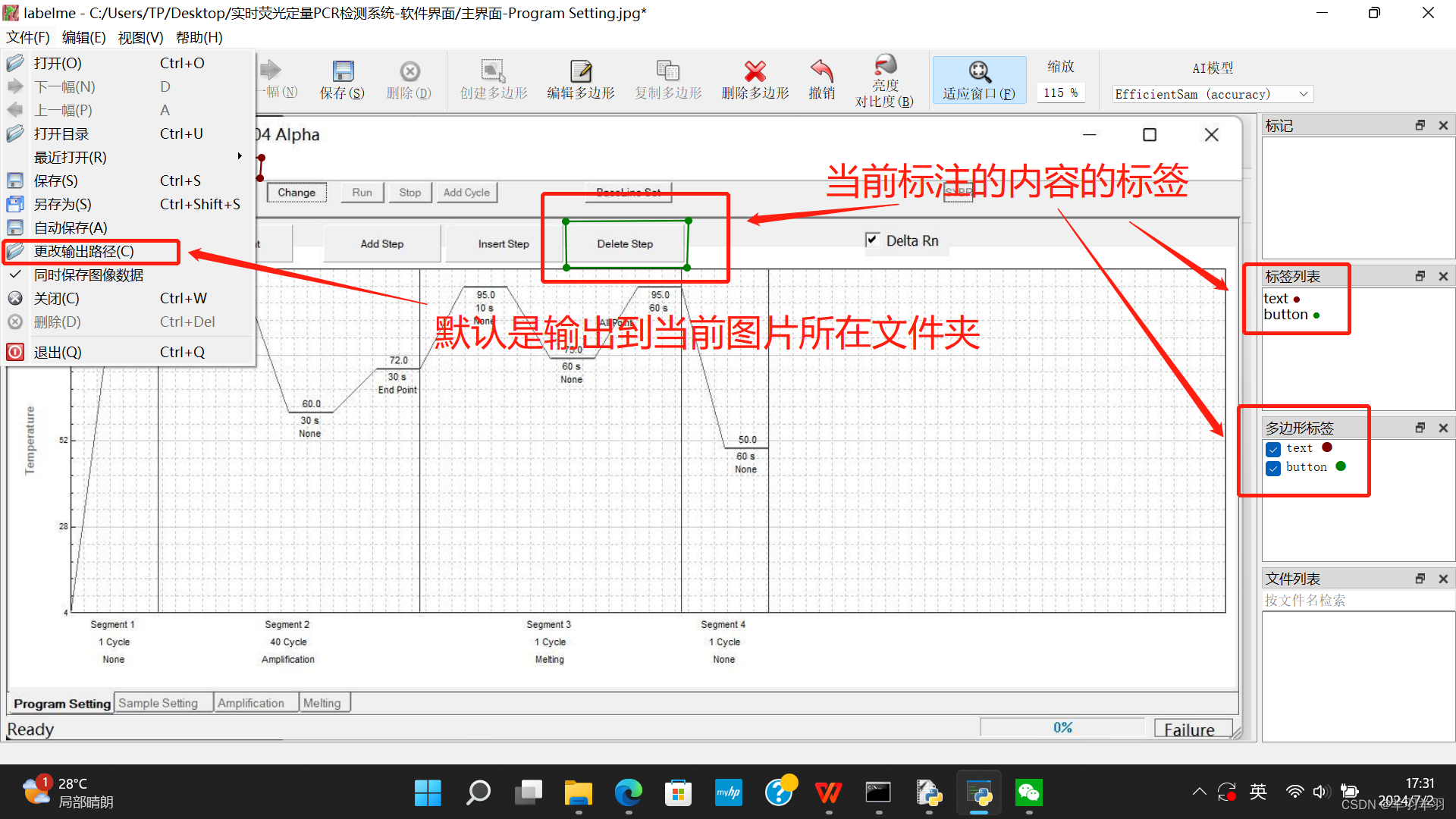
labelme的常用快捷键如下:
- Ctrl+N:创建多边形标注框;
- Ctrl+R:创建两点矩形框;
- Ctrl+E:选中标注框或标签时按下可打开编辑窗口;
- Ctrl+J:切换到编辑模式;
- Ctrl+鼠标滚轮:放大/缩小当前图片;
- Ctrl+F:还原尺寸;
- Ctrl+Z:撤销上一个点;
- Ctrl+Shift+P:增加一个点;
- Ctrl+D:等边行复制;
- Ctrl+C:复制;
- Ctrl+V:粘贴;
- Delete:删除;
- A:切换到上一张图片;
- D:切换到下一张图片。
如果你想修改快捷键,可以打开labelme安装目录下的.labelmerc文件,找到shortcuts部分,根据需要修改对应的快捷键即可。
三、数据整理
查看yolo官网可知
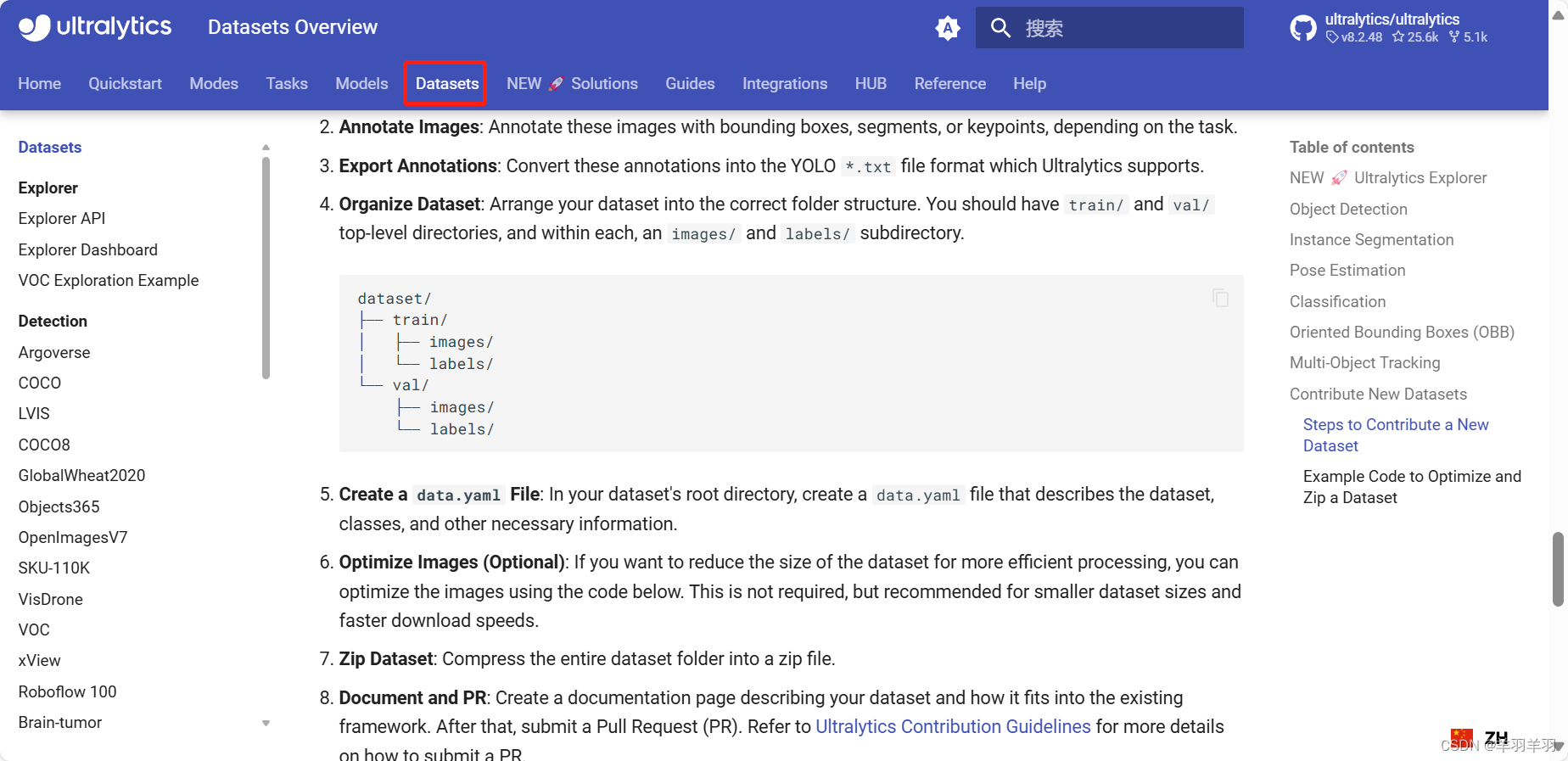
数据集格式:
dataset/
├── train/
│ ├── images/ # images文件夹是用来存放图片的
│ └── labels/ # labels文件夹是用来存放图片对应的数据文件
└── val/
├── images/
└── labels/这里的train文件夹就是用来训练模型的数据,val文件夹是用来验证的模型准确率的。
注:labels中的数据文件名称要与images中的图片名称相对应
如果你使用的是labelme进行实例分割,那么最后生成的是json文件,此时要先把json文件转换为txt文件再放入labels文件夹中。
JSON转TXT文件代码:
# -*- coding: utf-8 -*-
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, classes):
"""
将标注文件从 JSON 格式转换为 YOLO 格式的文本文件,并进行坐标归一化。
:param json_dir: 包含 JSON 文件的目录路径
:param save_dir: 保存转换后文本文件的目录路径
:param classes: 类别名称列表,用逗号分隔
"""
# 获取目录中所有 JSON 文件的路径
json_paths = os.listdir(json_dir)
# 将类别字符串转换为列表
classes = classes.split(',')
# 遍历所有 JSON 文件
for json_path in tqdm(json_paths):
# 构建 JSON 文件的完整路径
path = os.path.join(json_dir, json_path)
# 打开并读取 JSON 文件
with open(path, 'r', encoding='utf-8') as load_f:
json_dict = json.load(load_f)
# 获取图像的高度和宽度
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# 构建保存 TXT 文件的路径
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
with open(txt_path, 'w') as txt_file:
# 遍历每个形状(标注)
for shape_dict in json_dict['shapes']:
# 获取标注的类别标签
label = shape_dict['label']
# 获取类别的索引
label_index = classes.index(label)
# 获取标注的点坐标
points = shape_dict['points']
# 用于存储归一化后的坐标
points_nor_list = []
# 归一化坐标
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
# 将坐标转换为字符串格式
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
# 构建 YOLO 格式的标签字符串
label_str = str(label_index) + ' ' + points_nor_str + '\n'
# 写入到 TXT 文件
txt_file.writelines(label_str)
if __name__ == "__main__":
"""
命令行用法示例:
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir
my_datasets/color_rings/txts --classes "cat,dog"
"""
# 设置命令行参数解析
parser = argparse.ArgumentParser(description='json 转换为 txt 参数')
parser.add_argument('--json-dir', type=str, default="\path\json", help='JSON 文件所在目录')
parser.add_argument('--save-dir', type=str, default="\path\labels", help='转换后 TXT 文件保存目录')
parser.add_argument('--classes', type=str, default='name1,name2...', help='类别列表,逗号分隔')
# 解析命令行参数
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
# 调用转换函数
convert_label_json(json_dir, save_dir, classes)
需要替换的地方
parser.add_argument('--json-dir', type=str, default="\path\json", help='JSON 文件所在目录')
parser.add_argument('--save-dir', type=str, default="\path\labels", help='转换后 TXT 文件保存目录')
parser.add_argument('--classes', type=str, default='name1,name2...', help='类别列表,逗号分隔')把\path\json替换成自己的json文件路径,
把\path\labels替换成自己要存放txt数据的文件路径,
name1,name2...替换成类别名称
记得绝对路径前面要加r
四、创建数据集配置文件
我们找到官网Datasets模块中的coco8
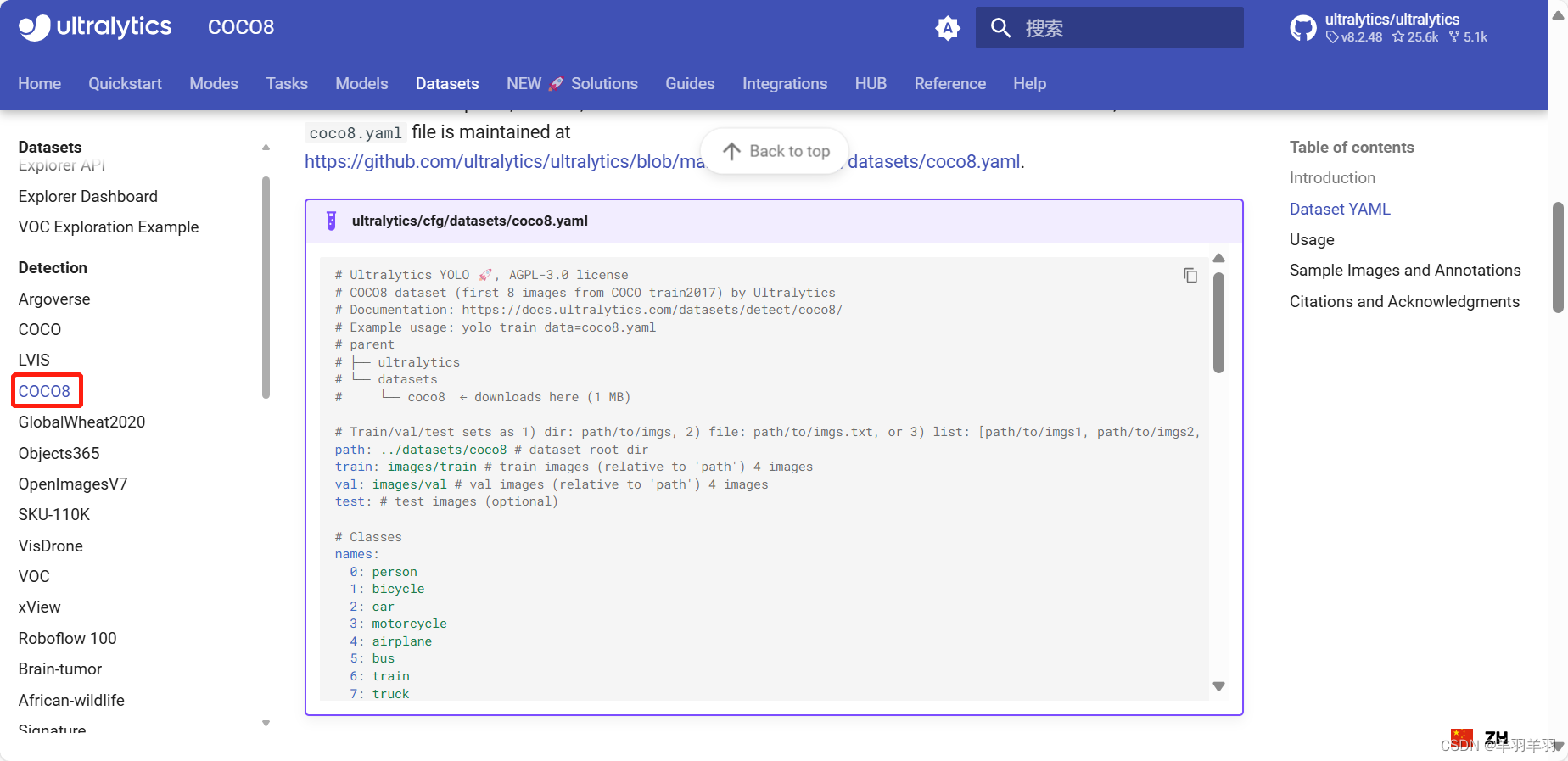
这个yaml就是数据集的配置文件
配置代码如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/detect/coco8/
# Example usage: yolo train data=coco8.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir 数据集文件夹的相对路径
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
# 由于是该yaml配置文件是放在数据集文件夹中的,所以他使用的是相对路径 且train和val必须大于四张照片数据
test: # test images (optional)
# Classes 标签名称,替换成自己的
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco8.zip一般都是将yaml文件放到数据集文件夹下的,这样一个完整的数据集就做完了。















 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









