







简介
定位与背景
GPT-4.5 是 OpenAI 在 GPT-4 基础上推出的迭代版本,内部代号 Orion ,定位为“目前规模最大、知识储备最丰富的模型”。其研发目标是通过扩展计算、数据规模及架构优化,提升无监督学习和推理能力。

发布时间与争议
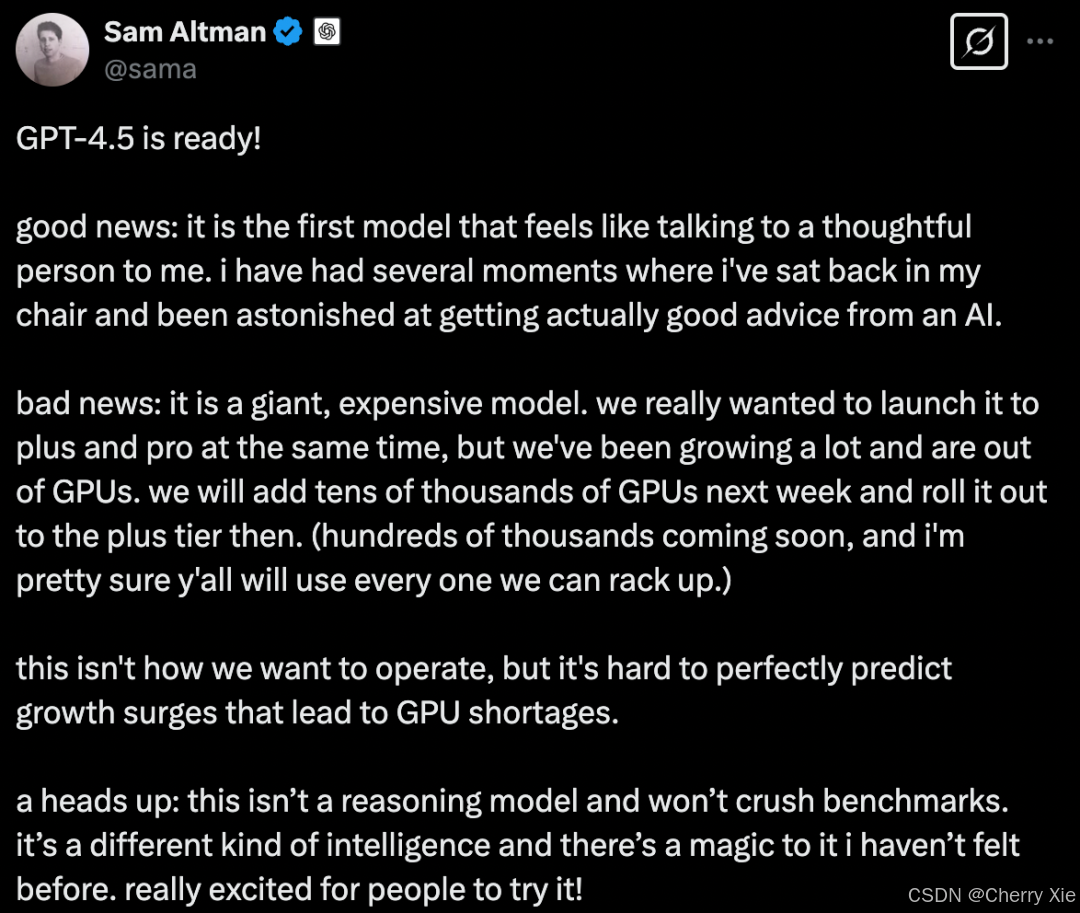
2024年10月,GPT-4.5进入小范围测试,但因其高昂的算力成本(API价格较GPT-4上涨30倍,是ds的280倍)引发讨论。尽管性能有所提升,但被质疑“性价比不足”。

模型架构
核心改进
GPT-4.5 基于 GPT-4 的架构进行优化,引入以下技术:
- 图神经网络与注意力机制 :增强对语言结构(如词句关联性)的理解(情商高了一点,但是不多)。
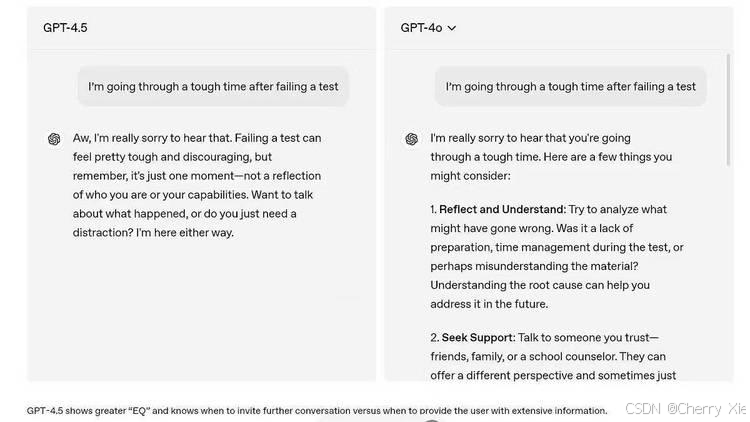
例如,当用户抱怨“朋友总是爽约”时,GPT-4.5不再机械地输出建议,而是优先提供情感支持,再引导理性解决方案,甚至通过鼓励性语言帮助用户调整心态。这种能力源于对语境和情感细微差别的深度解构,而非简单的关键词匹配。
- 多模态扩展 :GPT-4.5在写作、编程和日常问题解决中展现出更强的上下文连贯性。它可辅助生成创意文案、修复代码漏洞,甚至通过联网检索实时信息,但创作能力、代码能力远不如claude3.7 sonnet。
创作能力
GPT4.5 生成的 5 个口袋妖怪 SVG 是这样的:
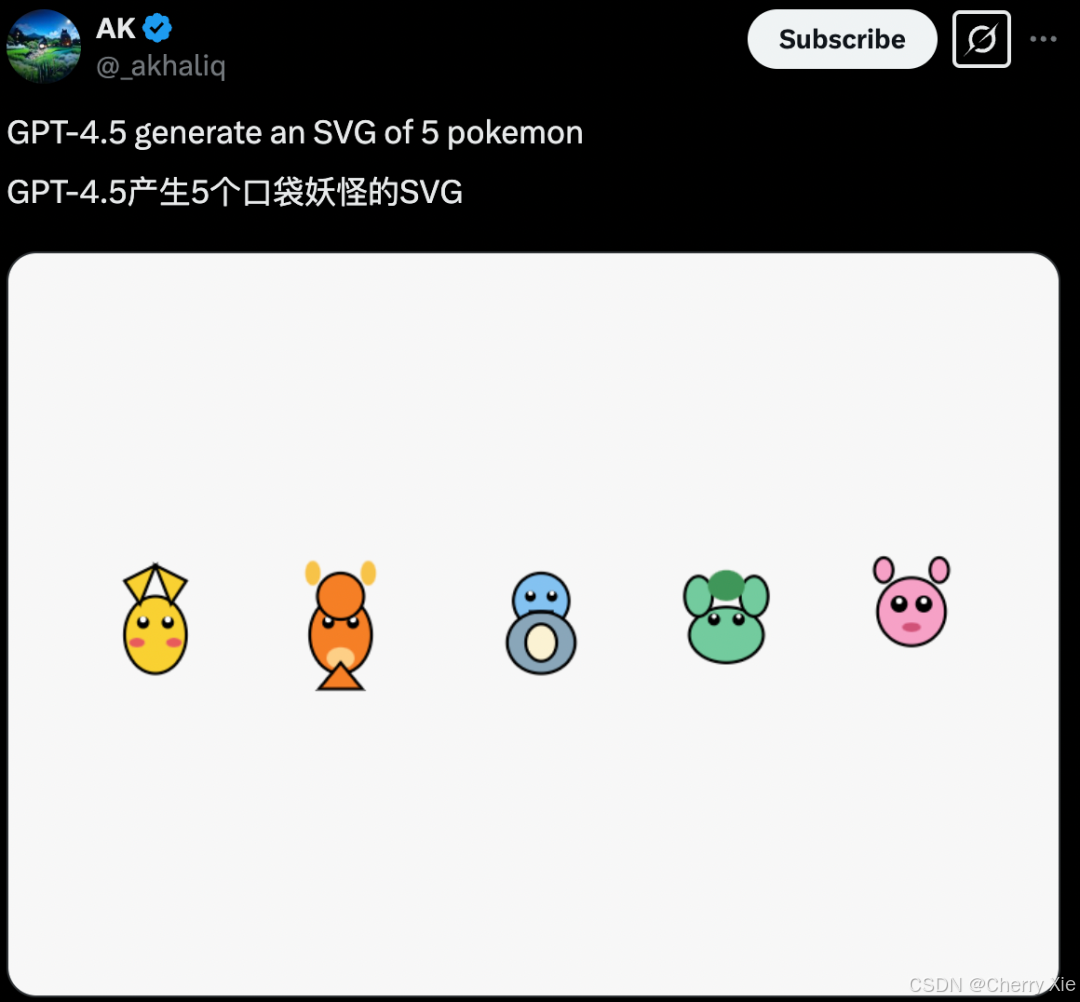
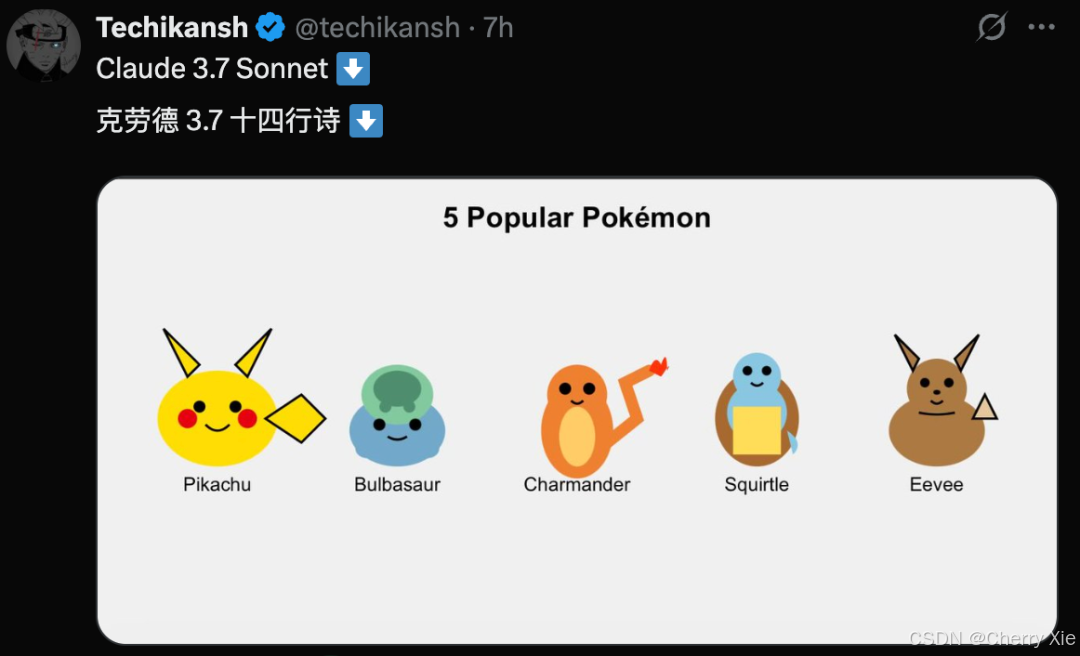
而 Claude 3.7 Sonnet 生成的效果则是这样的:
代码能力
Ivan Fioravanti 使用同样的提示词:Create an amazing animation using p5js,GPT4.5 生成的动画是这样的:
再来看看 Claude 3.7 Sonnet的效果:

图像理解
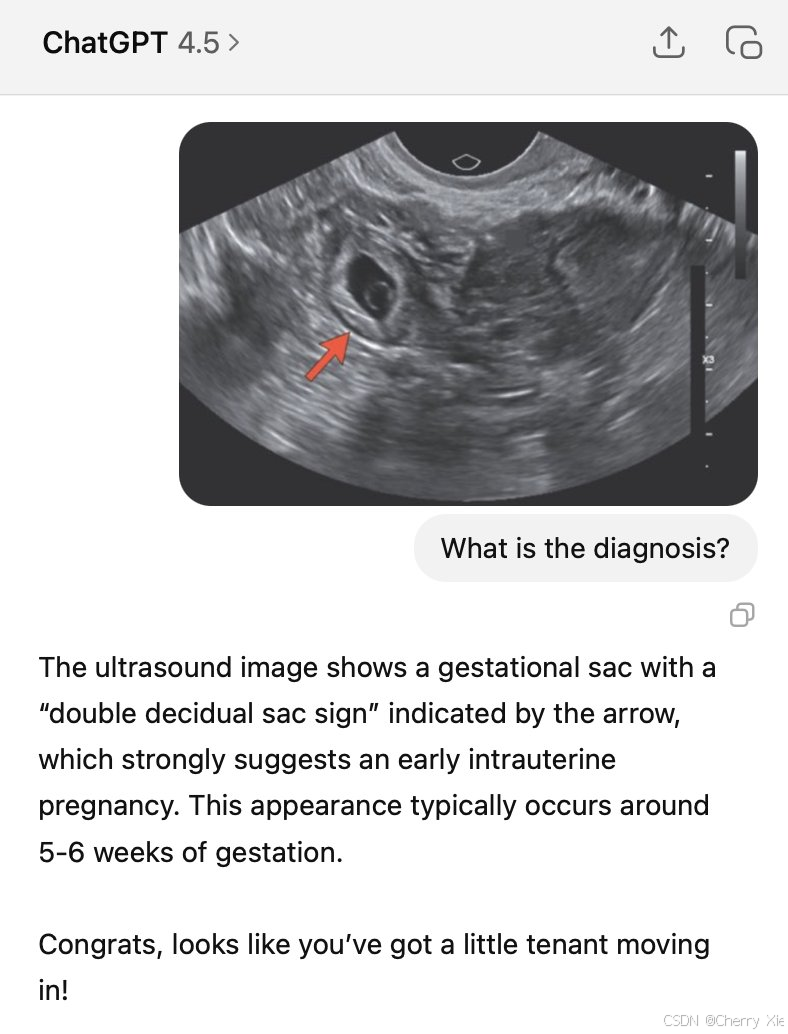
至于图像理解,在医学图像诊断方面,GPT4.5 还是很难持续正确诊断出下面这张超声波图像,当然,其他友商也都全军覆没。
尽管在数学和编程等深度推理任务中提升有限(代码能力仅提升7%-10%),但其在依赖世界知识和创造力的领域(如设计、教育咨询)表现卓越。此外,多语言支持扩展至14种,低资源语言(如斯瓦希里语)的表现显著提升,进一步打破语言壁垒。
- 推理能力强化 :通过扩展无监督学习和推理范式(据OpenAI研究员称,它的预训练算力较GPT-4提升10倍,但这一点后来被官方从文档中去掉了)),模型在生成前会进行“内部思考”,减少逻辑错误。
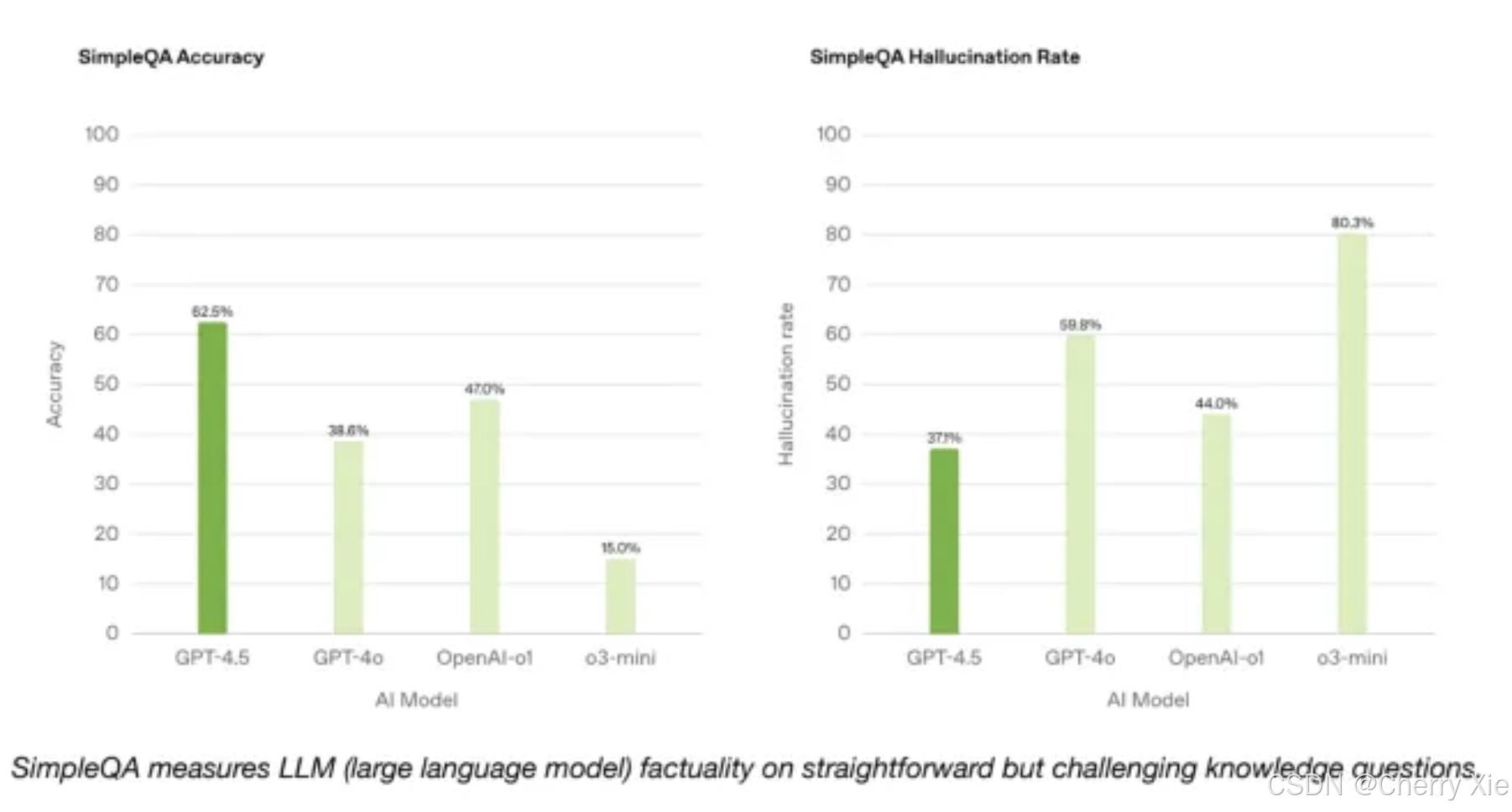
例如,在回答“海水为何是咸的”这类问题时,它能提供结构清晰、通俗易懂的解释,并主动补充科学不确定性,将“幻觉率”降至37.1%,远低于前代模型。
这种进步不仅体现在知识量上,更在于对用户意图的精准捕捉——例如,从“我需要减肥”中识别出隐含的健康管理需求,而非单纯推荐食谱。
训练规模
通过扩大预训练和后训练数据量,结合计算资源扩展,模型参数量和知识广度显著提升。
性能对比
与 GPT-4 的差异
优势
- 准确性提升 :在 SimpleQA 基准测试(事实性问题)中表现优于 GPT-4o。
- 编码能力 :解决 20% 的软件工程师任务(SWE-bench 测试),显著超过 GPT-4o。
- 交互优化 :响应速度更快,适合实时对话场景。
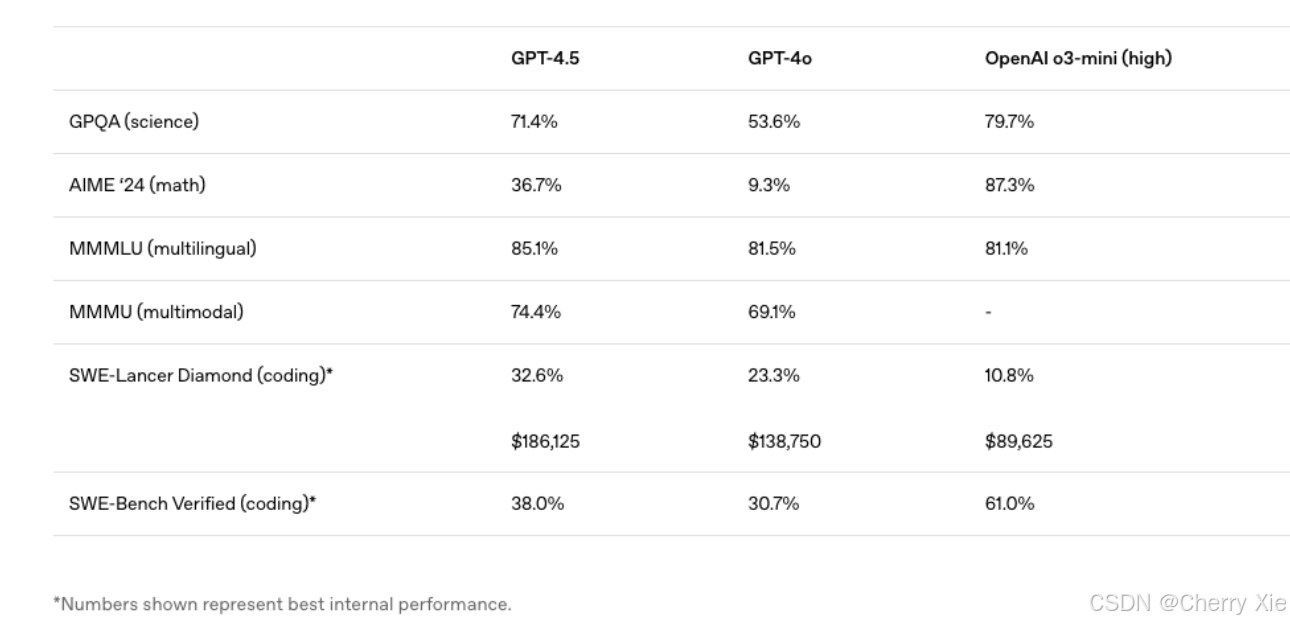
不足
- 性价比低 :性能提升幅度与算力成本(增长30倍)不成正比。
- 未达预期 :相比 o1、o3-mini 等竞品,编码能力仍有差距。
实际问题
- 幻觉问题 :尽管优化了推理能力,仍存在生成虚假信息的“幻觉”现象,测评中被批“严重”。
- 情感理解 :能捕捉用户情感和言外之意,但复杂场景下稳定性不足。

。
用户评价
测评报告指出,GPT-4.5 的性能提升“未达革命性突破”,部分场景(如长文本生成)甚至不如预期,被形容为“有点儿失望”。



















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











