







简介

CosyVoice 2 是一个开源模型,用户可以根据硬件条件进行部署和推理。当前版本为功能扩充(预训练音色/3s极速复刻/自然语言控制/自动识别/音色保存/API),支持 Windows / Linux / MacOS。
最低硬件要求
-
CPU:普通个人电脑即可运行,但推理速度较慢,适合试用或小规模测试。
-
内存:至少 8GB RAM,建议 16GB 以确保流畅运行。
-
存储:预训练模型和依赖文件约需 10-20GB 空间(具体取决于选择的模型版本,如 CosyVoice2-0.5B 或 CosyVoice-300M)。
-
操作系统:支持 Ubuntu、CentOS、Windows 等主流系统,推荐 Linux(如 Ubuntu 22.04)以获得最佳兼容性。
核心技术与性能优势
语音生成质量提升
采用监督离散语音标记技术 ,结合有限标量量化 和块感知因果流匹配模型 ,显著优化发音准确性、音色一致性及音质表现。支持多语言与跨语言合成 ,覆盖中文、英文等多种语言,满足国际化需求同时instruct合成音频,支持上海话、四川话、粤语、河南话等多种方言。
实时性与低延迟
支持双向流式语音合成 ,首包合成延迟仅150ms ,适合智能客服、虚拟助手等实时交互场景。流式推理技术使模型在生成过程中动态调整,避免传统语音合成的“吞字漏字”问题。
零样本与快速克隆能力
仅需3秒语音样本 即可完成音色克隆,且支持细粒度控制 (如语速、语调),降低语音定制门槛。模型参数规模达0.5B ,兼顾性能与资源效率。
安装
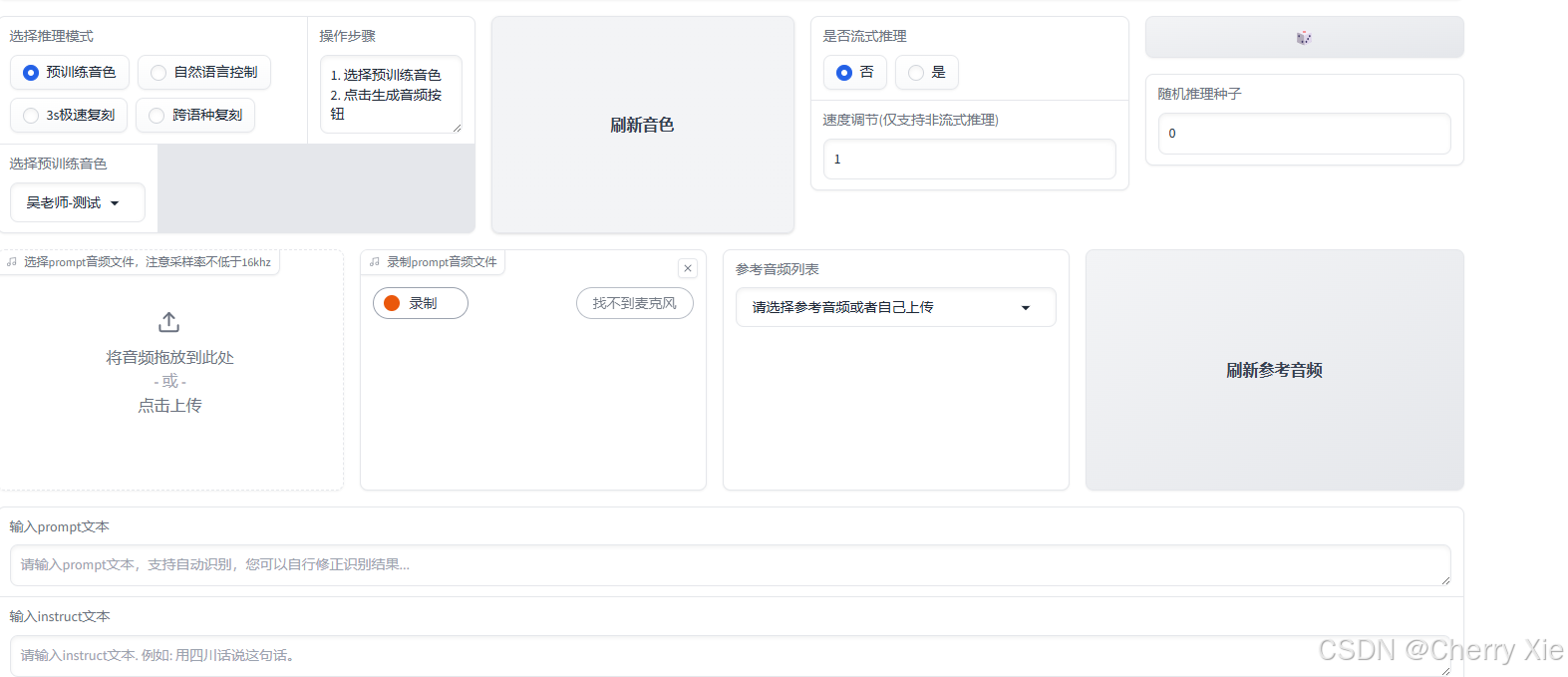
Linux & macOS
conda create -n cosyvoice -y python=3.10
conda activate cosyvoice
conda install -y -c conda-forge pynini==2.1.5
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
python webui.py --port 8080 --open
Linux 可安装 ttsfrd 提升文本归一化性能(可选)
sudo apt-get install -y git build-essential curl wget ffmpeg unzip git git-lfs sox libsox-dev nvidia-cuda-toolkit
git lfs install
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd
cd pretrained_models/CosyVoice-ttsfrd/
unzip resource.zip -d .
pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
Windows
windows 安装的话,因为部分模块的关系,推荐以便携式整合包安装。
相关文献
有一键包需求的可私~
觉得内容还不错的可以点个关注(当然,觉得不行也可以点)!!!



















 2395
2395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











