









简介
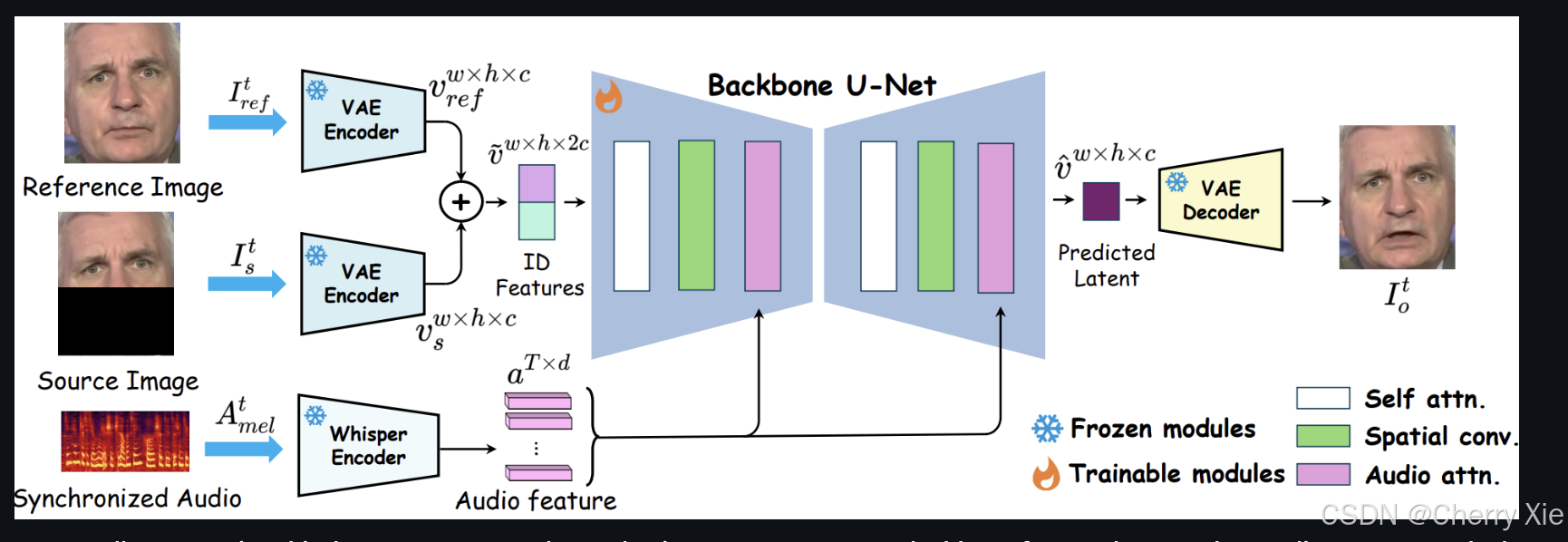
MuseTalk 是一个开源模型,发布在 GitHub 和 Hugging Face ,支持与 MuseV 结合,形成完整的虚拟人类生成解决方案。它在 NVIDIA Tesla V100 上实现 30fps+ 的实时推理,处理多种语言音频(如中文、英文、日语),并通过 UNet 架构和 HDTF 数据集训练 。
新版更新细节

-
版本发布与时间线
- MuseTalk 1.5 版本于 2025 年 3 月 28 日发布,显著改进于 1.0 版本 。
- 技术报告更新于 2024 年 10 月 18 日,详细说明了模型的架构和训练方法 。
-
性能提升
-
损失函数集成:MuseTalk 1.5 集成了感知损失(perceptual loss)、生成对抗网络损失(GAN loss)和同步损失(sync loss),显著提升了模型的整体性能 。
感知损失提升视觉质量,确保生成的视频在细节上更清晰。 -
GAN 损失增强生成图像的真实感,减少伪影。
-
同步损失优化唇部与音频的匹配精度,减少时间延迟。
-
效果:这些改进确保了更高的清晰度、身份一致性和精确的唇部-语音同步 。
-
-
训练策略优化
-
两阶段训练策略:MuseTalk 1.5 采用了两阶段训练策略,可能包括先预训练再微调的流程 。
- 第一阶段可能专注于基础特征提取,第二阶段优化唇部同步细节,提升模型的稳定性和泛化能力。
-
时空数据采样方法:引入了时空数据采样(spatio-temporal data sampling),在训练期间选择与目标帧头部姿势相似的参考图像 。
- 此方法帮助模型专注于精确的唇部运动,过滤冗余信息,平衡视觉质量和唇部同步精度。
-
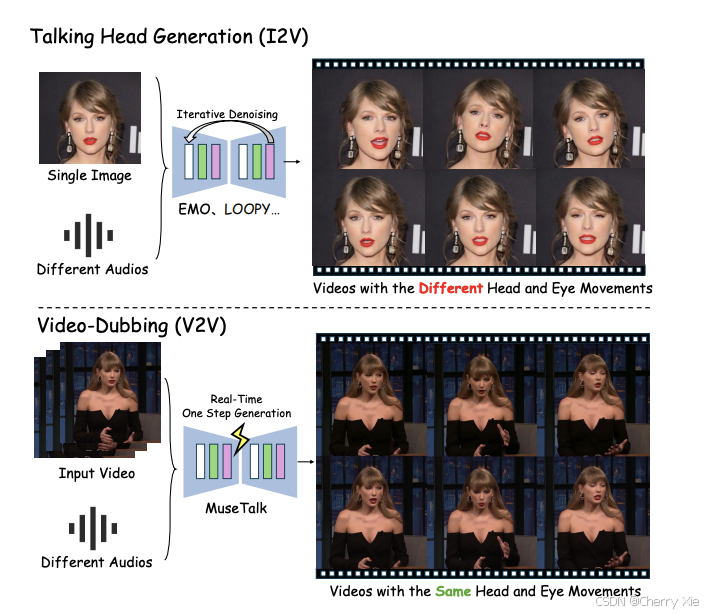
- 功能与灵活性
-
多语言支持:支持中文、英文、日语等语言音频输入,适合全球化的视频 dubbing 需求 。
-
参数调整:通过 bbox_shift 参数调整面部区域中心点,控制嘴巴的张合程度。例如,设置负值减少嘴巴张开,适合精细调整 。
-
与 MuseV 结合:作为虚拟人类生成解决方案,建议先用 MuseV 生成视频(如文本到视频或图像到视频),再用 MuseTalk 处理唇部同步 。
-
性能对比

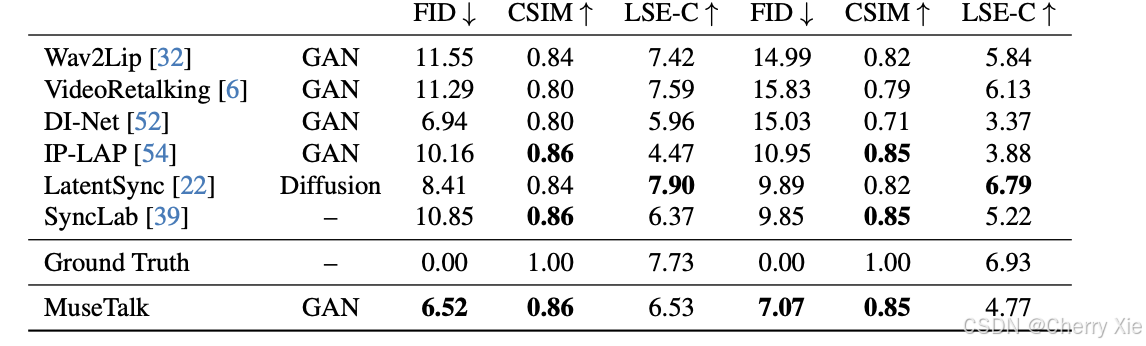
看看效果
相关文献
技术报告:https://arxiv.org/pdf/2410.10122
github地址:https://github.com/TMElyralab/MuseTalk
模型下载:https://huggingface.co/TMElyralab/MuseTalk



















 3871
3871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











