







 提出了一种针对Java语言的代码注释自动生成模型DeepCom,利用Seq2Seq模型和改进的AST遍历方法SBT,解决了注释生成任务。实验结果显示,DeepCom在BLEU-4指标上优于现有基线。
提出了一种针对Java语言的代码注释自动生成模型DeepCom,利用Seq2Seq模型和改进的AST遍历方法SBT,解决了注释生成任务。实验结果显示,DeepCom在BLEU-4指标上优于现有基线。
原文链接:点此位置
来源:ICPC2018
一、论文背景
软件维护时,代码注释可以帮助开发人员理解程序,并减少阅读和定位源码的时间。但是这些注释在软件项目中通常与源码不匹配、缺失或过时,开发人员必须从源代码中推断出该功能,代码注释自动生成技术应运而生。受CODE-NN的启发,结合深度学习技术的优势,作者提出了一种针对Java语言的代码注释自动生成模型——DeepCom。
两大贡献:
- 将代码注释生成任务表示为一个机器翻译任务。
- 自定义了一个基于序列的模型来处理从源代码中提取的结构信息,用于生成Java方法的注释。提出了一种新的AST遍历方法(SBT)和一种更好处理词汇表外的token的方法。
DeepCom优点:
- 通过学习源代码直接生成注释,而不是从关键字合成注释或搜索类似代码片段的注释。
- 利用了丰富而明确的代码结构生成注释
二、方法原理
1.整体模型框架
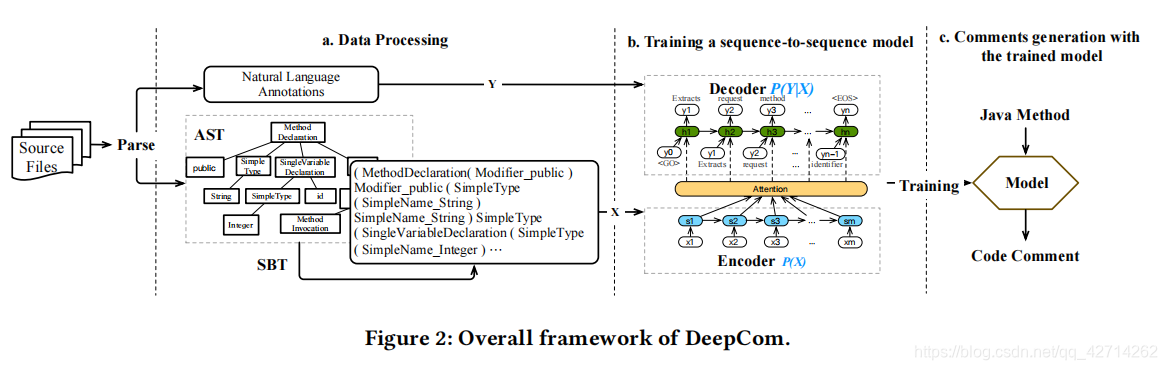
三个步骤:数据处理、模型训练和在线测试。
训练过程主要面临两个问题
- 如何表达AST以存储结构信息以及在遍历AST时保持这个表达的明确性
- 如何处理源码中出现的词汇表没有的token
2.Seq2Seq模型
论文使用Seq2Seq模型学习源码和生成注释,如下图:

该模型由三个组件组成:编码器、解码器和注意力机制。Seq2Seq模型原理可参考:全面解析RNN,LSTM,Seq2Seq,Attention注意力机制,非常推荐,写的很详细。这里按照论文大概说说:
(1)编码器
论文使用LSTM作为编码器。在每个时间步从输入序列中读取一个token,记为xt,然后利用上一个隐藏状态st-1更新和记录当前的隐藏状态st。编码器从源代码学习潜在特征,最终将特征编码到语义向量c中。
(2)注意力机制
若不加注意力机制,在解码时用的都是固定的语义向量c。引入注意力机制后,固定的中间语义向量c换成了根据当前生成单词而不断变化的ci。计算公式如下:
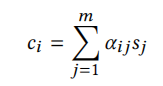
即对每个输入单词的隐藏状态sj通过权重αij进行加权求和,αij的值越高,表示第i个输出在第j个输入上分配的注意力越多,在生成第i个输出的时候受第j个输入的影响也就越大。其中
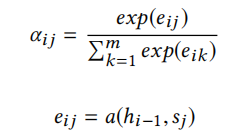
可以发现权重其实用的就是softmax;eij表示编解码状态的相关性得分,利用输出的第i-1个隐藏状态和编码器的第j个隐藏状态的计算得出。
(3)解码器
解码器也是LSTM实现,不断将前一个时刻的输出yi-1作为后一个时刻的输入,输出的是每个字符的概率值,利用下式计算,可以根据这个概率值进行预测,比如选取概率值最大的字符。
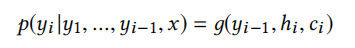
模型的目标是最小化交叉熵,即最小化下面这个目标函数(N是训练样本的总数,n是每个目标序列的长度。y(i)j是指在第i个样本中的第j个单词。):
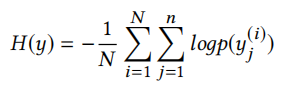
3.AST遍历——SBT
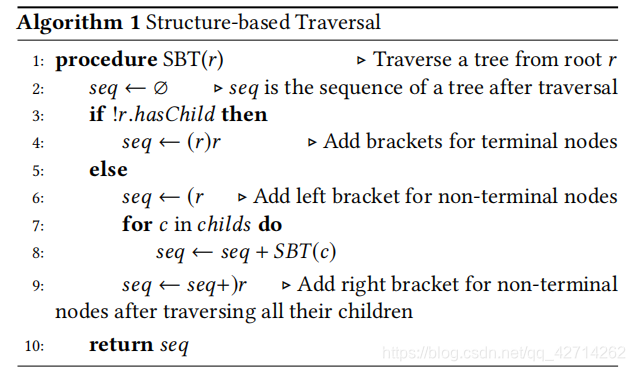
由于源代码的结构问题,很难进行源代码和自然语言之间的翻译,一个简单方法时将代码视为纯文本,显然这样会丢失代码的结构信息。为了同时学习代码的语义和语法信息,论文通过遍历ASTs将其转换为具有特殊格式的序列。由经典遍历方法(如先序和后序遍历)不能通过遍历的结果精确恢复原始的AST(就是给定遍历的结果,可能可以生成不同的树结构,如当二叉树中某个节点仅仅只有一个子节点的时候)。为了解决这个问题,论文提出了一种基于结构的遍历(SBT)方法来遍历AST,具体算法和例子如下:
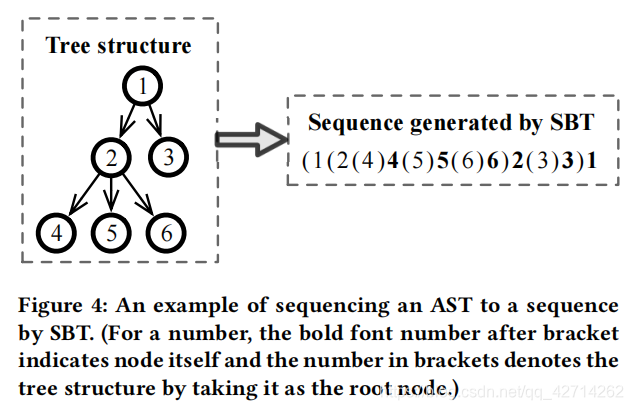
以Figure4为例具体说说是怎么遍历的:
- 从根节点中,首先使用一对方括号来表示树的结构,并将根节点本身放在右括号后面,即(1)1。
- 遍历根节点的子树,并将子树的所有根节点放入括号中,即(1(2)2(3)3)1。因为1包含两个子树节点2、3。
- 利用递归遍历每个子树,直到所有节点都被遍历。
论文还举了一个具体的例子,如下:

可以发现AST里面的终端节点变量值是用括号括起来的,前面是类型名,如SimpleName(String),为了区分SBT生成序列的括号与AST原本结构内的括号,作者将变量类型和变量值用下划线链接起来,如SimpleName(String)表示为SimpleName_String。非终端节点就用类型表示就可以了。
4.Out-of-vocabulary tokens
在NL中,在数据预处理时通常将词汇量限制在最常见的单词上,词汇表外的单词tokens用未知token(UNK)替换,对于NLP来说这样做十分有效因为UNK非常少。然而对于编程语言,除了固定的运算符和关键字外,用户自定义的标识符占据了大多数代码token,显然不能直接将这些自定义的标识符也视为UNK。
因此,论文提出了一种表示源代码词汇表外token的新方法。DeepCom的词汇包括节点的类型,部分形式为“类型-值”的终端token。论文保留了出现最频繁的30,000个token作为AST序列词汇表。对于词汇表之外的“类型-值”的token,DeepCom使用它们的“类型”术语,而非用UNK标记来它们。这样,词汇表外的token就会用其相关的类型信息而不是毫无意义的单词来表示。
三、实验设置
1.数据集构建
使用Eclipse的JDT编译器将Java方法解析为ASTs,提取相应的Javadoc注释(Java方法的标准注释)。论文舍弃的没有Javadoc注释的方法,对于每个有注释的方法,使用出现在Javadoc描述的第一句话作为注释,因为根据Javadoc指南,第一句话通常描述了Java方法的功能。过滤掉那些注释只有一个单词的方法,以及setter, getter, constructor 和 test等很容易生成注释的方法。最终获得69,708个(Java方法,注释)对,按8:1:1划分训练,验证和测试集。
开源的数据集链接:https://github.com/huxingfree/DeepCom
2.参数设置
- 模型搭建框架——tensorflow
- 优化器——SGD
- 模型——双层LSTM,隐藏状态与词嵌入维度均为512
- 学习率——0.5,按0.99的衰减速率衰减
- dropout——0.5
- minibatch——100
- epoch——50
3.评价指标
BLEU-4

四、结果
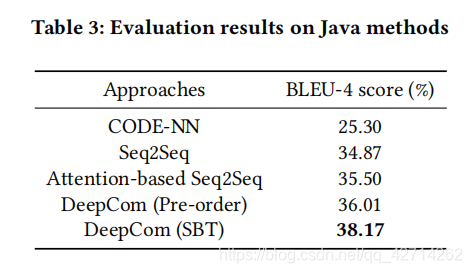
RQ1: How effective is DeepCom compared with the state-of-the-art baseline?
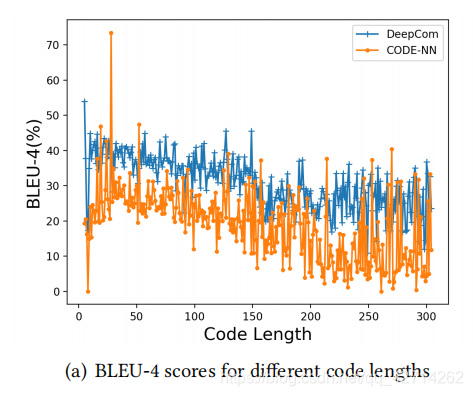
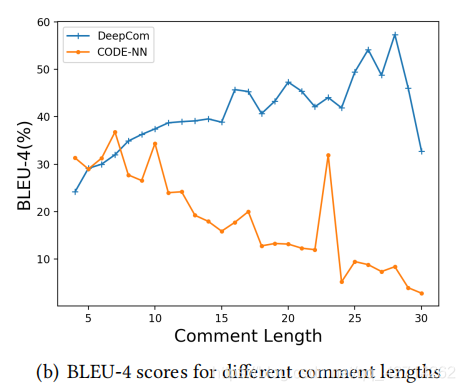
RQ2: How effective is DeepCom to source code and comments of varying lengths?
参考文献
[1]全面解析RNN,LSTM,Seq2Seq,Attention注意力机制:https://wjrsbu.smartapps.cn/zhihu/article?id=135970560&isShared=1&hostname=baiduboxapp&_swebfr=1


















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











