







一文带你入门深度学习优化算法
一般反向传播神经网络一个完整的训练过程就是由前向传播和反向传播组成。其中前向传播较为直观,只要学过了线性代数一般就很好理解,而反向传播没有前向传播这么直观,所涉及的方法也更加的灵活多变。所以,本文就反向传播的四个经典算法进行详细地讲解,希望能带新手入门深度学习。
0. 基础知识
看文章前你需要掌握什么知识?
- 线性代数
- 导数的意义和求导法则
- 清楚神经网络的前向传播过程,知道一般神经网络的参数主要分为:权重参数 w i w_i wi和偏置参数 b i b_i bi两个部分。
从最优化的角度理解神经网络
主要就是理解
hypothesis function、loss function和cost function
不论是用来做分类还是做回归拟合的神经网络都有一个共同的特征,那就是只要给一组特征向量就能够输出对应的结果。这样意味着神经网络其实可以写成这样的形式:
y
^
=
f
(
x
1
,
x
2
,
x
3
,
…
)
\hat{y} = f(x_1,x_2,x_3,\dots)
y^=f(x1,x2,x3,…),而这个函数就被叫做hypothesis function(预测函数)。预测函数里面的参数一般
当神经网络拥有了预测值
y
^
\hat{y}
y^之后又该怎么样去评估它到底预测的准不准呢?这个时候就需要引入loss function和cost function。以拟合为例,我们一般会通过残差平方的一半来度量
l
o
s
s
=
1
2
(
y
−
y
^
)
2
loss = \frac{1}{2}(y-\hat{y})^2
loss=21(y−y^)2,这个就叫做 loss function。而一般情况下神经网络训练的时候往往会用多个样本同时训练,这个时候理所当然地会想到损失函数 cost function 应该由所有样本残差平方和一半的平均值来度量
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
y
−
y
^
)
2
cost =\frac{1}{2m} \sum_{i=1}^{m}(y-\hat{y})^2
cost=2m1∑i=1m(y−y^)2。而神经网络用于分类的时候一般会用交叉熵作为损失函数。总之就是用途不同这三个函数的形式也会发生相应的变化。
从神经网络的前向传播过程可知,我们把cost function中的
y
^
\hat{y}
y^展开,得到了cost其实是关于
w
i
w_i
wi 和
b
i
b_i
bi 的函数,即:
c
o
s
t
=
f
(
w
1
,
w
2
,
w
3
,
…
,
b
1
,
b
2
,
b
3
,
…
)
cost = f(w_1,w_2,w_3,\dots,b_1,b_2,b_3,\dots)
cost=f(w1,w2,w3,…,b1,b2,b3,…)
所以现在我们的问题就转换为怎么样找到合适的
w
i
w_i
wi 和
b
i
b_i
bi 让cost最小? 而反向传播的优化算法正是要干这件事的算法。
1. 梯度下降(Gradient Descent)
随着科技的不断发展,数据量呈现爆炸式地增长。因此,梯度下降的策略也在不断的改变。从批量梯度下降(Batch Gradient Descent)到随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-Batch Gradient Descent)就体现出了数据量对于训练策略的影响。
梯度下降的基本原理
要想理解梯度下降,我们先从一个简单地例子入手:
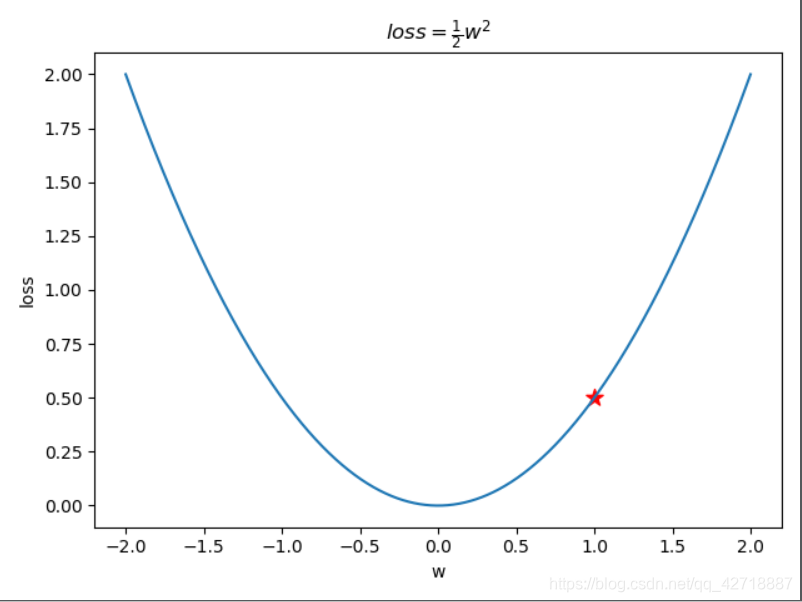
我们把损失函数简化为
l
o
s
s
=
1
2
w
2
loss = \frac{1}{2}w^2
loss=21w2 这样一个二次函数。假设一开始w的初始值被随机赋值为了1,现在我们就要利用梯度下降一步一步地将那颗星星移动到这个函数的最低点(0,0)。
首先,根据高数上面的定义我们知道梯度总是指向函数值下降最快的方向。那么怎么理解这个下降最快的方向呢?
我们先对这个函数求一个导数得到:
∂
l
∂
w
=
w
\frac{\partial l}{\partial w} = w
∂w∂l=w,带入w = 1可以得到
∂
l
∂
w
=
1
\frac{\partial l}{\partial w} = 1
∂w∂l=1。于是我们开始更新w,让 w = w - 1。这样一来w就变成了0,我们也就顺利地到达了这个函数的谷底。(大家可以假定w为负数看看是不是同样也能到达谷底)
上面的推导虽然看起来比较合理,但是忽略了梯度下降中步长的问题,如果求导步子太大了就会让w在谷底的左右震荡,从而始终到不了最低点。所以为了解决这个问题,我们需要引入学习率
α
\alpha
α (一个比较小的值)来控制这个步长。
通过上面的原理介绍,扩展到多元函数的情况,我们就可以得到梯度下降的公式如下:
repeat until convergence{
w
i
=
w
i
−
α
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
w_i = w_i - \alpha \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
wi=wi−α∂wi∂Cost(wi,bi)
b
i
=
b
i
−
α
∂
∂
b
i
C
o
s
t
(
w
i
,
b
i
)
b_i = b_i - \alpha \frac{\partial{}}{\partial{b_i}}Cost(w_i, b_i)
bi=bi−α∂bi∂Cost(wi,bi)}
这里需要注意的是这些参数的更新必须是同时的,如果你的代码不是同时更新参数的话就会导致无法正常的收敛。这一点从多元函数的求导过程就很容易理解。
原理讲完了之后大家可以自己试着求一求前面提到的神经网络的cost function的梯度下降是怎么样的。
梯度下降的策略改变
在以前机器学习的时代就采用的Batch Gradient Descent的策略,即一次梯度下降就将所有的训练数据考虑进去。这一点从sklearn这个机器学习库早期的API中就可以看出来,其中的fit方法就会将全部数据一次性加载到内存中进行训练。但随着深度学习时代的到来,信息呈现爆炸式地增长,要想一次性将所有的训练数据加载到内存中已经变成了一件不可能的事情了。于是就出现了Stochastic Gradient Descent和Mini-Batch Gradient Descent这两两种训练策略。前者就是一次梯度下降只考虑训练集中的一个样本,而后者则是一次梯度下降只考虑训练集中的一部分样本。
随着后面两种策略逐渐成为深度学习时代的主流训练策略,人们逐渐开始意识到虽然这两种策略能够避免一次梯度下降的代价过大的问题,但是又会带来一个新的问题,那就是一次梯度下降后更新的参数从全部训练集的角度来看不一定会让损失函数减小。于是为了解决这个问题,下面几个算法就诞生了。
2. 动量梯度下降
指数加权平均
在学习动量梯度下降之前,我们需要先学习一下指数加权平均:
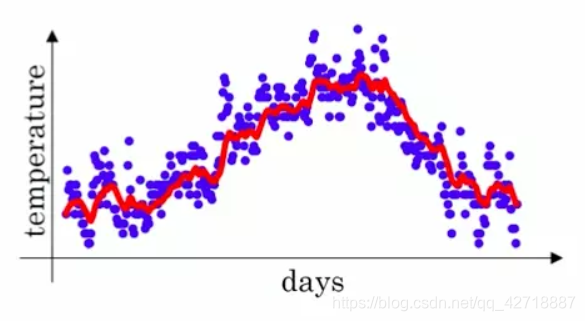
我们拿一个经典的温度趋势提取的例子来介绍指数加权平均。上图的蓝色点就代表着改天的温度值。假设第t天的温度值为
θ
t
\theta_t
θt,我们要做的就是从中提取出那个红色的趋势线。指数加权平均公式如下:
v
t
=
β
v
t
−
1
+
(
1
−
β
)
θ
t
v_t = \beta v_{t-1} + (1-\beta) \theta_t
vt=βvt−1+(1−β)θt
其中,
v
t
v_t
vt就是第t天平滑的结果,
β
\beta
β就是一个控制参数,一般取0.9(
v
t
≈
v_t ≈
vt≈ 前
1
1
−
β
\frac{1}{1-\beta}
1−β1天温度的平均值,如果想知道为什么可以把这个递推式子展开)
从上面的公式就可以看出来,我们通过前几天的平均气温
v
t
v_t
vt来代替
第t天的气温值
θ
t
\theta_t
θt就可以减少数据震荡,从而提取出数据的趋势。
指数加权平均矫正
指数加权平均在初始化的时候一般会取
v
0
=
0
v_0 = 0
v0=0,会导致前面几项的v会特别小。所以,一般需要在该算法的基础上再加上矫正算法:
v
t
c
=
v
t
1
−
β
t
v_t^c = \frac{v_t}{1-\beta^t}
vtc=1−βtvt
这样就可以保证在t很小的时候
v
t
v_t
vt会被放大到合适的数量级。
动量梯度下降原理
前面说到了由于梯度下降策略的改变而产生了新问题,为了让大家更加形象的理解这个问题,我们来看看下面这张图:

那些同心椭圆就是损失函数的等高线图,我们的目的仍然是到达最中间的那个红色点的地方。但是那两种梯度下降的策略会导致损失函数在全局震荡下降而耽误很多时间,那么有没有一种方法能够减小这种震荡呢?结合前面指数加权平均的知识,我们就可以推导出动量梯度下降的公式:
repeat until convergence{
第
t
次
迭
代
的
时
候
第t次迭代的时候
第t次迭代的时候
d
w
i
=
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
dw_i = \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
dwi=∂wi∂Cost(wi,bi)
d
b
i
=
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
db_i = \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
dbi=∂wi∂Cost(wi,bi)
v
d
w
i
,
t
=
β
v
d
w
i
,
t
−
1
+
(
1
−
β
)
d
w
i
v_{dw_i, t} = \beta v_{dw_i, t-1} + (1-\beta)dw_i
vdwi,t=βvdwi,t−1+(1−β)dwi
v
d
b
i
,
t
=
β
v
d
b
i
,
t
−
1
+
(
1
−
β
)
d
b
i
v_{db_i, t} = \beta v_{db_i, t-1} + (1-\beta)db_i
vdbi,t=βvdbi,t−1+(1−β)dbi
w
i
=
w
i
−
α
v
d
w
i
,
t
w_i = w_i - \alpha v_{dw_i, t}
wi=wi−αvdwi,t
b
i
=
b
i
−
α
v
d
b
i
,
t
b_i = b_i - \alpha v_{db_i, t}
bi=bi−αvdbi,t}
从公式中就可以很容易看出来动量梯度下降的更新不再是像普通的梯度下降那样直接减去
d
w
i
、
d
b
i
dw_i、db_i
dwi、dbi,而是通过这两个值计算出动量
v
d
w
i
,
t
、
v
d
b
i
,
t
v_{dw_i, t}、v_{db_i, t}
vdwi,t、vdbi,t再来更新参数。至于为什么叫动量梯度下降,大家可以类比一下物理中的动量,
d
w
i
、
d
b
i
dw_i、db_i
dwi、dbi就是加速度。
3. 均方根反向传播法
这个算法同样也是为了减小每次迭代损失函数的震荡问题,整体思想与动量梯度下降十分相似,下面看公式:
repeat until convergence{
第
t
次
迭
代
的
时
候
第t次迭代的时候
第t次迭代的时候
d
w
i
=
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
dw_i = \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
dwi=∂wi∂Cost(wi,bi)
d
b
i
=
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
db_i = \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
dbi=∂wi∂Cost(wi,bi)
S
d
w
i
,
t
=
β
S
d
w
i
,
t
−
1
+
(
1
−
β
)
d
w
i
2
S_{dw_i, t} = \beta S_{dw_i, t-1} + (1-\beta)dw_i^2
Sdwi,t=βSdwi,t−1+(1−β)dwi2
S
d
b
i
,
t
=
β
S
d
b
i
,
t
−
1
+
(
1
−
β
)
d
b
i
2
S_{db_i, t} = \beta S_{db_i, t-1} + (1-\beta)db_i^2
Sdbi,t=βSdbi,t−1+(1−β)dbi2
w
i
=
w
i
−
α
d
w
i
S
d
w
i
,
t
+
ϵ
w_i = w_i - \alpha \frac{dw_i}{\sqrt{S_{dw_i, t}}+\epsilon}
wi=wi−αSdwi,t+ϵdwi
b
i
=
b
i
−
α
d
b
i
S
d
b
i
,
t
+
ϵ
b_i = b_i - \alpha \frac{db_i}{\sqrt{S_{db_i, t}}+\epsilon}
bi=bi−αSdbi,t+ϵdbi
这个算法就是利用微分平方加权平均数来更新参数,其中的
ϵ
\epsilon
ϵ通常会取一个特别小的数(
1
0
−
8
10^{-8}
10−8)来避免出现除0错误。
4. Adam算法
Adam算法就是将动量梯度下降和均方根传播算法结合起来的一种算法。一般情况下该算法的收敛速度特别快,由于其优异的性能,已经逐步成为深度学习中最常用的算法之一。下面是该算法的公式:
repeat until convergence{
第
t
次
迭
代
的
时
候
第t次迭代的时候
第t次迭代的时候
d
w
i
=
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
dw_i = \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
dwi=∂wi∂Cost(wi,bi)
d
b
i
=
∂
∂
w
i
C
o
s
t
(
w
i
,
b
i
)
db_i = \frac{\partial{}}{\partial{w_i}}Cost(w_i, b_i)
dbi=∂wi∂Cost(wi,bi)
v
d
w
i
,
t
=
β
1
v
d
w
i
,
t
−
1
+
(
1
−
β
1
)
d
w
i
v_{dw_i, t} = \beta_1 v_{dw_i, t-1} + (1-\beta_1)dw_i
vdwi,t=β1vdwi,t−1+(1−β1)dwi
v
d
b
i
,
t
=
β
1
v
d
b
i
,
t
−
1
+
(
1
−
β
1
)
d
b
i
/
/
计
算
动
量
v_{db_i, t} = \beta_1 v_{db_i, t-1} + (1-\beta_1)db_i // 计算动量
vdbi,t=β1vdbi,t−1+(1−β1)dbi//计算动量
S
d
w
i
,
t
=
β
2
S
d
w
i
,
t
−
1
+
(
1
−
β
2
)
d
w
i
2
S_{dw_i, t} = \beta_2 S_{dw_i, t-1} + (1-\beta_2)dw_i^2
Sdwi,t=β2Sdwi,t−1+(1−β2)dwi2
S
d
b
i
,
t
=
β
2
S
d
b
i
,
t
−
1
+
(
1
−
β
2
)
d
b
i
2
/
/
计
算
均
方
根
S_{db_i, t} = \beta_2 S_{db_i, t-1} + (1-\beta_2)db_i^2 // 计算均方根
Sdbi,t=β2Sdbi,t−1+(1−β2)dbi2//计算均方根
v
d
w
i
,
t
c
=
v
d
w
i
,
t
1
−
β
1
t
v_{dw_i, t}^{c} = \frac{v_{dw_i, t}}{1-\beta_1^t}
vdwi,tc=1−β1tvdwi,t
v
d
b
i
,
t
c
=
v
d
b
i
,
t
1
−
β
1
t
v_{db_i, t}^{c} = \frac{v_{db_i, t}}{1-\beta_1^t}
vdbi,tc=1−β1tvdbi,t
S
d
w
i
,
t
c
=
S
d
w
i
,
t
1
−
β
2
t
S_{dw_i, t}^{c} = \frac{S_{dw_i, t}}{1-\beta_2^t}
Sdwi,tc=1−β2tSdwi,t
S
d
b
i
,
t
c
=
S
d
b
i
,
t
1
−
β
2
t
/
/
修
正
S_{db_i, t}^{c} = \frac{S_{db_i, t}}{1-\beta_2^t} // 修正
Sdbi,tc=1−β2tSdbi,t//修正
w
i
=
w
i
−
α
v
d
w
i
,
t
c
S
d
w
i
,
t
+
ϵ
w_i = w_i - \alpha \frac{ v_{dw_i, t}^{c}}{\sqrt{S_{dw_i, t}}+\epsilon}
wi=wi−αSdwi,t+ϵvdwi,tc
b
i
=
b
i
−
α
v
d
b
i
,
t
c
S
d
b
i
,
t
+
ϵ
/
/
参
数
更
新
b_i = b_i - \alpha \frac{v_{db_i, t}^{c}}{\sqrt{S_{db_i, t}}+\epsilon} // 参数更新
bi=bi−αSdbi,t+ϵvdbi,tc//参数更新
}
5. 吴恩达机器学习python实现
我自己用python实现的吴恩达机器学习的,求个star,O(∩_∩)O~~
github地址,点这里!

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









