






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自:计算机视觉life
前言
 在SLAM系统中增加更多的相机可以提高鲁棒性和准确性,但会使视觉前端的设计变得非常复杂。因此,文献中的大多数系统是为特定的相机配置定制的。在这项工作中,我们的目标是一个适用于任意多相机设置的自适应SLAM系统。为此,我们重温了可视化SLAM中的几个常见构建块。特别是,我们提出了一个自适应初始化方案,一个传感器无关的信息论的关键帧选择算法,和一个可扩展的基于体素的地图。这些技术对实际的相机设置做了很少的假设,并且更喜欢基于理论的方法而不是启发式方法。通过这些修改,我们采用了最先进的视觉里程计,实验结果表明,修改后的流水线可以适应各种各样的摄像机设置(例如,一个实验中有2到6个摄像机),而不需要传感器特定的修改或调整。
在SLAM系统中增加更多的相机可以提高鲁棒性和准确性,但会使视觉前端的设计变得非常复杂。因此,文献中的大多数系统是为特定的相机配置定制的。在这项工作中,我们的目标是一个适用于任意多相机设置的自适应SLAM系统。为此,我们重温了可视化SLAM中的几个常见构建块。特别是,我们提出了一个自适应初始化方案,一个传感器无关的信息论的关键帧选择算法,和一个可扩展的基于体素的地图。这些技术对实际的相机设置做了很少的假设,并且更喜欢基于理论的方法而不是启发式方法。通过这些修改,我们采用了最先进的视觉里程计,实验结果表明,修改后的流水线可以适应各种各样的摄像机设置(例如,一个实验中有2到6个摄像机),而不需要传感器特定的修改或调整。

贡献
自适应初始化方案。
与传感器无关的信息论关键帧选择算法。
可扩展的基于体素的地图管理方法。

图1 多相机系统在感知算法方面实现了卓越的性能,并被广泛应用于现实世界的应用中,如全向测绘、自主无人机和虚拟现实耳机。为了便于在SLAM中使用这种系统,我们提出了几个通用设计来自动适应任意多相机系统。

图2 两个摄像机之间立体重叠检查的图示,Ci和Cj。蓝星是相机I像面上的采样点,绿星是成功投影到相机j的3D点,红星是从像面上掉下来的点。

图3 EuRoC MH 01中3次运行的负熵演化。每次运行的E(T)以不同的颜色显示,红点表示某帧被选为关键帧的位置。插入关键帧后,E(T)增加,随着传感器远离地图,e(T)减少。
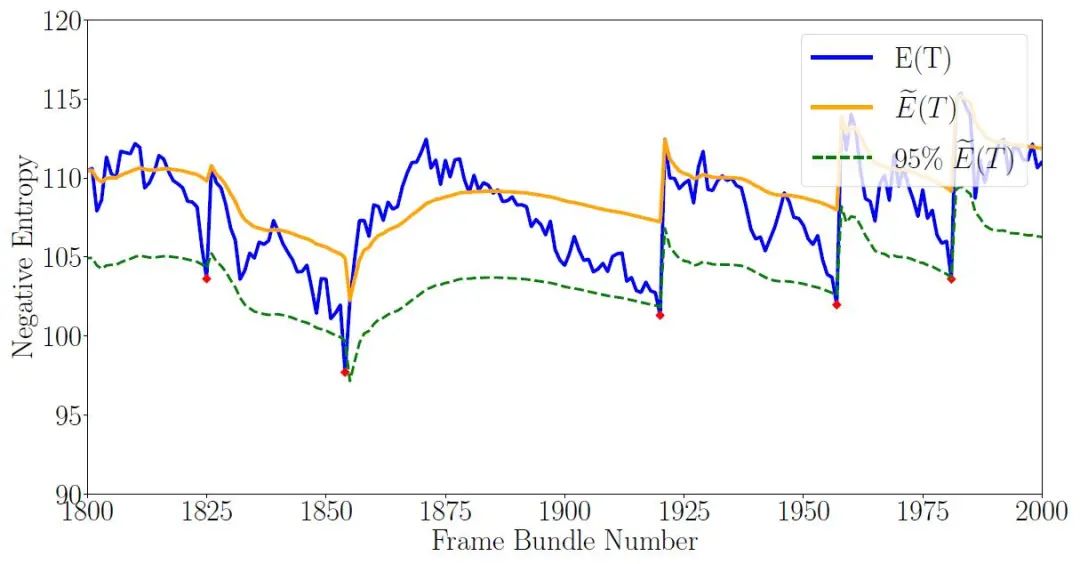
图4 运行平均E(T)和关键帧选择。运行平均过滤器(黄色)跟踪自最后一个关键帧以来的定位质量。当当前帧的负熵(蓝色)低于运行平均值的某个百分比(绿色虚线)时,将选择一个新的关键帧(红点),并重置运行平均值过滤器。

图5 模拟环境中的模拟图8轨迹。该轨迹是通过用5个摄像机运行调整后的VIO管道来估计的。单目设置丢失轨迹的部分用红色标记。品红色点是SLAM系统跟踪的地标。

图6 5次运行模拟中的总体相对平移误差。
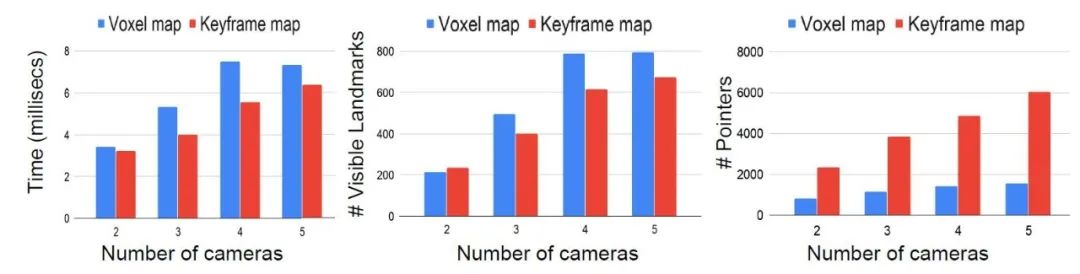
图7 针对不同的相机配置(2到5个摄像机),将建议的体素图与标准关键帧进行比较。左:VIO前端总时间。中间:从地图中检索匹配的地标。右侧:指向地标位置的引用/指针的数量。

图8 含BA的EuRoC数据集的相对平移误差百分比。
表1 EuRoC数据集的RMSE中值(米)超过5次。以粗体突出显示的最低误差。

表2 EuRoC序列中5次运行的关键帧平均数。

图3 单目和立体设置的不同关键帧选择标准的关键帧平均数。
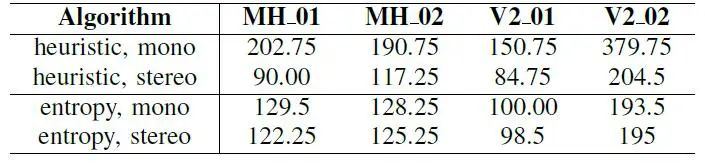
表4 科学园日序列中多相机管道的不同轨迹误差度量。第一行包含完整轨迹的绝对RMSE(547.488米)


图9 科学园日序列中FRB配置的估计轨迹和基本轨迹的俯视图。

Abstract
Adding more cameras to SLAM systems improves robustness and accuracy but complicates the design of the visual front-end significantly. Thus, most systems in the literature are tailored for specific camera configurations. In this work, we aim at an adaptive SLAM system that works for arbitrary multi-camera setups. To this end, we revisit several common building blocks in visual SLAM. In particular, we propose an adaptive initialization scheme, a sensor-agnostic, informationtheoretic keyframe selection algorithm, and a scalable voxelbased map. These techniques make little assumption about the actual camera setups and prefer theoretically grounded methods over heuristics. We adapt a state-of-the-art visualinertial odometry with these modifications, and experimental results show that the modified pipeline can adapt to a wide range of camera setups (e.g., 2 to 6 cameras in one experiment) without the need of sensor-specific modifications or tuning.
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









