






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达本文转载自:OpenCV学堂
在进行模型训练时,对训练进行可视化可以帮助我们更直观查看模型训练情况,从而更容易发现问题。这篇文章将分享在模型训练过程中用到的可视化方法,本文用到的方法为tensorboard可视化方法。
使用tensorboard可视化大致分为3个步骤
1、导入tensorboard并创建SummaryWriter实例
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='./log')2、把需要可视化的数据加入日志文件,我们用到的API为
| API | 功能 |
|---|---|
| SummaryWriter.add_scalar | 加入标量数据 |
| SummaryWriter.add_scalars | 加入多个标量数据 |
| SummaryWriter.add_histgram | 加入直方图数据 |
| SummaryWriter.add_image | 加入图像数据 |
| SummaryWriter.add_graph | 对模型进行可视化 |
3、启动tensorboard,对指定目录的日志文件进行可视化
tensorboard --logdir=./log标量数据可视化
标量数据可视化可以用于对loss和accurcy的可视化
add_scalar(tag, scalar_value, global_step=None, walltime=None)
| 参数 | 说明 |
|---|---|
| tag (string) | 数据名称,不同名称的数据使用不同曲线展示 |
| scalar_value (float) | 数字常量值 |
| global_step (int, optional) | 训练的 step |
| walltime (float, optional) | 记录发生的时间,默认为 time.time() |
多个标量数据在一张图上进行可视化
add_scalars(tag, dict, global_step=None, walltime=None)
| 参数 | 说明 |
|---|---|
| dict | tag和value组成的字典结构 |
| 其他参数 | 同add_scalar |
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='./log')
flag = 0
if flag :
for x in range(100):
# 把x*2的数据加入标签y=2x的曲线
writer.add_scalar(tag='y=2x',scalar_value=x*2,global_step=x)
# 把2**x的数据加入标签y=pow(2,x)的曲线
writer.add_scalar(tag='y=pow(2,x)',scalar_value=2**x,global_step=x)
# 把x*sin(x)和x*cos(x)的数据加入data/scalar_group的标签组中,即
# 两个曲线绘制在一张图中
writer.add_scalars(tag='data/scalar_group',{'xsinx': x*np.sin(x),
'xcosx':x*np.cos(x)}, x)执行以上代码后再执行tensorboard --logdir=./
可视化结果如下:

数据分布可视化
数据分布的可视化可以查看数据的分布情况,用于可训练参数和可训练参数的梯度 时可以排查梯度消失和梯度爆炸的情况。
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
| 参数 | 说明 |
|---|---|
| tag (string) | 数据名称 |
| values (torch.Tensor, numpy.array, or string/blobname) | 用来构建直方图的数据 |
| global_step (int, optional) | 训练的 step |
| bins (string, optional) | 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 该参数决定了分桶的方式 |
| walltime (float, optional) | 记录发生的时间,默认为 time.time() |
| max_bins (int, optional) | 最大分桶数 |
示例代码:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='./log')
flag = 0
if flag :
for x in range(10):
data_1 = np.arange(1000)
data_2 = np.random.normal(size=1000)
writer.add_histogram("data1",data_1,x)
writer.add_histogram('data2',data_2,x)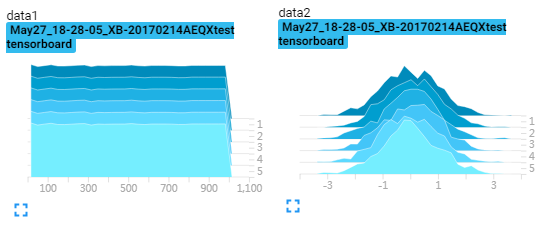
图像可视化
add_image(tag,img_tensor,global_step,dataformat)
| 参数 | 说明 |
|---|---|
| tag | 图像的标签名,图像的唯一标识 |
| img_tensor | 图像数据,注意:如果图像数据在0-1之间自动乘以255,如果大于1则不乘以255 |
| global_step | x轴 |
| dataformats | 数据形式,chw,hwc,hw |
示例代码:(使用cifar10分类卷积网络训练代码)
from torchvision import datasets
import torchvision.transforms as transforms
from torch.utils.data.sampler import SubsetRandomSampler
# number of subprocesses to use for data loading
num_workers = 0
# 每批加载16张图片
batch_size = 16
# percentage of training set to use as validation
valid_size = 0.2
# 将数据转换为torch.FloatTensor,并标准化。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 选择训练集与测试集的数据
train_data = datasets.CIFAR10('data', train=True,
download=True, transform=transform)
test_data = datasets.CIFAR10('data', train=False,
download=True, transform=transform)
# obtain training indices that will be used for validation
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(valid_size * num_train))
train_idx, valid_idx = indices[split:], indices[:split]
# define samplers for obtaining training and validation batches
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
# prepare data loaders (combine dataset and sampler)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,sampler=train_sampler, num_workers=num_workers)
valid_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, sampler=valid_sampler, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, num_workers=num_workers)
# 对训练输入数据进行可视化
b_img,b_label=iter(train_data).next()
iter = 1
for img in b_img:
# 乘以偏差
img = img.mul(torch.Tensor(np.array([0.5, 0.5, 0.5]).reshape(-1,1,1)))
# 加上均值
img = img.add(torch.Tensor(np.array([0.5, 0.5, 0.5]).reshape(-1,1,1)))
# 加入图像数据
writer.add_image('input',img, iter)
iter += 1可以拖动图片上方的红线,就可以看到不同step的图像了
对于多张图片的可以使用torchvision.utils.make_grid API把多张图片拼到一张图中方便查看。(make_grid详细参数参考make_grid帮助文档)
修改以上代码:
#导入make_grid
from torchvision.utils import make_grid
# 对训练输入数据进行可视化
b_img,b_label=iter(train_data).next()
# b_img:batch image,4:把图像分成4行 ,normalize=True图像进行了标准化
gimg=make_grid(b_img,4,normalize=True)
# 加入图像数据
writer.add_image("data_input",gimg,1)效果图
使用图像可视化对模型输出特征图进行可视化
这里我们需要用到pytorch的hook函数机制,通过注册hook函数获取特征图并进行可视化。
示例代码(使用cifar10分类卷积网络训练代码)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积层 (32x32x3的图像)
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
# 卷积层(16x16x16)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
# 卷积层(8x8x32)
self.conv3 = nn.Conv2d(32, 64, 3, padding=1)
# 最大池化层
self.pool = nn.MaxPool2d(2, 2)
# linear layer (64 * 4 * 4 -> 500)
self.fc1 = nn.Linear(64 * 4 * 4, 500)
# linear layer (500 -> 10)
self.fc2 = nn.Linear(500, 10)
# dropout层 (p=0.3)
self.dropout = nn.Dropout(0.3)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
# flatten image input
x = x.view(-1, 64 * 4 * 4)
# add dropout layer
x = self.dropout(x)
# add 1st hidden layer, with relu activation function
x = F.relu(self.fc1(x))
# add dropout layer
x = self.dropout(x)
# add 2nd hidden layer, with relu activation function
x = self.fc2(x)
return x
# create a complete CNN
model = Net()
print(model)
# 定义hook函数
conv_fmap_ls = []
def conv1_fmap_hook(model,input,output):
conv_fmap_ls.append(output)
# 注册hook函数,作为示例只对conv1的输出进行记录
model.conv1.register_forward_hook(conv1_fmap_hook)
# 使用GPU
if train_on_gpu:
model.cuda()
import torch.optim as optim
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降,学习率lr=0.01
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型的次数
n_epochs = 30
valid_loss_min = np.Inf # track change in validation loss
iter = 0
for epoch in range(1, n_epochs + 1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# 训练集的模型 #
###################
model.train()
for data, target in train_loader:
iter += 1
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item() * data.size(0)
#记录feature map
if len(conv_fmap_ls)>0:
# 取出conv1的输出
fm = conv_fmap_ls[0]
#增维,(batch_num,output_channel,width,height)->(batch_num,output_channel,1,width,height)
fm = fm.unsqueeze(2)
b,output_c,c,w,h = fm.size()
#改变形状
fm = fm.view(-1,c,w,h)
# 拼图
gm = make_grid(fm, nrow=16, normalize=True)
# 添加图像记录
writer.add_image("conv1_feature_map", gm, iter)
conv_fmap_ls.clear()效果图:
模型可视化
add_graph(model,input_to_model,verbose)
| 参数 | 说明 |
|---|---|
| model | 模型变量,必须是nn.Module |
| input_to_model | 模型的输入数据 |
| verbose | 是否打印计算图信息 |
对上方使用的模型进行可视化:
model = Net()
input_data = torch.rand(32, 3, 32, 32)
writer.add_graph(model, input_to_model=(input_data,))效果图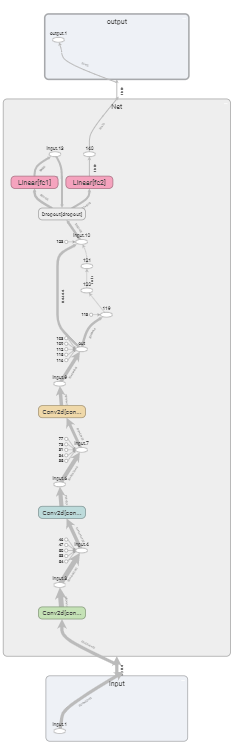
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 2130
2130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









