






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
数据扩充是一种增加数据集多样性的技术,无需收集更多真实数据,但仍有助于提高模型精度并防止模型过拟合。
在本文中,你将学习使用Python和OpenCV为对象检测任务实现最流行、最高效的数据扩充过程。
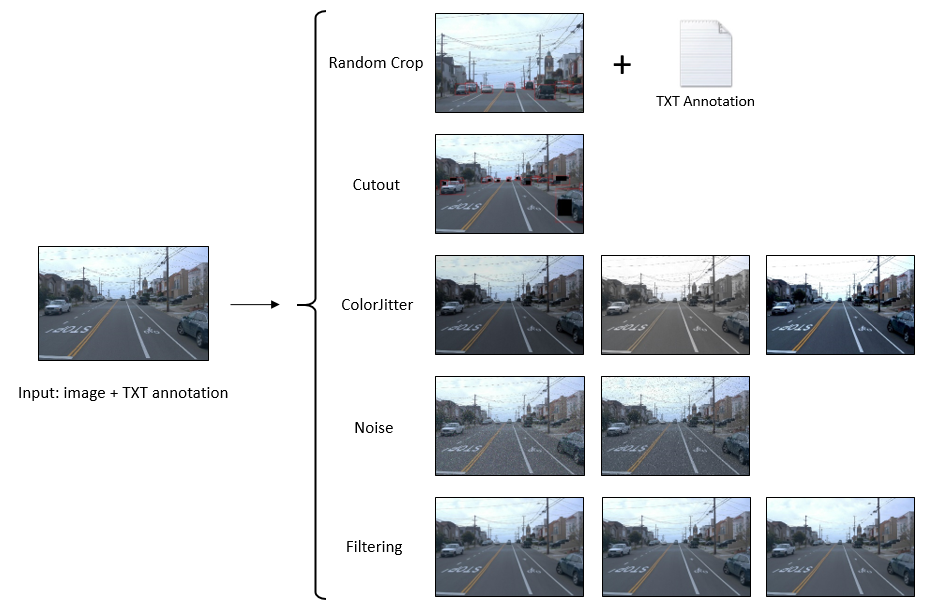
即将引入的一组数据扩充方法包括:
随机裁剪
Cutout
颜色抖动
增加噪音
过滤
首先,在继续之前,让我们导入几个库并准备一些必要的子例程。
import os
import cv2
import numpy as np
import random
def file_lines_to_list(path):
'''
### 在TXT文件里的行转换为列表 ###
path: 文件路径
'''
with open(path) as f:
content = f.readlines()
content = [(x.strip()).split() for x in content]
return content
def get_file_name(path):
'''
### 获取Filepath的文件名 ###
path: 文件路径
'''
basename = os.path.basename(path)
onlyname = os.path.splitext(basename)[0]
return onlyname
def write_anno_to_txt(boxes, filepath):
'''
### 给TXT文件写注释 ###
boxes: format [[obj x1 y1 x2 y2],...]
filepath: 文件路径
'''
txt_file = open(filepath, "w")
for box in boxes:
print(box[0], int(box[1]), int(box[2]), int(box[3]), int(box[4]), file=txt_file)
txt_file.close()下面的图片是在这篇文章中使用的示例图片。

随机裁剪
随机裁剪随机选择一个区域并进行裁剪以生成新的数据样本,裁剪后的区域应具有与原始图像相同的宽高比,以保持对象的形状。

从上图中,左侧图像表示具有边界框(红色)的原始图像,通过裁剪橙色框内的区域创建一个新样本作为右侧图像。
在新示例的注释中,将删除与左侧图像中的橙色框不重叠的所有对象,并细化位于橙色框边界上的对象的坐标,使其适合新图像示例。原始图像的随机裁剪输出为新裁剪图像及其注释。
def randomcrop(img, gt_boxes, scale=0.5):
'''
### 随机裁剪 ###
img: 图像
gt_boxes: format [[obj x1 y1 x2 y2],...]
scale: 裁剪区域百分比
'''
# 裁剪
height, width = int(img.shape[0]*scale), int(img.shape[1]*scale)
x = random.randint(0, img.shape[1] - int(width))
y = random.randint(0, img.shape[0] - int(height))
cropped = img[y:y+height, x:x+width]
resized = cv2.resize(cropped, (img.shape[1], img.shape[0]))
# 修改注释
new_boxes=[]
for box in gt_boxes:
obj_name = box[0]
x1 = int(box[1])
y1 = int(box[2])
x2 = int(box[3])
y2 = int(box[4])
x1, x2 = x1-x, x2-x
y1, y2 = y1-y, y2-y
x1, y1, x2, y2 = x1/scale, y1/scale, x2/scale, y2/scale
if (x1<img.shape[1] and y1<img.shape[0]) and (x2>0 and y2>0):
if x1<0: x1=0
if y1<0: y1=0
if x2>img.shape[1]: x2=img.shape[1]
if y2>img.shape[0]: y2=img.shape[0]
new_boxes.append([obj_name, x1, y1, x2, y2])
return resized, new_boxesCutout
Terrance DeVries和Graham W.Taylor在2017年的论文中介绍了Cutout,它是一种简单的正则化技术,用于在训练过程中随机屏蔽输入的方块区域,可用于提高卷积神经网络的鲁棒性和整体性能。
这种方法不仅非常容易实现,而且还表明它可以与现有形式的数据扩充和其他正则化工具结合使用,以进一步提高模型性能。
如本文所述,剪切用于提高图像识别(分类)的准确性,因此,如果我们将相同的方案部署到对象检测数据集中,可能会导致丢失对象的问题,尤其是小对象。
在下图中,cutout区域(黑色区域)内的大量小对象被移除,这不符合数据扩充的精神。
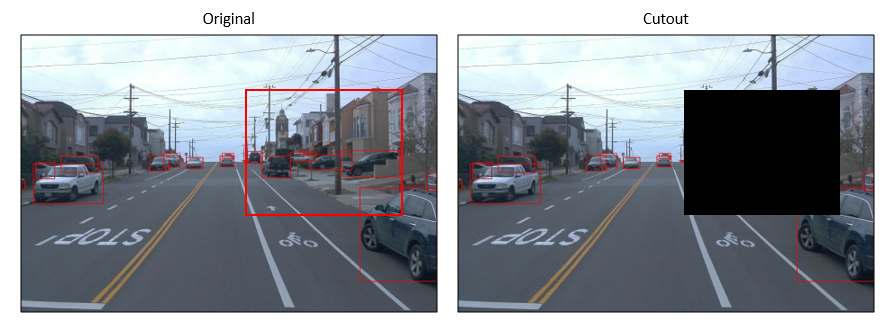
为了使这种方式适用于对象检测,我们可以进行简单的修改,而不是仅使用一个蒙版并将其放置在图像中的随机位置。
当我们随机选择一半数量的对象并将剪切应用于这些对象区域时,效果会更好。增强图像如下图中的右图所示。
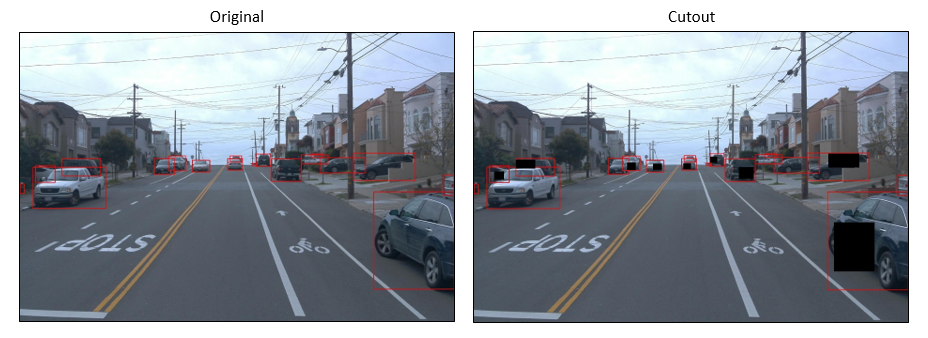
剪切输出是新生成的图像,我们不移除对象或更改图像大小,则生成图像的注释与原始图像相同。
def cutout(img, gt_boxes, amount=0.5):
'''
### Cutout ###
img: 图像
gt_boxes: format [[obj x1 y1 x2 y2],...]
amount: 蒙版数量/对象数量
'''
out = img.copy()
ran_select = random.sample(gt_boxes, round(amount*len(gt_boxes)))
for box in ran_select:
x1 = int(box[1])
y1 = int(box[2])
x2 = int(box[3])
y2 = int(box[4])
mask_w = int((x2 - x1)*0.5)
mask_h = int((y2 - y1)*0.5)
mask_x1 = random.randint(x1, x2 - mask_w)
mask_y1 = random.randint(y1, y2 - mask_h)
mask_x2 = mask_x1 + mask_w
mask_y2 = mask_y1 + mask_h
cv2.rectangle(out, (mask_x1, mask_y1), (mask_x2, mask_y2), (0, 0, 0), thickness=-1)
return out颜色抖动
ColorJitter是另一种简单的图像数据增强,我们可以随机改变图像的亮度、对比度和饱和度。
我相信这个技术很容易被大多数读者理解。

def colorjitter(img, cj_type="b"):
'''
### 不同的颜色抖动 ###
img: 图像
cj_type: {b: brightness, s: saturation, c: constast}
'''
if cj_type == "b":
# value = random.randint(-50, 50)
value = np.random.choice(np.array([-50, -40, -30, 30, 40, 50]))
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
if value >= 0:
lim = 255 - value
v[v > lim] = 255
v[v <= lim] += value
else:
lim = np.absolute(value)
v[v < lim] = 0
v[v >= lim] -= np.absolute(value)
final_hsv = cv2.merge((h, s, v))
img = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2BGR)
return img
elif cj_type == "s":
# value = random.randint(-50, 50)
value = np.random.choice(np.array([-50, -40, -30, 30, 40, 50]))
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
if value >= 0:
lim = 255 - value
s[s > lim] = 255
s[s <= lim] += value
else:
lim = np.absolute(value)
s[s < lim] = 0
s[s >= lim] -= np.absolute(value)
final_hsv = cv2.merge((h, s, v))
img = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2BGR)
return img
elif cj_type == "c":
brightness = 10
contrast = random.randint(40, 100)
dummy = np.int16(img)
dummy = dummy * (contrast/127+1) - contrast + brightness
dummy = np.clip(dummy, 0, 255)
img = np.uint8(dummy)
return img增加噪声
在一般意义上,噪声被认为是图像中的一个意外因素,然而,几种类型的噪声(例如高斯噪声、椒盐噪声)可用于数据增强,在深度学习中添加噪声是一种非常简单和有益的数据增强方法。
在下面的示例中,为了增强数据,将高斯噪声和椒盐噪声添加到原始图像中。

对于那些无法识别高斯噪声和椒盐噪声之间差异的人,高斯噪声的值范围为0到255,具体取决于配置,因此,在RGB图像中,高斯噪声像素可以是任何颜色。
相比之下,椒盐噪波像素只能有两个值0或255,分别对应于黑色(PEPER)或白色(salt)。
def noisy(img, noise_type="gauss"):
'''
### 添加噪声 ###
img: 图像
cj_type: {gauss: gaussian, sp: salt & pepper}
'''
if noise_type == "gauss":
image=img.copy()
mean=0
st=0.7
gauss = np.random.normal(mean,st,image.shape)
gauss = gauss.astype('uint8')
image = cv2.add(image,gauss)
return image
elif noise_type == "sp":
image=img.copy()
prob = 0.05
if len(image.shape) == 2:
black = 0
white = 255
else:
colorspace = image.shape[2]
if colorspace == 3: # RGB
black = np.array([0, 0, 0], dtype='uint8')
white = np.array([255, 255, 255], dtype='uint8')
else: # RGBA
black = np.array([0, 0, 0, 255], dtype='uint8')
white = np.array([255, 255, 255, 255], dtype='uint8')
probs = np.random.random(image.shape[:2])
image[probs < (prob / 2)] = black
image[probs > 1 - (prob / 2)] = white
return image滤波
本文介绍的最后一个数据扩充过程是滤波。与添加噪声类似,滤波也简单且易于实现。
实现中使用的三种类型的滤波包括模糊(平均)、高斯和中值。

def filters(img, f_type = "blur"):
'''
### 滤波 ###
img: 图像
f_type: {blur: blur, gaussian: gaussian, median: median}
'''
if f_type == "blur":
image=img.copy()
fsize = 9
return cv2.blur(image,(fsize,fsize))
elif f_type == "gaussian":
image=img.copy()
fsize = 9
return cv2.GaussianBlur(image, (fsize, fsize), 0)
elif f_type == "median":
image=img.copy()
fsize = 9
return cv2.medianBlur(image, fsize)总结
在这篇文章中,向大家介绍了一个关于为对象检测任务实现数据增强的教程。你们可以在这里找到完整实现。https://github.com/tranleanh/data-augmentation
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~













 2169
2169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









