






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达源代码:https://github.com/wenyyu/ImageAdaptive-YOLO
作者:Edison_G
最近开车发现雾天和晚上视线不是很清楚,让我联想到计算机视觉领域,是不是也是因为这种环境情况,导致最终的模型检测效果不好。最近正好看了一篇文章,说恶劣天气下的目标检测,接下来我们一起深入了解下。
一、前言
尽管基于深度学习的目标检测方法在传统数据集上取得了可喜的结果,但从恶劣天气条件下捕获的低质量图像中定位目标仍然具有挑战性。现有方法要么难以平衡图像增强和目标检测的任务,要么经常忽略对检测有益的潜在信息。

为了缓解这个问题,有研究者提出了一种新颖的图像自适应YOLO (IA-YOLO) 框架,其中每个图像都可以自适应增强以获得更好的检测性能。
二、背景及相关目标检测回顾
基于CNN的方法已在目标检测中盛行。它们不仅在基准数据集上取得了可喜的性能,而且还被部署在自动驾驶等实际应用中。由于输入图像的域偏移,由高质量图像训练的一般目标检测模型在恶劣的天气条件下(例如,有雾和暗光)往往无法获得令人满意的结果。Narasimhan和Nayar以及You等人提出在恶劣天气下拍摄的图像可以分解为干净的图像及其对应的天气信息,而恶劣天气下的图像质量下降主要是由于天气信息和物体之间的相互作用造成的,这导致检测性能差。

上图显示了雾天条件下目标检测的示例。可以看出,如果图像可以根据天气状况进行适当的增强,则可以恢复更多有关原始模糊目标和错误识别目标的潜在信息。

为了解决这个具有挑战性的问题,Huang、Le和Jaw(DSNet: Joint semantic learning for object detection in inclement weather conditions)采用了两个子网络来联合学习可见性增强和目标检测,其中通过共享特征提取层来减少图像退化的影响。然而,在训练期间很难调整参数以平衡检测和恢复之间的权重。另一种方法是通过使用图像去雾(Multi-Scale Boosted Dehazing Network with Dense Feature Fusion;GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing)和图像增强(Zero-reference deep curve estimation for low-light image enhancement)等现有方法对图像进行预处理来淡化天气特定信息的影响。然而,这些方法必须包含复杂的图像恢复网络,需要在像素级监督下单独训练。这需要手动标记要恢复的图像。这个问题也可以被视为无监督的domain adaptation任务。与具有清晰图像(源图像)的训练检测器相比,假设在恶劣天气下捕获的图像(目标图像)具有分布偏移。这些方法大多采用domain adaptation原则,侧重于对齐两个分布的特征,而通常忽略了基于天气的图像恢复过程中可以获得的潜在信息。

·
亮点
具体来说,研究者提出了一个可微分图像处理 (DIP) 模块来考虑YOLO检测器的不利天气条件,其参数由小型卷积神经网络(CNN-PP)预测。以端到端的方式联合学习CNN-PP和YOLOv3,这确保了CNN-PP可以学习适当的DIP,以弱监督的方式增强图像以进行检测。提出的IA-YOLO方法可以在正常和不利的天气条件下自适应地处理图像。实验结果非常令人振奋,证明了提出的IA-YOLO方法在有雾和弱光场景中的有效性。
三、新框架分析
接下来我们直接开始分析新框架。
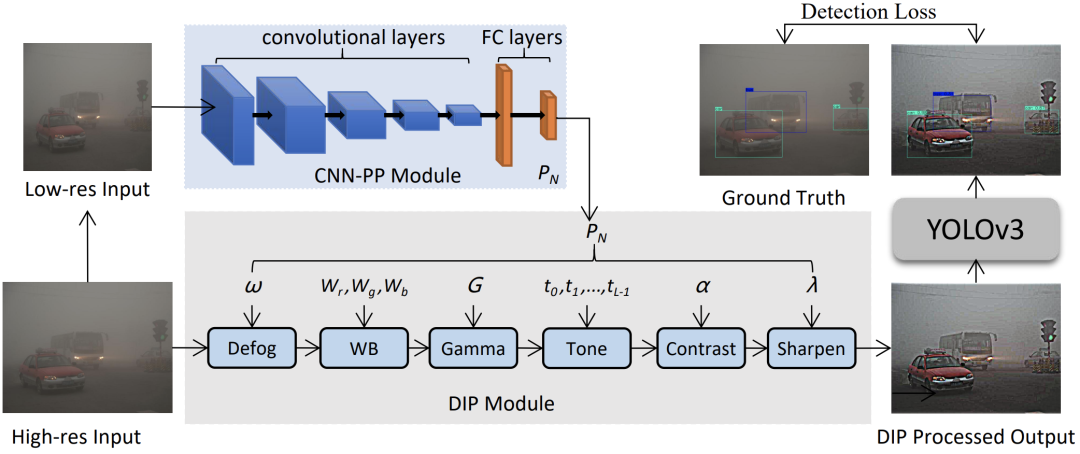
在恶劣天气条件下拍摄的图像,由于天气特定信息的干扰,导致目标检测困难。为了应对这一挑战,研究者建议通过删除特定天气信息并揭示更多潜在信息来构建图像自适应检测框架。如上图所示,整个pipeline由基于CNN的参数预测器(CNNPP)、可微分图像处理模块(DIP)和检测网络组成。
首先将输入图像resize为256×256的大小,并将其输入CNN-PP以预测DIP的参数。然后,将DIP模块过滤后的图像作为YOLOv3检测器的输入。提出了一种具有检测损失的端到端混合数据训练方案,以便CNN-PP可以学习适当的DIP以弱监督的方式增强图像以进行目标检测。
DIP Module
对于CNN-PP基于梯度的优化,过滤器应该是可微的,以允许通过反向传播来训练网络。由于CNN在处理高分辨率图像(例如4000×3000)时会消耗大量的计算资源,研究者从下采样的256×256大小的低分辨率图像中学习滤波器参数,然后将相同的滤波器应用于原始分辨率的图像。因此,这些过滤器需要独立于图像分辨率。
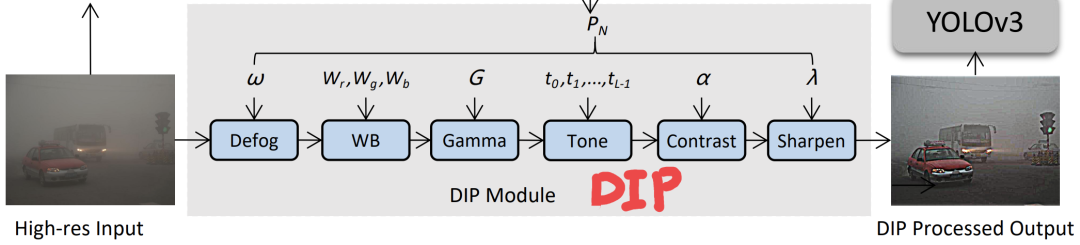
新提出的DIP模块由六个具有可调超参数的可微滤波器组成,包括去雾、白平衡 (WB)、Gamma、对比度、色调和锐化。例如WB、Gamma、对比度和色调,可以表示为逐像素过滤器。因此,研究者设计的过滤器可以分为去雾、像素过滤和锐化。在这些滤镜中,Defog滤镜是专门为有雾场景设计的。
CNN-PP Module
在图像信号处理 (ISP) pipeline中,通常采用一些可调滤波器来增强图像,其超参数由经验丰富的工程师通过visual inspection手动调整。通常,这样的调整过程对于为广泛的场景找到合适的参数是非常笨拙和昂贵的。为了解决这个限制,研究者建议使用一个小的CNN作为参数预测器来估计超参数,这是非常有效的。
Detection Network Module
最终选择one-stage检测器YOLOv3作为检测网络,它广泛用于实际应用,包括图像编辑、安全监控、人群检测和自动驾驶。它通过对多尺度特征图进行预测来实现多尺度训练,从而进一步提高检测精度,尤其是对于小物体。 采用与原始YOLOv3相同的网络架构和损失函数。
四、实验及可视化
整个算法流程可以总结为如下伪代码:

实验1
Performance comparison on foggy images
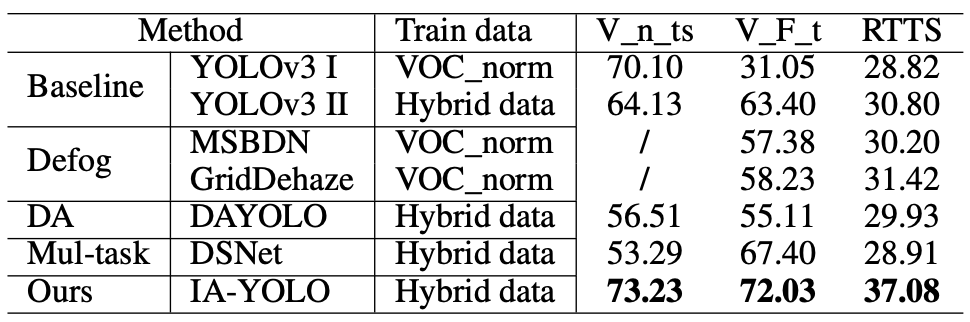


YOLOv3和IA-YOLO比较
实验2
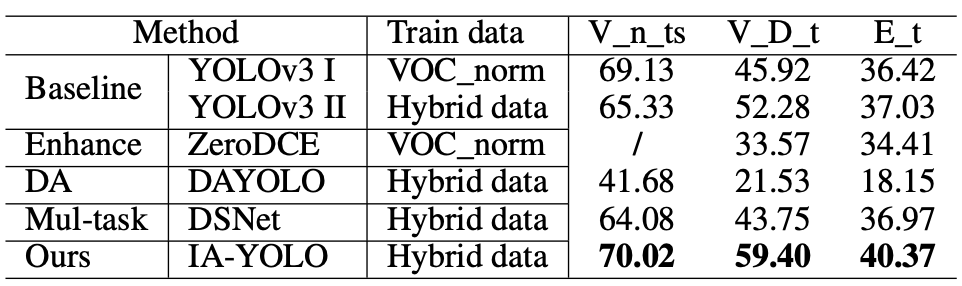
Performance comparison on low-light images
实验3
Detection results by different methods on real-world RTTS foggy images

实验4
Detection results of different methods on synthetic VOC_Dark_test images

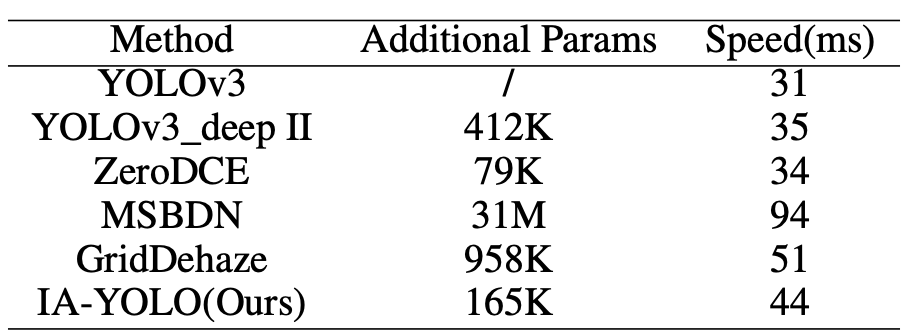
Efficiency analysis on the compared methods
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









