






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
编者荐语
作者将使用 Python 和 PyTorch 线性变换函数对其进行测试。
转载自丨DeepHub IMBA
GPU 计算与 CPU 相比能够快多少?在本文中,我将使用 Python 和 PyTorch 线性变换函数对其进行测试。
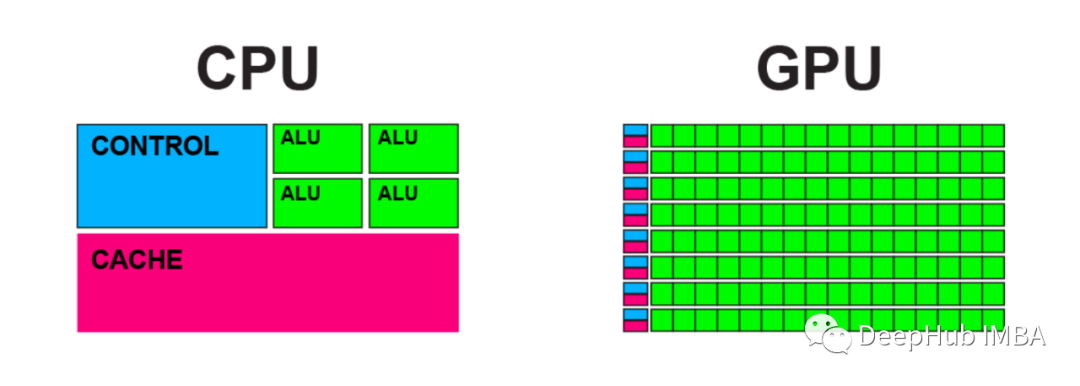
以下是测试机配置:
CPU:英特尔 i7 6700k (4c/8t) GPU:RTX 3070 TI(6,144 个 CUDA 核心和 192 个 Tensor 核心) 内存:32G 操作系统:Windows 10。
无论是cpu和显卡都是目前常见的配置,并不是顶配(等4090能够正常发货后我们会给出目前顶配的测试结果)。
NVIDIA GPU 术语解释
CUDA 是Compute Unified Device Architecture的缩写。可以使用 CUDA 直接访问 NVIDIA GPU 指令集,与专门为构建游戏引擎而设计的 DirectX 和 OpenGL 不同,CUDA 不需要用户理解复杂的图形编程语言。但是需要说明的是CUDA为N卡独有,所以这就是为什么A卡对于深度学习不友好的原因之一。
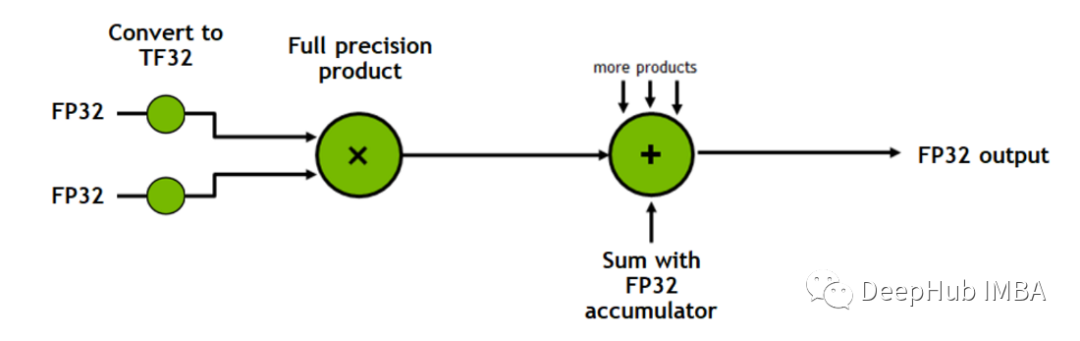
Tensor Cores是加速矩阵乘法过程的处理单元。
例如,使用 CPU 或 CUDA 将两个 4×4 矩阵相乘涉及 64 次乘法和 48 次加法,每个时钟周期一次操作,而Tensor Cores每个时钟周期可以执行多个操作。

上面的图来自 Nvidia 官方对 Tensor Cores 进行的介绍视频
CUDA 核心和 Tensor 核心之间有什么关系?Tensor Cores 内置在 CUDA 核心中,当满足某些条件时,就会触发这些核心的操作。
测试方法
GPU的计算速度仅在某些典型场景下比CPU快。在其他的一般情况下,GPU的计算速度可能比CPU慢!但是CUDA在机器学习和深度学习中被广泛使用,因为它在并行矩阵乘法和加法方面特别出色。
上面的操作就是我们常见的线性操作,公式是这个
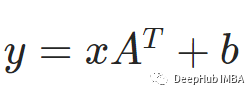
这就是PyTorch的线性函数torch.nn.Linear的操作。可以通过以下代码将2x2矩阵转换为2x3矩阵:
import torch
in_row,in_f,out_f = 2,2,3
tensor = torch.randn(in_row,in_f)
l_trans = torch.nn.Linear(in_f,out_f)
print(l_trans(tensor))CPU 基线测试
在测量 GPU 性能之前,我需要线测试 CPU 的基准性能。
为了给让芯片满载和延长运行时间,我增加了in_row、in_f、out_f个数,也设置了循环操作10000次。
import torch
import torch.nn
import timein_row, in_f, out_f = 256, 1024, 2048
loop_times = 10000现在,让我们看看CPU完成10000个转换需要多少秒:
s = time.time()
tensor = torch.randn(in_row, in_f).to('cpu')
l_trans = torch.nn.Linear(in_f, out_f).to('cpu')
for _ in range(loop_times):
l_trans(tensor)
print('cpu take time:',time.time()-s)
#cpu take time: 55.70971965789795可以看到cpu花费55秒。
GPU计算
为了让GPU的CUDA执行相同的计算,我只需将. To (' cpu ')替换为. cuda()。另外,考虑到CUDA中的操作是异步的,我们还需要添加一个同步语句,以确保在所有CUDA任务完成后打印使用的时间。
s = time.time()
tensor = torch.randn(in_row, in_f).cuda()
l_trans = torch.nn.Linear(in_f, out_f).cuda()
for _ in range(loop_times):
l_trans(tensor)
torch.cuda.synchronize()
print('CUDA take time:',time.time()-s)
#CUDA take time: 1.327127456665039并行运算只用了1.3秒,几乎是CPU运行速度的42倍。这就是为什么一个在CPU上需要几天训练的模型现在在GPU上只需要几个小时。因为并行的简单计算是GPU的强项。
如何使用Tensor Cores
CUDA已经很快了,那么如何启用RTX 3070Ti的197Tensor Cores?启用后是否会更快呢?在PyTorch中我们需要做的是减少浮点精度从FP32到FP16,也就是我们说的半精度或者叫混合精度:
s = time.time()
tensor = torch.randn(in_row, in_f).cuda().half()
layer = torch.nn.Linear(in_f, out_f).cuda().half()
for _ in range(loop_times):
layer(tensor)
torch.cuda.synchronize()
print('CUDA with tensor cores take time:',time.time()-s)
#CUDA with tensor cores take time:0.5381264686584473又是2.6倍的提升。
总结
在本文中,通过在CPU、GPU CUDA和GPU CUDA +Tensor Cores中调用PyTorch线性转换函数来比较线性转换操作。下面是一个总结的结果:
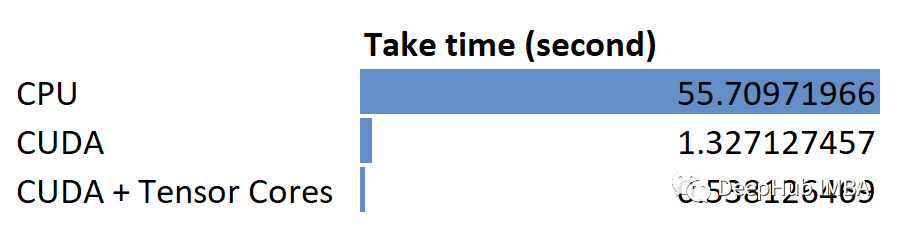
NVIDIA的CUDA和Tensor Cores确实大大提高了矩阵乘法的性能。
后面我们会有两个方向的更新:
1、介绍一些简单的CUDA操作(通过Numba),这样可以让我们了解一些细节。
2、我们会在拿到4090后发布一个专门针对深度学习的评测,这样可以方便大家选择购买。
编辑:王菁
校对:杨学俊
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









