






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达为什么需要OpenVINO?
OpenVINO(Open Visual Inference and Neural network Optimization)是英特尔推出的一种深度学习推理工具包,旨在优化和加速深度学习模型的推理过程。将模型转换为OpenVINO格式的主要优势有:
性能优化:OpenVINO能够针对英特尔硬件进行优化,包括 CPU、GPU、VPU 和 FPGA 等,从而实现对深度学习模型的加速推理,提高推理性能和效率。
跨平台部署:OpenVINO支持跨多种硬件平台进行部署,包括边缘设备和云服务器,能够在不同的设备上实现高效的推理。
模型保护:OpenVINO可以将模型转换为 IR(Intermediate Representation)格式,这样可以保护模型的知识产权,避免模型被轻易篡改或复制。
部署简化:OpenVINO提供了简单易用的部署工具和库,使得在实际应用中部署深度学习模型变得更加便捷。
使用自定义训练模型进行图像检测
from ultralytics import YOLO
from pathlib import Path
from IPython.display import Image
from PIL import Image
IMAGE_PATH = Path("data\coco_bike.jpg")
# There are three lines of code below, all are correct.
# You can use one of them
# Use Raw String Literal:
# det_model = YOLO(r"models\best.pt")
# Use Forward Slashes
# det_model = YOLO("models/best.pt")
# Use Double Backslashes:
det_model = YOLO("models\\best.pt")
label_map = det_model.model.names
res = det_model(IMAGE_PATH)
Image.fromarray(res[0].plot()[:, :, ::-1])当我们在终端中运行上述代码时,它会对图像执行检测,如下所示:

上述代码的解释
此代码是一个 Python 脚本,它使用“ultralytics”库中的 YOLO(You Only Look Once)对象检测模型来检测图像中的对象。让我们分解一下代码的每个部分的作用:
导入库:
该ultralytics库提供了用于处理各种计算机视觉任务的工具,包括使用 YOLO 进行对象检测。
该pathlib库用于处理文件和目录路径。
该IPython.display库用于在 Jupyter 笔记本中显示图像。
该PIL库(Python Imaging Library)用于图像处理。
2.定义图像路径:
该IMAGE_PATH变量设置为位于名为“data”的目录中名为“coco_bike.jpg”的图像文件的路径。
3.加载YOLO模型:
使用 ultralytics 库中的类加载 YOLO 模型YOLO。模型文件“best.pt”作为参数提供。
4. 获取标签图:
该label_map变量被分配了 YOLO 模型能够检测的类名列表。这些类名是从 YOLO 模型中加载的。
5.检测物体:
YOLO 模型 ( det_model) 用于检测指定图像中的物体 ( IMAGE_PATH)。
检测结果存储在res变量中。
6.显示结果:
Image.fromarray()使用库中的函数显示检测结果PIL。该plot()方法用于创建检测到的对象的图像表示,并使用切片([:, :, ::-1])反转颜色通道以将图像从 BGR 转换为 RGB 格式。
分割
from ultralytics import YOLO
from pathlib import Path
from IPython.display import Image
from PIL import Image
SEG_MODEL_NAME = "yolov8n-seg"
IMAGE_PATH = Path("data\coco_bike.jpg")
seg_model = YOLO("models\yolov8n-seg.pt")
res = seg_model(IMAGE_PATH)
Image.fromarray(res[0].plot()[:, :, ::-1])输出:

上述代码的解释
让我们以简单的方式一步一步地解释一下这段代码:
导入库:
该代码使用该ultralytics库来处理计算机视觉模型。
该pathlib库用于处理文件路径。
该IPython.display库用于在笔记本中显示图像。
该PIL库用于与图像相关的任务。
2.设置模型名称和图像路径:
该SEG_MODEL_NAME变量设置为“yolov8n-seg”分割模型的名称。该模型旨在理解图像的结构并将其分割成不同的部分。
该IMAGE_PATH变量设置为位于“data”目录中名为“coco_bike.jpg”的图像文件的路径。
3.加载分割模型:
YOLO使用ultralytics 库中的类加载 YOLO 分割模型。
模型文件“yolov8n-seg.pt”作为参数提供。此文件包含分割模型的预训练权重和配置。
4.执行分割:
seg_model使用分割模型( )对指定的图像( IMAGE_PATH)进行分割。
分割的结果存储在res变量中。
5.显示分割图像:
代码将分割结果转换为可以显示的图像格式。
该plot()方法用于创建分割区域的图像表示。
图像的颜色通道被反转([:, :, ::-1])以使其适合以 RGB 格式显示。
6.显示图像:
Image.fromarray()该库中的函数用于PIL在 IPython 笔记本中显示分割图像。
导出物体检测模型
# object detection model
from ultralytics import YOLO
import os
# Use Forward Slashes
det_model = YOLO("models/best.pt")
det_model_path = "models/best_openvino_model/best.xml"
if not os.path.exists(det_model_path):
det_model.export(format="openvino", dynamic=True, half=False)输出:
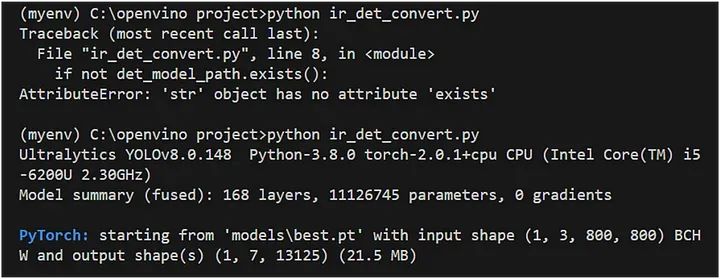
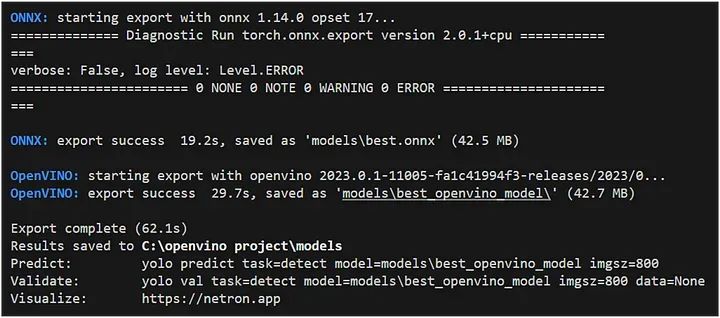
上述代码的解释:
导入库:
代码YOLO从ultralytics库中导入类以与对象检测模型协同工作。
该os模块被导入是为了与操作系统协同工作。
2.加载对象检测模型:
YOLO使用库中的类加载对象检测模型ultralytics。
模型文件“best.pt”作为参数提供。该模型用于检测图像中的对象。
3.定义 OpenVINO 的导出路径:
该变量det_model_path设置为对象检测模型的 OpenVINO 模型文件“best.xml”的路径。
4.导出为 OpenVINO 格式:
代码检查 OpenVINO 模型文件是否不存在指定路径。
如果文件不存在,则使用该export方法将对象检测模型导出为 OpenVINO 格式:
format="openvino"指定导出格式应为OpenVINO。
dynamic=True表示导出的模型应该支持动态输入形状。
half=False指定导出的模型不应使用半精度浮点数。
导出分割模型
# Export segmentation model
from ultralytics import YOLO
import os
# Use Forward Slashes
seg_model = YOLO("models/yolov8n-seg.pt")
seg_model_path = "models/yolov8n-seg_openvino_model/yolov8n-seg.xml"
if not os.path.exists(seg_model_path):
seg_model.export(format="openvino", dynamic=True, half=False)输出:
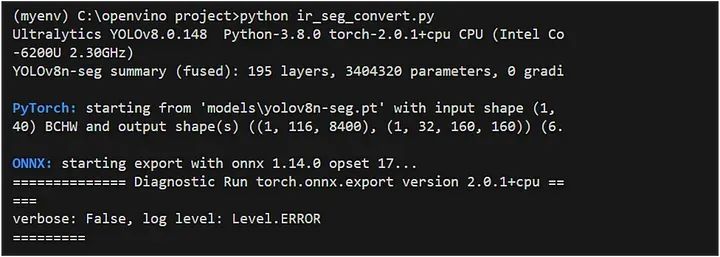
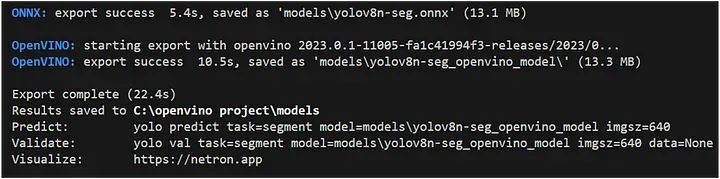
上述代码的解释:
导入库:
代码YOLO从ultralytics库中导入类以与分割模型协同工作。
该os模块被导入用于与操作系统交互。
2.加载分割模型:
YOLO使用库中的类来加载分割模型ultralytics。
模型文件“yolov8n-seg.pt”作为参数提供。该模型专为图像分割而设计。
3.定义 OpenVINO 的导出路径:
该变量seg_model_path设置为OpenVINO模型文件“yolov8n-seg.xml”的保存路径。
4.导出为 OpenVINO 格式:
代码检查 OpenVINO 模型文件是否不存在指定路径。
如果该文件不存在,则使用该export方法将分割模型导出为 OpenVINO 格式:
format="openvino"指定导出格式应为OpenVINO。
dynamic=True表示导出的模型应该支持动态输入形状。
half=False指定导出的模型不应使用半精度浮点数。
文中完整的项目地址和模型可以查看:https://github.com/mushfiq1998/export-trained-yolov8-to-openvino-with-python
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









