






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达多尺度注意力融合图网络在遥感建筑变化检测中的应用
作者:Yu Shangguan , Jinjiang Li , Zheng Chen , Lu Ren , and Zhen Hua
源码链接:https://github.com/ShangGY805/MAFG
论文创新点
双图卷积模块(DGM):我们设计了一种包含空间图卷积网络(SGCN)和通道图卷积网络(CGCN)的双图卷积模块,有效地在空间和通道两个层面探索检测目标与全局之间的长期依赖关系。
多尺度注意力融合编码器:通过通道注意力融合模块(CAFM)和空间注意力融合模块(SAFM),我们的模型能够从多尺度特征中有效结合有价值的信息,增强了对建筑目标的识别能力,并改善了边缘信息。
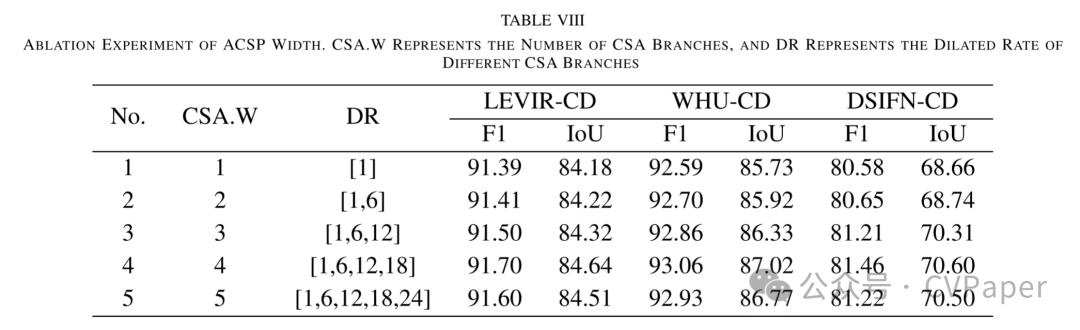
带孔隙的上下文自注意力金字塔(ACSP):我们提出了一种新的ACSP结构,利用具有不同扩张率的上下文自注意力(CSA)分支,结合多尺度语义来学习变化特征,从而实现对不同大小建筑目标的自适应感知和捕捉。
摘要
随着成像系统和卫星技术的发展,更高质量的高分辨率遥感(RS)图像被应用于建筑变化检测(BCD)技术中。基于卷积神经网络(CNN)的方法由于其出色的特征区分能力,在BCD技术中取得了巨大成功。然而,CNN在很大程度上依赖于先前条件的几何形状,并且受到卷积核大小的限制,容易忽略全局信息。这使得捕获不同建筑目标的长期依赖性和处理高分辨率卫星RS图像中的复杂空间关系变得困难。考虑到图卷积神经网络(GCN)在内部关系学习方面的强大能力,本文提出了一种多尺度注意力融合图网络(MAFGNet)。MAFGNet使用双图卷积模块(DGM),包括空间图卷积网络(SGCN)和通道图卷积网络(CGCN),有效地探索检测目标与全局在空间和通道层面的长期关系。我们还设计了一个多尺度注意力融合编码器,包括通道注意力融合模块(CAFM)和空间注意力融合模块(SAFM),以有效结合多尺度特征中的有价值信息。此外,设计了一种带孔隙的上下文自注意力金字塔(ACSP),以结合多尺度上下文来增强变化信息的特征表示。我们在不同数据集上进行了定性和定量的比较实验,以验证我们模型的有效性。实验结果表明,我们的方法在整体准确性(OA)和可视化细节方面优于先进方法。
Part1方法
在本节中,我们首先介绍网络的整体框架。然后,我们详细描述模型中的三个主要组件:DGM、AFM和ACSP。最后,我们用算法形式说明整个网络训练过程中的损失函数和特征差异模块。
网络的整体框架
基于CNN的模型在CD任务中表现出色,但它倾向于关注局部特征数据,这也限制了检测图像中区域之间的连接。为了有效地探索区域之间的长期依赖性,我们应用了专注于研究一对多数据关系学习的GCN到我们的网络结构中。我们设计的网络整体结构如图2所示。为了在网络训练期间更好地学习输入双时相图像的浅层信息(例如目标对象的边缘和形状检测)以及深层语义信息,我们设计了一个Siamese多尺度特征注意力融合结构在网络的编码器部分。这个特征细化过程对双时相输入图像是权重共享的。通道AFM(CAFM)和空间AFM(SAFM)将被用来更有效地结合这些不同分辨率的中间特征,这将有效地探索多尺度特征信息。之后,我们通过一个简单的差异模块结合获得的中间细化特征,并得到一个变化区分特征。这个变化区分特征仍然相对粗糙。然后我们使用ACSP结合变化特征的多尺度上下文信息,并用它们来指导更有效的自注意力学习。我们进一步将变化特征映射到解码器的图域中,并通过SGCN和CGCN在空间和通道维度上学习图结构中不同节点特征之间的长期相关性,以增强模型的检测性能。我们的方法可以用算法1来说明。

注意力融合模块
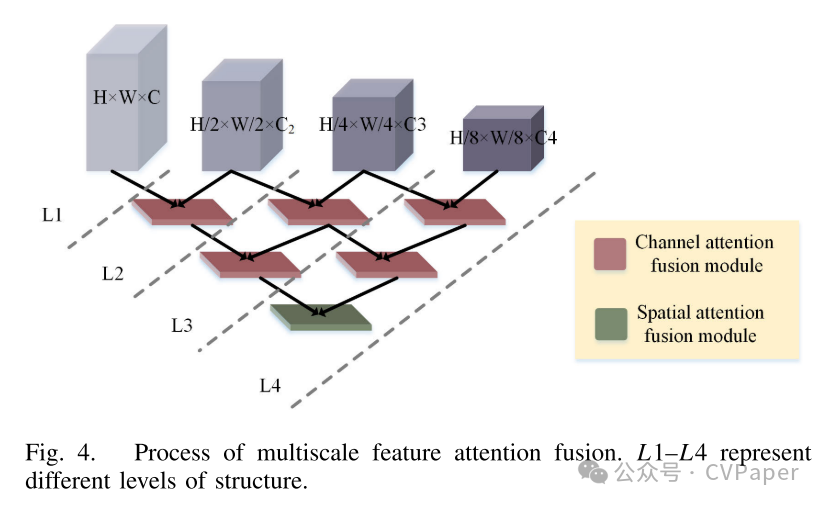
有效地融合不同尺度的特征是多尺度学习的关键。连接操作和元素级求和是融合多尺度特征的传统方法。然而,这些方法在融合过程中缺乏更有效的方式来探索不同尺度特征的有价值信息。为了加强我们网络在结合不同分辨率特征方面的有效性,我们引入了一个统一的AFM,如图3所示,它提供了空间和通道注意力的不同选项。使用注意力机制使融合过程更加高效,并且获得的重加权融合特征信息更加丰富。图4显示了基于AFM设计的多尺度特征注意力融合过程,L1–L4代表不同的融合层编号。
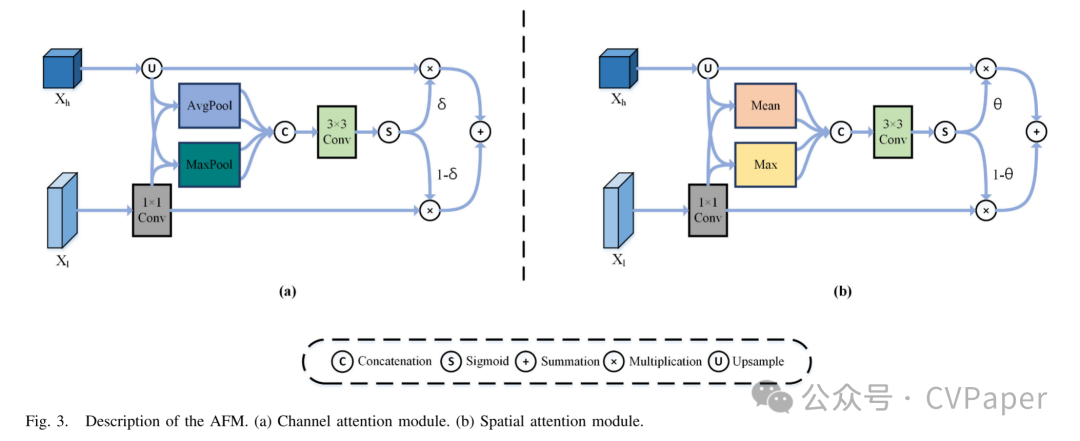
如图3所示,当两个不同尺度的特征输入到AFM时,它们首先需要进行预处理。具体来说,给定输入和,其中C表示低级特征的通道数,C'表示高级特征的通道数,H和W分别表示高度和宽度,r表示上采样的倍数。首先,将尺寸较小的高级特征通过双线性插值操作上采样到,而将低级特征通过1×1卷积层改变到,使其通道数与高级特征相同。这个过程可以表示如下:
如公式(1)所示,当特征的两个不同尺度输入到AFM时,它们首先需要进行预处理。具体来说,给定输入和,其中C表示低级特征的通道数,C'表示高级特征的通道数,H和W分别表示高度和宽度,r表示上采样的倍数。首先,将尺寸较小的高级特征通过双线性插值操作上采样到,而将低级特征通过1×1卷积层改变到,使其通道数与高级特征相同。这个过程可以表示如下:
如公式(2)所示,CAFM使用通道注意力插件来融合输入特征并生成权重δ来重新加权它们。这个权重显示了输入特征中不同通道的相对重要性。具体来说,我们对两个特征和进行平均池化和最大池化操作,以获得四个维度为的特征。这四个特征在通道轴上进行连接,并使用卷积操作重新缩放到通道数。然后,我们使用sigmoid函数生成一个维度为的权重δ,并分别与两个输入特征进行元素级乘法,最后将它们相加得到融合特征。这个过程可以总结为以下公式:
如公式(2)所示,CAFM使用通道注意力插件来融合输入特征并生成权重δ来重新加权它们。这个权重显示了输入特征中不同通道的相对重要性。具体来说,我们对两个特征和进行平均池化和最大池化操作,以获得四个维度为的特征。这四个特征在通道轴上进行连接,并使用卷积操作重新缩放到通道数。然后,我们使用sigmoid函数生成一个维度为的权重δ,并分别与两个输入特征进行元素级乘法,最后将它们相加得到融合特征。
双图卷积网络模块
为了有效探索包含不同信息的特征中的长期空间和通道关系,我们设计了一个双图卷积网络模块。这个模块使用两个不同的图卷积网络模块,包括SGCN模块和CGCN模块。
SGCN模块:对于光学遥感的双时相图像中的BCD任务来说,能够有效地区分变化和未变化的对象至关重要。空间图卷积通过聚合全局像素和模拟单个像素与所有像素之间的内部关系,充分探索不同对象之间的长期上下文信息,这可以增强网络对变化对象的敏感性,从而提高检测性能。因此,我们使用SGCN来捕获局部到全局的空间信息。具体来说,给定一个特征,其中C表示通道数,H和W分别表示高度和宽度。图卷积的一个简单定义可以表示如下:
其中A表示邻接矩阵,W是包含滤波器参数的矩阵。如图5(a)所示,在SGCN中,我们首先通过1×1卷积操作μ(·), φ(·), 和ω(·)分别压缩输入特征Xin的通道数,并通过重塑操作将其维度改变为。我们使用定义的空间图卷积学习和矩阵乘法来获得一个新特征,可以描述如下:
其中表示SGCN的输出,表示权重矩阵,上标T表示转置操作。表示SGCN的邻接矩阵,可以通过矩阵乘法μ和φ 来表示。考虑到矩阵乘法的计算复杂性,我们将μφω替换为μφω,这可以将测量矩阵的计算复杂性从降低到。我们再次将得到的邻接矩阵乘以μ(Xin)以获得全局空间信息。在此过程中使用的softmax操作可以提高数据的稳定性并提供更好的收敛性[58]。之后,使用1×1 1-D卷积层实现从隐藏层到输出层的加权过程,使用1×1 2-D卷积层调整通道数。最后,我们使用逐元素加法进行残差学习并获得最终的输出特征。这个过程可以描述如下:
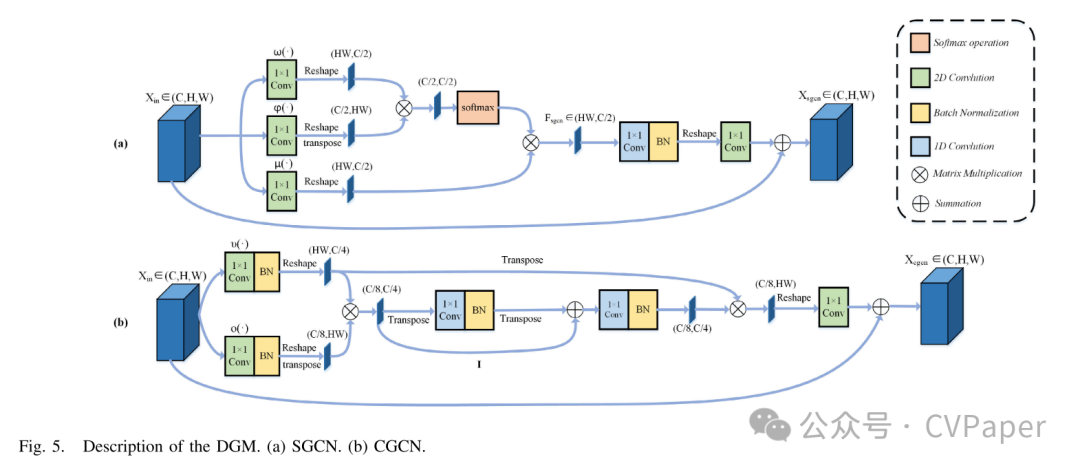
CGCN模块:除了使用SGCN在空间维度上对图像像素的长期上下文信息进行建模外,我们还引入了CGCN来有效地捕获通道级别上抽象特征之间的相互依赖性。如图5(b)所示,我们定义了通过通道映射的新特征图的卷积过程如下:
其中表示节点之间传播信息的邻接矩阵,I表示单位矩阵,表示可训练的边权重矩阵。和通过两个1-D 1×1卷积操作获得。CGCN将邻接矩阵替换为进行拉普拉斯平滑[59], [60],以在图上传播节点特征。单位矩阵I用于执行快捷连接,以减轻优化困难。我们将输入特征的通道数从C压缩到和,分别通过两个1×1 2-D卷积操作ν(·)和o(·),并通过ν(Xin)和o(Xin)^T的矩阵乘法将输入特征投影到通道交互空间。获得的可以被视为一个具有个节点的图结构,每个节点的维度为。这个过程可以重新定义如下:
之后,我们通过o(Xin)将重新投影回原始坐标空间,并使用1×1 2-D卷积调整通道数为C。最终的输出结果可以表示如下:
带孔隙的上下文自注意力金字塔
我们设计了一个基于CSA的并行结构ACSP,如图6所示。
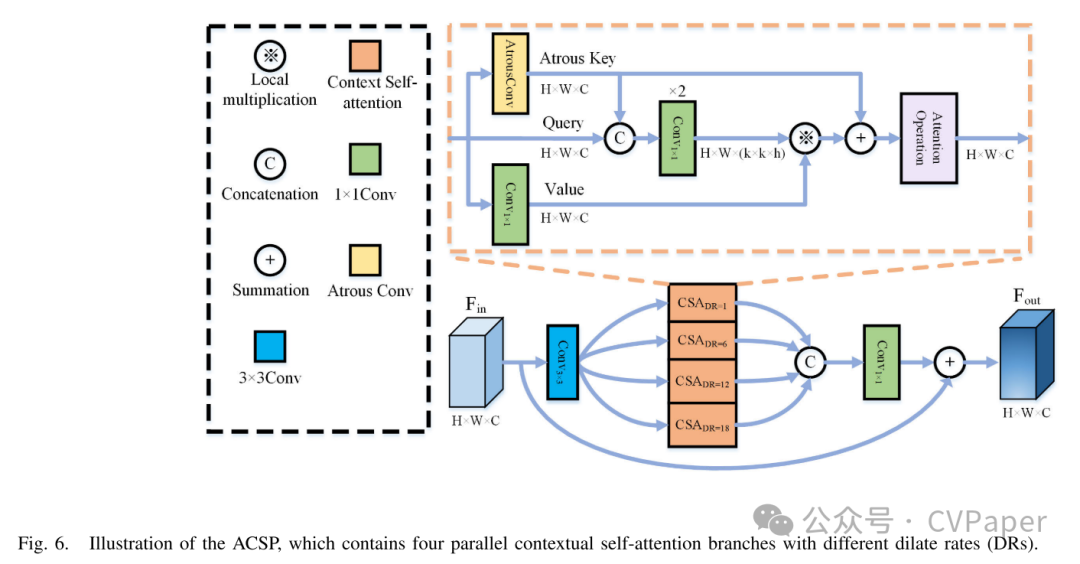
它用于挖掘变化特征的空间上下文并进行自注意力学习,以增强视觉表示学习。与传统的基于独立查询-键对的自注意力相比,CSA还使用带孔隙的卷积来结合输入上下文信息,实现更高效的自注意力学习。四个并行CSA具有不同的扩张率,用于捕获不同尺度的空间上下文,以适应不同大小的兴趣区域。具体来说,给定输入,我们首先通过3×3卷积和线性整流函数(ReLU)激活函数学习每个空间像素的邻接上下文。然后,我们使用四个具有不同扩张率的CSA分支来结合不同尺度的上下文信息并执行自注意力学习。我们将它们的扩张率设置为[1, 6, 12, 18]。之后,我们在通道维度上将它们连接起来,并使用1×1卷积操作将其通道数重新缩放到C。最后,我们将结果和输入在元素级上相加,以进行残差学习并获得最终输出。这个过程可以总结如下:
其中, 表示一个CSA模块, 表示由它设置的扩张率。在单个CSA的实现过程中,我们获得键、查询和值的方式可以由以下表达式描述:
其中,、Q和V分别表示键图、查询和值图,它们的形状是R^{C \times H \times W}。嵌入矩阵W_k和W_v是通过一个扩张率为dr和核大小为(我们设置为)的带孔隙卷积和一个卷积层学习的。键图通过带孔隙卷积反映了受限制的静态局部上下文信息。然后我们通过连接操作将键图和查询在通道维度上拼接起来,获得一个动态多头自注意力矩阵M_{kq} \in R^{H \times W \times (k \times k \times C_h)}。C_h$ 表示头部的数量,我们设置为 8。这个过程可以表示如下:
其中, 和 表示两个带有ReLU激活函数和BatchNorm的 1×1 卷积参数矩阵。对于自注意力矩阵 的每个头部,其在每个空间位置的局部注意力矩阵 k×k 通过查询和键结合上下文信息学习,而不是独立的查询-键对。这种方法通过探索输入的静态上下文有效增强了自注意力学习。之后,CSA通过局部矩阵乘法[61]、[62]和获得的注意力矩阵聚合值图
其中, 表示局部矩阵乘法,它执行 中每个空间位置的 Ch k×k 局部注意力矩阵与值图中的 k×k 网格的值的矩阵乘法。 表示被关注的特征图,它连接了所有头部的聚合特征,并捕获了输入特征中的动态上下文信息。CSA然后对获得的 和键图进行连接操作,以融合静态和动态上下文信息,并使用通道注意力[63]获得最终输出。这个过程可以表示如下:
其中, 和 表示两个带有ReLU激活函数的 1×1 卷积层, 表示权重矩阵, 是一个CSA分支的输出。
其他网络细节
损失函数:在训练阶段,我们使用最小化的交叉熵损失来优化模型,其正式定义如下:
其中 和 分别表示原始图像的高度和宽度, 是交叉熵损失, 是位置 (h, w) 处像素的标签。
特征差异模块:我们在解码器中引入了一个特征差异模块,以有效地计算变化前后图像的特征图之间的差异。通过特征提取器处理的两个细化特征首先通过连接进行融合。然后,使用一个 3×3 卷积层和填充为 1 的卷积层来减少融合特征图中的通道数。最后,我们应用ReLU激活函数和批量归一化进行归一化,以获得变化区分特征。特征差异模块的过程可以正式定义如下:
其中 表示差异模块得到的结果, 表示通过特征提取器处理变化前图像得到的中间特征, 表示通过特征提取器处理变化后图像得到的中间特征,R 表示ReLU激活函数,B 表示 BatchNorm。
Part2实验结果
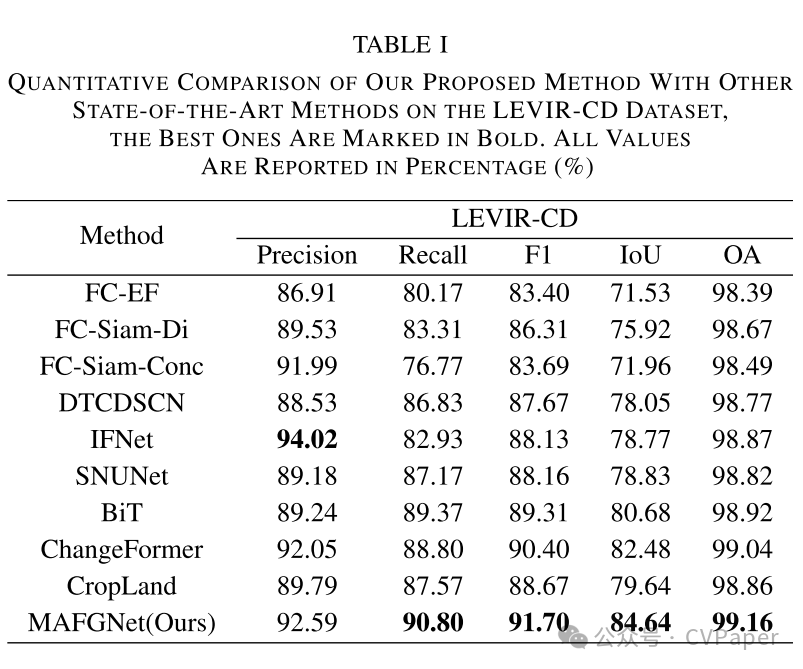

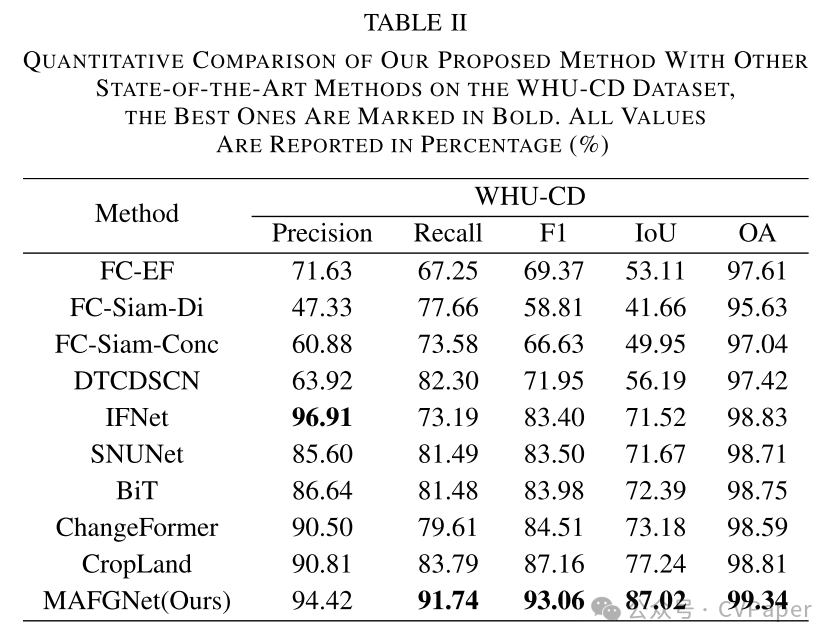

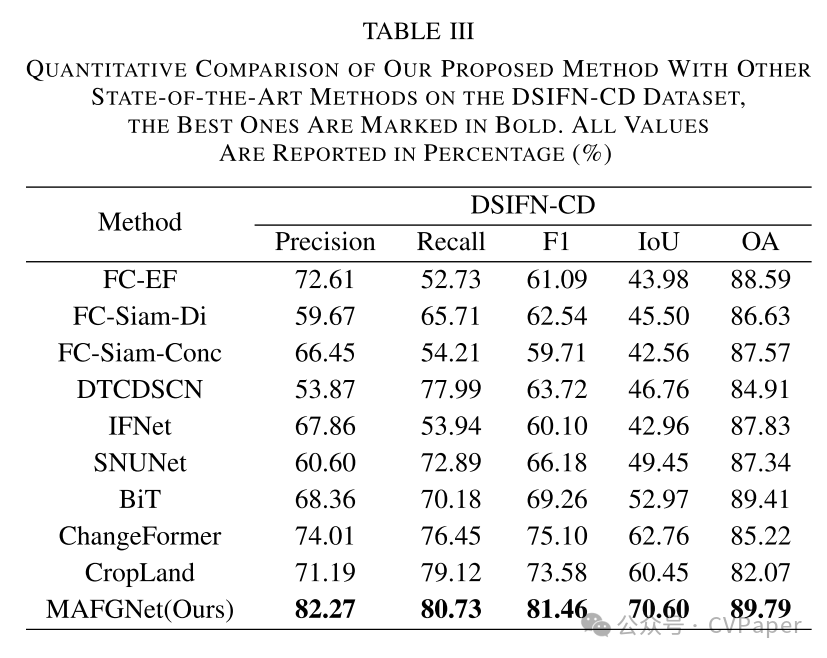

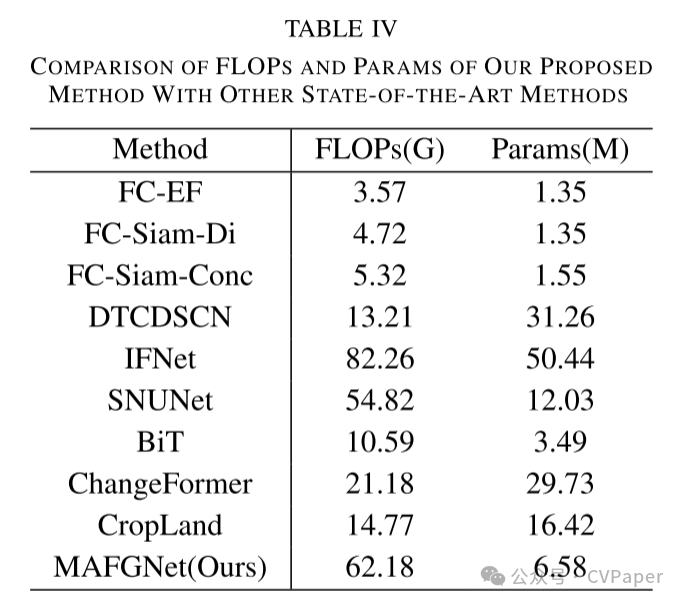
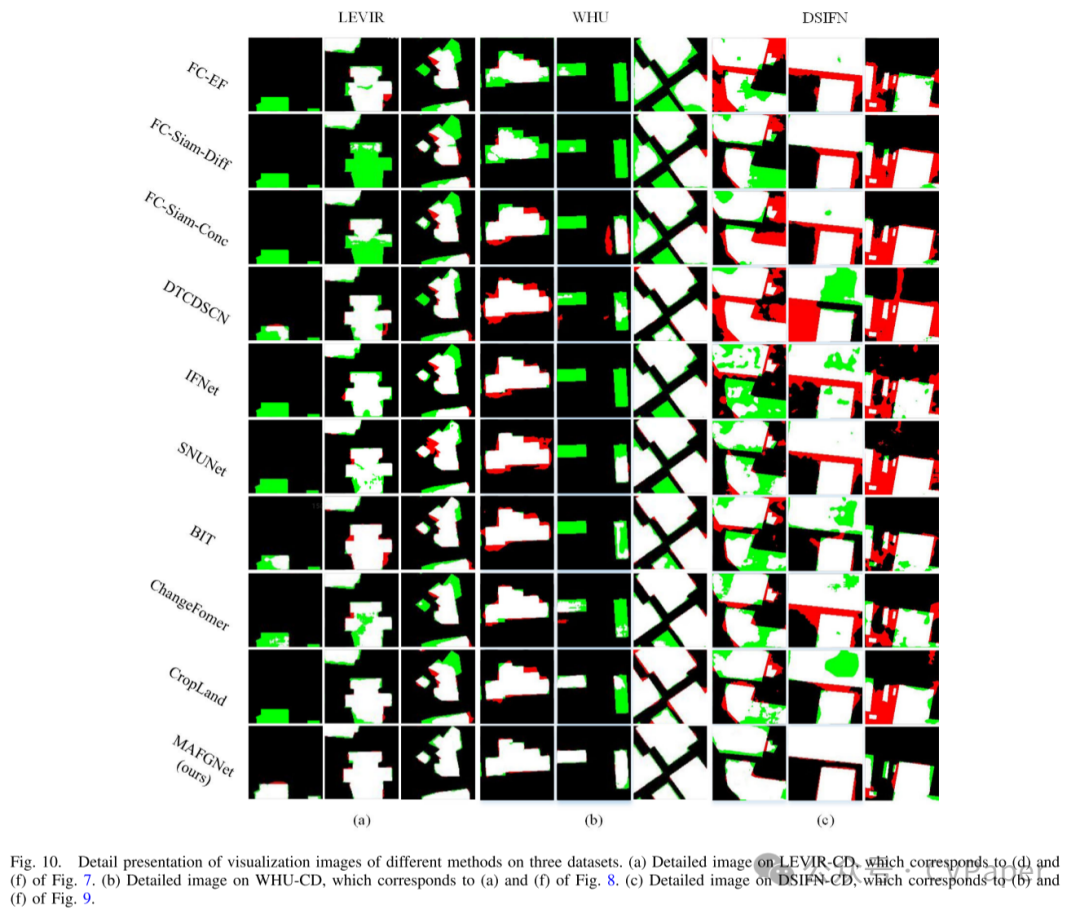
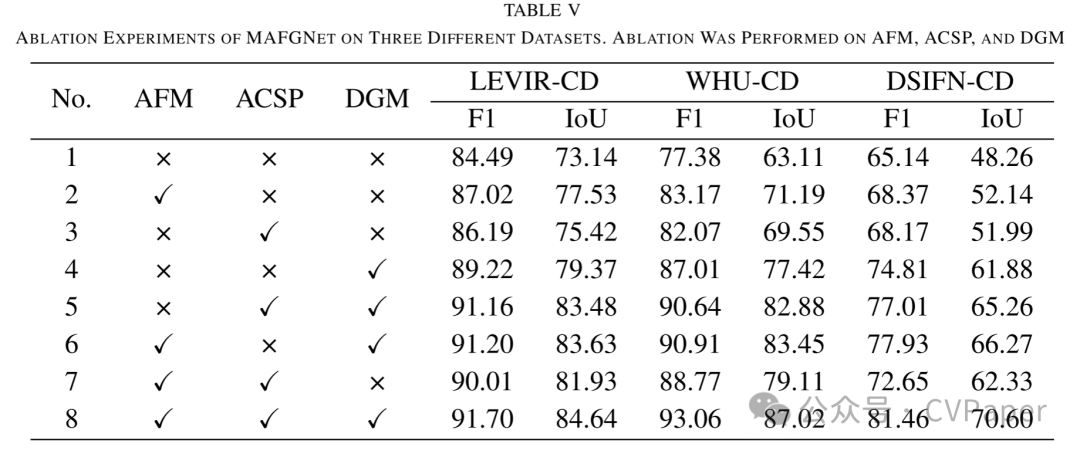
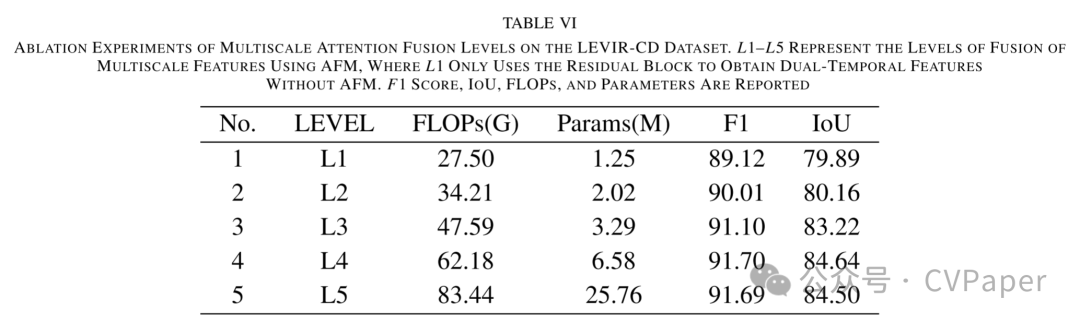
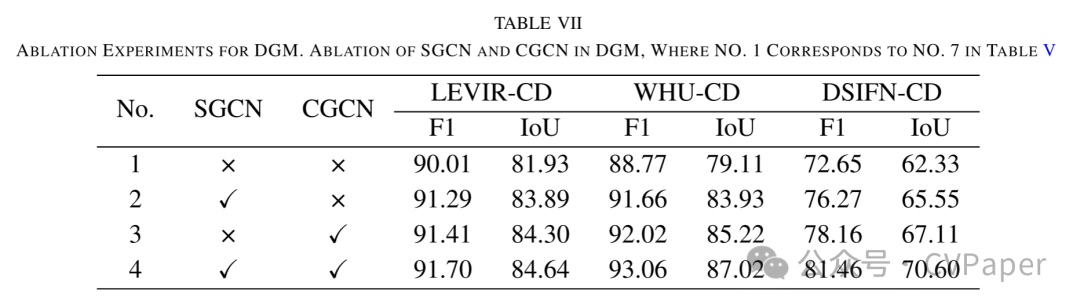

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









