







任务
本次任务与大模型微调1——使用LoRA微调qwen模型优化推理效果相同:使用LoRA微调技术微调qwen大模型,优化大模型在逻辑推理上的回答效果。任务详情可参考第二届世界科学智能大赛逻辑推理赛道:复杂推理能力评估。
上篇《大模型微调1》自己搭建的LoRA微调框架微调qwen大模型,Qwen2.5开始,qwen官方文档已经开始说明有监督微调使用LLaMA-Factory开源工具了,本问即尝试使用LLaMA-Factory微调大模型。
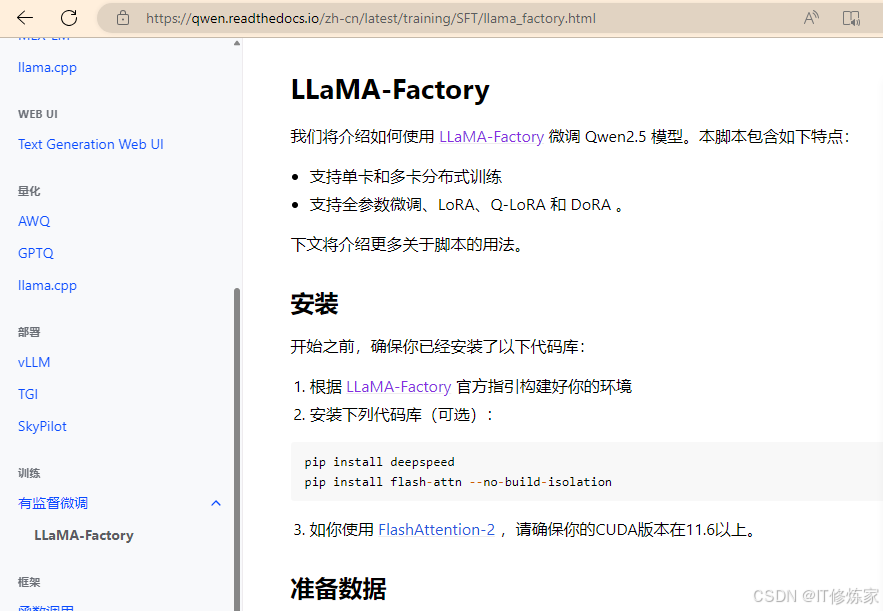
LLaMA-Factory简介
LLaMA Factory 是一个用于管理和训练大语言模型(Large Language Model, LLM)的工具或框架。它可以基于现有的预训练模型(例如 Meta 的 LLaMA 模型)进行微调和优化,以适应特定的下游任务。它主要关注模型的高效部署、微调以及在不同任务中的应用。以下是对 LLaMA Factory 的更详细介绍:
主要功能与特点:
- 微调预训练模型:
- LLaMA Factory 提供了简化的接口,方便用户使用预训练模型(如 LLaMA 系列)进行微调,适用于特定的数据集和任务。它支持包括 LoRA(Low-Rank Adaptation) 等轻量化微调方法,以降低计算资源需求,特别是在训练资源有限的情况下。
- 分布式训练支持:
- 该工具集成了 PyTorch Distributed 和 DeepSpeed 等技术,能够高效地执行大规模分布式训练任务。LLaMA Factory 提供了对多 GPU 和多节点环境的支持,使得大模型的训练更加高效。
- 集成 DeepSpeed 和 FlashAttention:
- LLaMA Factory 使用 DeepSpeed 来优化训练的内存使用和加速训练过程。同时,它也可以集成 FlashAttention,用于加速 Transformer 模型中的自注意力机制,从而有效处理长序列输入。
- 支持多种微调方式:
- 除了常见的 全参数微调,LLaMA Factory 还支持 参数高效微调,如 LoRA 以及其他低秩适应方法,帮助减少模型训练和推理的显存占用。
- 预处理和定制数据加载器:
- LLaMA Factory 提供了灵活的数据预处理接口,可以根据不同任务自定义数据加载器。它的目标是简化训练前的数据准备,方便用户快速将数据集应用于微调。
- 易于扩展与集成:
- LLaMA Factory 的代码结构易于扩展,用户可以方便地集成其他的 Transformer 模型或者自定义的模型结构。这对于研究人员和开发人员来说非常友好,可以根据自己的需要进行定制化修改。
LLaMA-Factory安装
详情可参考LLaMA-Factory官方文档,没有科学上网可能git失败

数据准备
关于数据集文件的格式,请参考 data/README_zh.md 的内容。目前LLaMA Factory支持 alpaca 格式和 sharegpt 格式的数据集。 alpaca 格式和 sharegpt 格式详情可参考大模型微调——训练数据集的格式Alpaca 和 ShareGPT-CSDN博客。
对于有监督微调数据集,从上一篇《大模型微调1》可以看出我们格式化后的数据集即为alpaca格式。
LLaMA Factory支持 alpaca 格式:
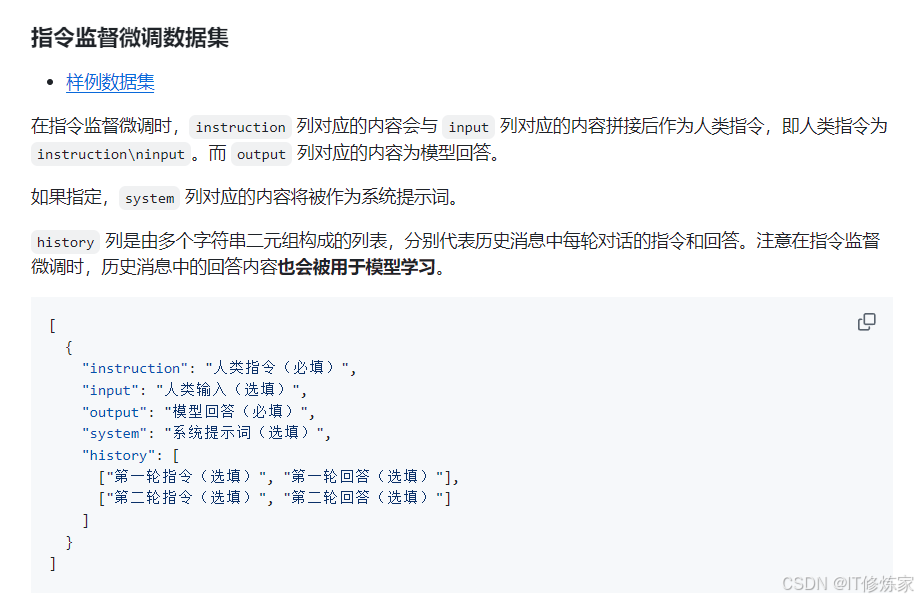
我们的数据格式:
{
"instruction": "你是一个逻辑推理专家,擅长解决逻辑推理问题。以下是一个逻辑推理的题目,形式为单项选择题。所有的问题都是(close-world assumption)闭世界假设,即未观测事实都为假。请逐步分析问题并在最后一行输出答案,最后一行的格式为\"答案是:A\"。题目如下:\n\n### 题目:\n假设您需要构建一个二叉搜索树,其中每个节点或者是一个空的节点(称为\"空节点\"),或者是一个包含一个整数值和两个子树的节点(称为\"数值节点\")。以下是构建这棵树的规则:\n\n1. 树中不存在重复的元素。\n2. 对于每个数值节点,其左子树的所有值都小于该节点的值,其右子树的所有值都大于该节点的值。\n3. 插入一个新值到一个\"空节点\"时,该\"空节点\"会被一个包含新值的新的数值节点取代。\n4. 插入一个已存在的数值将不会改变树。\n\n请基于以上规则,回答以下选择题:\n\n### 问题:\n选择题 1:\n给定一个空的二叉搜索树,插入下列数字: [5, 9, 2, 10, 11, 3],下面哪个选项正确描述了结果树的结构?\nA. tree(5, tree(2, tree(3, nil, nil), nil), tree(9, tree(10, nil, nil), tree(11, nil, nil)))\nB. tree(5, tree(2, nil, tree(3, nil, nil)), tree(9, nil, tree(10, nil, tree(11, nil, nil))))\nC. tree(5, tree(3, tree(2, nil, nil), nil), tree(9, nil, tree(10, tree(11, nil, nil), nil)))\nD. tree(5, nil, tree(2, nil, tree(3, nil, nil)), tree(9, tree(11, nil, nil), tree(10, nil, nil)))\n",
"input": "",
"output": "B"
},
注意需要在项目data/dataset_info.json 中添加自己数据集的说明:
"tuili": { # 数据集名称
"file_name": "mydata/an_train.json", # 数据集路径
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
开始训练
qwen官方文档给的是指令执行,其实也可以通过配置yaml文件执行,后者可以参考【大模型实战教程】Qwen2.5 PyTorch模型微调入门实战。
解释下官方给的多种参数含义:
DISTRIBUTED_ARGS="
--nproc_per_node $NPROC_PER_NODE \ # 指定每个节点上启动多少个进程。通常这个值对应于该节点上的 GPU 数量。
--nnodes $NNODES \ # 指定训练中有多少个节点(机器)。
--node_rank $NODE_RANK \ # 指定当前节点(机器)的排名(从 0 开始)。在分布式训练中,每个节点都需要有唯一的编号,以确保正确的通信和同步。
--master_addr $MASTER_ADDR \ # 指定主节点(节点 0)的 IP 地址。
--master_port $MASTER_PORT # 指定主节点的端口号。
"
torchrun $DISTRIBUTED_ARGS src/train.py \
--deepspeed $DS_CONFIG_PATH \ # 启用 DeepSpeed 并指定配置文件路径。DeepSpeed 是一个优化框架,可以加速大规模模型的训练,并减少内存消耗。
--stage sft \ # 训练阶段的标识,通常用于区分不同的训练阶段。例如,sft 表示“Supervised Fine-Tuning”(监督微调)。
--do_train \ # 表示执行训练任务。
--use_fast_tokenizer \ # 启用快速分词器,通常会加速数据的预处理,尤其是在处理大规模文本时。
--flash_attn \ # 启用 FlashAttention,这是一种优化的自注意力计算方式,用于加速 Transformer 模型中的注意力机制,特别是处理长序列时。
--model_name_or_path $MODEL_PATH \ # 指定预训练模型的路径(或模型名称)
--dataset your_dataset \ # 指定训练的数据集,可以是本地数据集或一个公开的名称。
--template qwen \ # 指定任务的模板,这里可能是特定于模型任务的模板类型
--finetuning_type lora \ # 指定微调方法为 LoRA
--lora_target q_proj,v_proj\ # 指定 LoRA 进行微调的目标层
--output_dir $OUTPUT_PATH \ # 指定模型训练输出的路径,保存训练后的模型和日志等。
--overwrite_cache \ # 表示在处理数据时,覆盖之前的缓存。
--overwrite_output_dir \ # 表示覆盖之前的输出目录,防止意外保留旧的训练结果。
--warmup_steps 100 \ # 指定学习率预热的步数,通常用于训练开始时逐渐增大学习率,避免模型不稳定。
--weight_decay 0.1 \ # 指定权重衰减系数,用于正则化,防止过拟合。
--per_device_train_batch_size 4 \ # 每个设备(GPU)上的训练批量大小为 4。
--gradient_accumulation_steps 4 \ # 每个设备(GPU)上的训练批量大小为 4。
--ddp_timeout 9000 \ # 设置分布式数据并行(DDP)的超时时间,防止由于通信问题导致的训练崩溃。
--learning_rate 5e-6 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--cutoff_len 4096 \ # 截断输入序列的长度为 4096,通常用于限制序列长度以减少计算开销。
--save_steps 1000 \ # 每 1000 步保存一次模型检查点,确保训练过程中保存中间结果。
--plot_loss \ # 启用损失值的绘图功能,可能在训练完成后生成损失曲线。
--num_train_epochs 3 \
--bf16
由于我当前服务器只有一张显卡,因此不用配置分布式训练参数使用命令如下:
torchrun --nproc_per_node=1 ...
torchrun src/train.py \
--stage sft \
--do_train \
--model_name_or_path Qwen2-1___5B-Instruct \
--dataset tuili \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj\
--output_dir Output \
--overwrite_cache \
--overwrite_output_dir \
--warmup_steps 100 \
--weight_decay 0.1 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--ddp_timeout 9000 \
--learning_rate 5e-6 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--cutoff_len 4096 \
--save_steps 1000 \
--plot_loss \
--num_train_epochs 3 \
--bf16
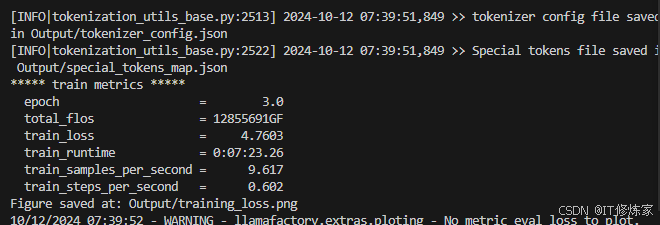
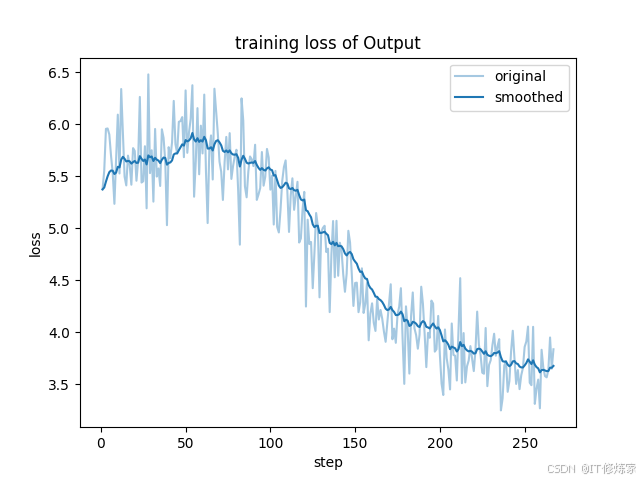
运行完后可以查看训练的结果,很多记录都在输出保存的Output文件夹下:
参考文献
1、【pytorch记录】pytorch的分布式 torch.distributed.launch 命令在做什么呢-CSDN博客

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









