







 超级会员免费看
超级会员免费看
基于改进Deeplabv3+的混凝土裂纹分割算法
基于改进Deeplabv3+的混凝土裂纹分割算法
前言
本文在论文[1]的基础上进行复现,供具有相似任务的同学参考。首先,使用MobileNetV3作为轻量级主干,大幅降低模型参数量;其次,使用尺度内特征交互模块建模全局信息并引入基于归一化的注意力机制,促进多层次裂缝特征信息交互;此外,提取低层次高分辨率特征后引入混合注意力机制,更有效捕获细节特征;最后,设计C2f-SCConv模块,对融合后的高低层级特征流解码,减小计算冗余,提升对多尺度特征的感知能力。旨在帮助初学者或者科研经历较少的小伙伴快速实现项目或者完成相关科研任务。
万字长文,直指毕设
参考文章:《融入特征交互与注意力的轻量化混凝土裂缝分割算法_彭垚潘》,Deeplabv3+基础实现
基础代码: Deeplabv3+
效果展示

1.代码部分
1.1 Mobilenetv3
MobileNetv3是轻量化网络中非常经典的网络,网上有许多资料介绍基本原理,这里就不再赘述。之前没有实现过Deeplabv3+的小伙伴先看这篇文章Deeplabv3+基础实现。
在nets/backbone目录中创建mobilenetv3.py
import torch
from torch import nn
from torchvision.models.mobilenetv3 import MobileNetV3, InvertedResidualConfig
class MobilenetV3Encoder(MobileNetV3):
def __init__(self, pretrained: bool = False):
super().__init__(
inverted_residual_setting=[
InvertedResidualConfig( 16, 3, 16, 16, False, "RE", 1, 1, 1),
InvertedResidualConfig( 16, 3, 64, 24, False, "RE", 2, 1, 1), # C1
InvertedResidualConfig( 24, 3, 72, 24, False, "RE", 1, 1, 1),
InvertedResidualConfig( 24, 5, 72, 40, True, "RE", 2, 1, 1), # C2
InvertedResidualConfig( 40, 5, 120, 40, True, "RE", 1, 1, 1),
InvertedResidualConfig( 40, 5, 120, 40, True, "RE", 1, 1, 1),
InvertedResidualConfig( 40, 3, 240, 80, False, "HS", 2, 1, 1), # C3
InvertedResidualConfig( 80, 3, 200, 80, False, "HS", 1, 1, 1),
InvertedResidualConfig( 80, 3, 184, 80, False, "HS", 1, 1, 1),
InvertedResidualConfig( 80, 3, 184, 80, False, "HS", 1, 1, 1),
InvertedResidualConfig( 80, 3, 480, 112, True, "HS", 1, 1, 1),
InvertedResidualConfig(112, 3, 672, 112, True, "HS", 1, 1, 1),
InvertedResidualConfig(112, 5, 672, 160, True, "HS", 2, 2, 1), # C4
InvertedResidualConfig(160, 5, 960, 160, True, "HS", 1, 2, 1),
InvertedResidualConfig(160, 5, 960, 160, True, "HS", 1, 2, 1),
],
last_channel=1280
)
if pretrained:
self.load_state_dict(torch.hub.load_state_dict_from_url(
'https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth'))
del self.avgpool
del self.classifier
def forward(self, x):
x = self.features[0](x)
x = self.features[1](x)
f1 = x
x = self.features[2](x)
x = self.features[3](x)
f2 = x
x = self.features[4](x)
x = self.features[5](x)
x = self.features[6](x)
f3 = x
x = self.features[7](x)
x = self.features[8](x)
x = self.features[9](x)
x = self.features[10](x)
x = self.features[11](x)
x = self.features[12](x)
x = self.features[13](x)
x = self.features[14](x)
x = self.features[15](x)
x = self.features[16](x)
f4 = x
return [f1, f2, f3, f4]
在nets/backbone/init.py中添加:
from .mobilenetv3 import *
在nets/deeplabv3plus/model.py中添加如下代码:
def _segm_mobilenetv3(backbone_name, num_classes, pretrained_backbone):
aspp_dilate = [6, 12, 18]
backbone = MobilenetV3Encoder(
pretrained = pretrained_backbone
)
inplanes = 960
low_leval_planes = 24
decoder = DeepLabHeadV3Plus(inplanes, low_leval_planes, num_classes, aspp_dilate, isDSV = False)
model = _BaseSegmentationModel(backbone, decoder)
return model
def Deeplabv3plus_mobilenetv3(num_classes, pretrained):
return _segm_mobilenetv3("mobilenetv3", num_classes, pretrained)
1.2 AIFI模块
AIFI的主要思想。1.基于注意力的特征处理:AIFI模块利用自我注意力机制来处理图像中的高级特征。自我注意力是一种机制,它允许模型在处理特定部分的数据时,同时考虑到数据的其他相关部分。这种方法特别适用于处理具有丰富语义信息的高级图像特征。2.选择性特征交互:AIFI模块专注于在S5级别(即高级特征层)上进行内部尺度交互。这是基于认识到高级特征层包含更丰富的语义概念,能够更有效地捕捉图像中的概念实体间的联系。与此同时,避免在低级特征层进行相同的交互,因为低级特征缺乏必要的语义深度,且可能导致数据处理上的重复和混淆。
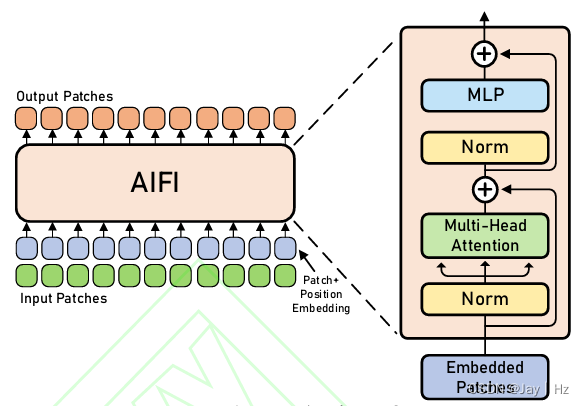
在nets/tricks/attentions.py中添加如下代码:
import torch
import torch.nn as nn
class TransformerEncoderLayer(nn.Module):
"""Defines a single layer of the transformer encoder."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
"""Initialize the TransformerEncoderLayer with specified parameters."""
super().__init__()
self.ma = nn.MultiheadAttention(c1, num_heads, dropout=dropout, batch_first=True)
# Implementation of Feedforward model
self.fc1 = nn.Linear(c1, cm)
self.fc2 = nn.Linear(cm, c1)
self.norm1 = nn.LayerNorm(c1)
self.norm2 = nn.LayerNorm(c1)
self.dropout = nn.Dropout(dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.act = act
self.normalize_before = normalize_before
@staticmethod
def with_pos_embed(tensor, pos=None):
"""Add position embeddings to the tensor if provided."""
return tensor if pos is None else tensor + pos
def forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with post-normalization."""
q = k = self.with_pos_embed(src, pos)
src2 = self.ma(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src))))
src = src + self.dropout2(src2)
return self.norm2(src)
def forward_pre(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with pre-normalization."""
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.ma(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src2))))
return src + self.dropout2(src2)
def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Forward propagates the input through the encoder module."""
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
class AIFI(TransformerEncoderLayer):
"""Defines the AIFI transformer layer."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
"""Initialize the AIFI instance with specified parameters."""
super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
def forward(self, x):
"""Forward pass for the AIFI transformer layer."""
c, h, w = x.shape[1:]
pos_embed = self.build_2d_sincos_position_embedding(w, h, c)
# Flatten [B, C, H, W] to [B, HxW, C]
x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))
return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):
"""Builds 2D sine-cosine position embedding."""
grid_w = torch.arange(int(w), dtype=torch.float32)
grid_h = torch.arange(int(h), dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij")
assert embed_dim % 4 == 0, "Embed dimension must be divisible by 4 for 2D sin-cos position embedding"
pos_dim = embed_dim // 4
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1.0 / (temperature**omega)
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]
1.3 NAM注意力
NAM全称Normalization-based Attention Module(基于归一化的注意力模块)。该模块采用的集成方式与CBAM注意力机制一样,即通道注意力+空间注意力,只不过NAM对两个注意力模块进行了重新设计。结果就是,通过调整,NAM注意力模块可以利用稀疏的权重惩罚来降低不太显著的特征的权重,使得整体注意力权重在计算上保持同样性能的情况下变得更加高效,缓解了模型精度与模型轻量化的矛盾。原代码中只给出了一种实现方式,如下所示。
在nets/tricks/attentions.py中添加:
import torch.nn as nn
import torch
from torch.nn import functional as F
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class Att(nn.Module):
def __init__(self, channels,shape, out_channels=None, no_spatial=True):
super(Att, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out1
1.4ACMix
ACmix是一种混合模型,结合了自注意力机制和卷积运算的优势。它的核心思想是,传统卷积操作和自注意力模块的大部分计算都可以通过1x1的卷积来实现。ACmix首先使用1x1卷积对输入特征图进行投影,生成一组中间特征,然后根据不同的范式,即自注意力和卷积方式,分别重用和聚合这些中间特征。这样,ACmix既能利用自注意力的全局感知能力,又能通过卷积捕获局部特征,从而在保持较低计算成本的同时,提高模型的性能。
在
import torch
import torch.nn as nn
def position(H, W, type, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1).to(type)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W).to(type)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3 * self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes,
kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1,
stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i // self.kernel_conv, i % self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h // self.stride, w // self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.dtype, x.is_cuda))
q_att = q.view(b * self.head, self.head_dim, h, w) * scaling
k_att = k.view(b * self.head, self.head_dim, h, w)
v_att = v.view(b * self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b * self.head, self.head_dim,
self.kernel_att * self.kernel_att, h_out,
w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att * self.kernel_att, h_out,
w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2) * (unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(
1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b * self.head, self.head_dim, self.kernel_att * self.kernel_att,
h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat(
[q.view(b, self.head, self.head_dim, h * w), k.view(b, self.head, self.head_dim, h * w),
v.view(b, self.head, self.head_dim, h * w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
1.5 C2f-SCconv
这个结构应该是结合yolov8中的c2f结构和SCconv卷积,下面代码给出了一个实现版本,与原文的中不太一样,有时间和精力的小伙伴可以参考原文进行修改。
在nets/tricks/necks.py中添加
import torch
import torch.nn.functional as F
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
### c2f-scconv
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num: int,
group_num: int = 16,
eps: float = 1e-10
):
super(GroupBatchnorm2d, self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.weight = nn.Parameter(torch.randn(c_num, 1, 1))
self.bias = nn.Parameter(torch.zeros(c_num, 1, 1))
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view(N, self.group_num, -1)
mean = x.mean(dim=2, keepdim=True)
std = x.std(dim=2, keepdim=True)
x = (x - mean) / (std + self.eps)
x = x.view(N, C, H, W)
return x * self.weight + self.bias
class SRU(nn.Module):
def __init__(self,
oup_channels: int,
group_num: int = 16,
gate_treshold: float = 0.5,
torch_gn: bool = True
):
super().__init__()
self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(
c_num=oup_channels, group_num=group_num)
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self, x):
gn_x = self.gn(x)
w_gamma = self.gn.weight / sum(self.gn.weight)
w_gamma = w_gamma.view(1, -1, 1, 1)
reweigts = self.sigomid(gn_x * w_gamma)
# Gate
w1 = torch.where(reweigts > self.gate_treshold, torch.ones_like(reweigts), reweigts) # 大于门限值的设为1,否则保留原值
w2 = torch.where(reweigts > self.gate_treshold, torch.zeros_like(reweigts), reweigts) # 大于门限值的设为0,否则保留原值
x_1 = w1 * x
x_2 = w2 * x
y = self.reconstruct(x_1, x_2)
return y
def reconstruct(self, x_1, x_2):
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1)
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1)
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1)
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel: int,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha * op_channel)
self.low_channel = low_channel = op_channel - up_channel
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False)
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False)
# up
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1,
padding=group_kernel_size // 2, groups=group_size)
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False)
# low
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1,
bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
# Split
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)
up, low = self.squeeze1(up), self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# Fuse
out = torch.cat([Y1, Y2], dim=1)
out = F.softmax(self.advavg(out), dim=1) * out
out1, out2 = torch.split(out, out.size(1) // 2, dim=1)
return out1 + out2
class ScConv(nn.Module):
def __init__(self,
op_channel: int,
group_num: int = 4,
gate_treshold: float = 0.5,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.SRU = SRU(op_channel,
group_num=group_num,
gate_treshold=gate_treshold)
self.CRU = CRU(op_channel,
alpha=alpha,
squeeze_radio=squeeze_radio,
group_size=group_size,
group_kernel_size=group_kernel_size)
def forward(self, x):
x = self.SRU(x)
x = self.CRU(x)
return x
class SCConv_enchance(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, g=1, dilation=1):
super().__init__()
self.conv = Conv(in_channels, out_channels, k=1)
self.RFAConv = ScConv(out_channels)
self.bn = nn.BatchNorm2d(out_channels)
self.gelu = nn.GELU()
def forward(self, x):
x = self.conv(x)
x = self.RFAConv(x)
x = self.gelu(self.bn(x))
return x
class Bottleneck_SCConv(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = SCConv_enchance(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_SCConv(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_SCConv(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
x = self.cv1(x)
x = x.chunk(2, 1)
y = list(x)
# y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
if __name__ == '__main__':
x = torch.randn(1, 256, 16, 16)
model = C2f_SCConv(256, 16)
print(model(x).shape)
2.实验部分
2.1训练mobilenet时
在train.py中按照代码中的注释修改即可,不需要冻结训练。需要注意的是,backbone部分的名称与nets/deeplabv3plus/model.py中定义的方法一致。

然后训练过程中注意数据集的加载路径和图片名称即可。
2.2mobilev3+NAM模块
AIFI模块一直卡在那里,不报错也不动,有点奇怪,有兴趣的朋友可以自行尝试。
按照上面的叙述添加NAM模块,需要在nets/deeplabv3plus/_deeplabv3plus.py中添加如下代码
from ..tricks import NAMAtt
class DeepLabHeadV3Plus_NAM(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36], isDSV = False):
super(DeepLabHeadV3Plus, self).__init__()
self.out1 = None
self.out2 = None
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.NAM = nn.Sequential(
NAMAtt(256))
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
#是否使用深监督
if isDSV:
self.out1 = nn.Sequential(
nn.Conv2d(48, num_classes, 1)
)
self.out2 = nn.Sequential(
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, x, low_feature, high_feature, isDSV = False):
low_level_feature = self.project(low_feature)
aspp_feature = self.aspp(high_feature)
aspp_feature = self.NAM(aspp_feature)
output_feature = F.interpolate(aspp_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
output_feature = self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
output_feature = F.interpolate(output_feature, size=x.shape[2:], mode='bilinear', align_corners=False)
if self.out1:
self.output1 = F.interpolate(self.out1(low_level_feature), size = x.shape[2:], mode = 'bilinear', align_corners=False)
self.output2 = F.interpolate(self.out2(aspp_feature), size = x.shape[2:], mode = 'bilinear', align_corners=False)
return [self.output1, self.output2, output_feature]
return output_feature
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
然后修改nets/deeplabv3plus/model.py中的代码,注释之前的decoder部分,引用新的head
def _segm_mobilenetv3(backbone_name, num_classes, pretrained_backbone):
aspp_dilate = [6, 12, 18]
backbone = MobilenetV3Encoder(
pretrained = pretrained_backbone
)
inplanes = 960
low_leval_planes = 24
# decoder = DeepLabHeadV3Plus(inplanes, low_leval_planes, num_classes, aspp_dilate, isDSV = False)
decoder = DeepLabHeadV3Plus_NAM(inplanes, low_leval_planes, num_classes, aspp_dilate, isDSV = False)
model = _BaseSegmentationModel(backbone, decoder)
return model
然后训练train.py,保持和训练mobilenetv3时一样的参数即可
2.3mobilev3+NAM+ACMix
同理在nets/deeplabv3plus/_deeplabv3plus.py文件中添加如下代码:
class DeepLabHeadV3Plus_ACMix(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36], isDSV = False):
super(DeepLabHeadV3Plus_ACMix, self).__init__()
self.out1 = None
self.out2 = None
self.acmix = ACmix(low_level_channels, low_level_channels)
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.NAM = nn.Sequential(
NAMAtt(256))
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
#是否使用深监督
if isDSV:
self.out1 = nn.Sequential(
nn.Conv2d(48, num_classes, 1)
)
self.out2 = nn.Sequential(
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, x, low_feature, high_feature, isDSV = False):
low_level_feature = self.project(self.acmix(low_feature))
aspp_feature = self.aspp(high_feature)
aspp_feature = self.NAM(aspp_feature)
output_feature = F.interpolate(aspp_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
output_feature = self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
output_feature = F.interpolate(output_feature, size=x.shape[2:], mode='bilinear', align_corners=False)
if self.out1:
self.output1 = F.interpolate(self.out1(low_level_feature), size = x.shape[2:], mode = 'bilinear', align_corners=False)
self.output2 = F.interpolate(self.out2(aspp_feature), size = x.shape[2:], mode = 'bilinear', align_corners=False)
return [self.output1, self.output2, output_feature]
return output_feature
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
然后和NAM一样,将decoder更改
decoder = DeepLabHeadV3Plus_ACMix(inplanes, low_leval_planes, num_classes, aspp_dilate, isDSV = False)
2.4mobilev3+NAM+ACMix+C2f_SCCONV
class DeepLabHeadV3Plus_ACMix_C2F(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36], isDSV = False):
super(DeepLabHeadV3Plus_ACMix_C2F, self).__init__()
self.out1 = None
self.out2 = None
self.acmix = ACmix(low_level_channels, low_level_channels)
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.NAM = nn.Sequential(
NAMAtt(256))
self.classifier = nn.Sequential(
C2f_SCConv(304, 256),
nn.Conv2d(256, num_classes, 1)
)
#是否使用深监督
if isDSV:
self.out1 = nn.Sequential(
nn.Conv2d(48, num_classes, 1)
)
self.out2 = nn.Sequential(
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, x, low_feature, high_feature, isDSV = False):
low_level_feature = self.project(self.acmix(low_feature))
aspp_feature = self.aspp(high_feature)
aspp_feature = self.NAM(aspp_feature)
output_feature = F.interpolate(aspp_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
output_feature = self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
output_feature = F.interpolate(output_feature, size=x.shape[2:], mode='bilinear', align_corners=False)
if self.out1:
self.output1 = F.interpolate(self.out1(low_level_feature), size = x.shape[2:], mode = 'bilinear', align_corners=False)
self.output2 = F.interpolate(self.out2(aspp_feature), size = x.shape[2:], mode = 'bilinear', align_corners=False)
return [self.output1, self.output2, output_feature]
return output_feature
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
同理修改model.py
decoder = DeepLabHeadV3Plus_ACMix_C2F(inplanes, low_leval_planes, num_classes, aspp_dilate, isDSV = False)
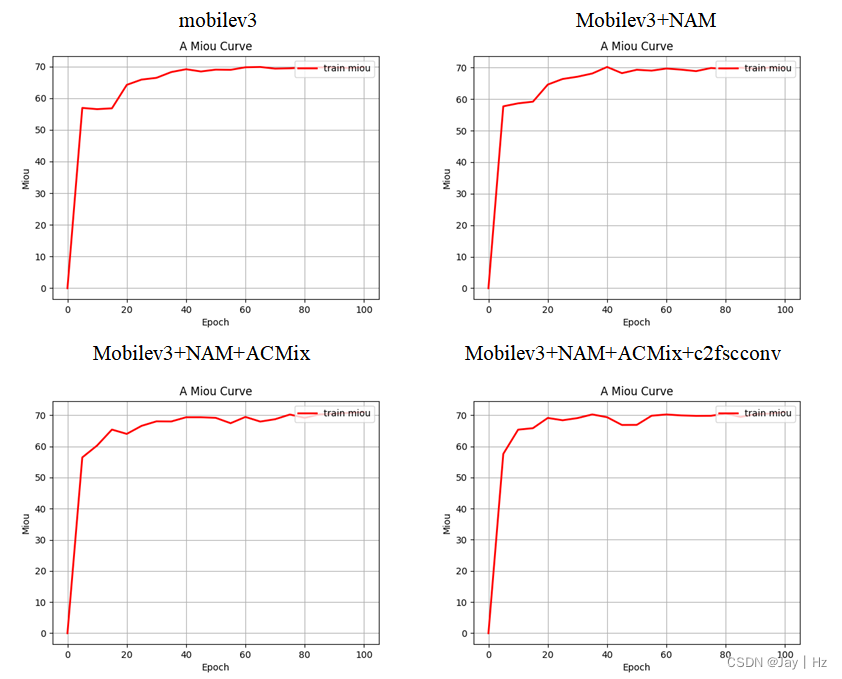
3实验结果展示
mobilev3:69.85
mobilev3+Nam:70.21
mobilev3+Nam+ACmix:71.06
mobilev3+Nam+ACmix+c2f:71.01
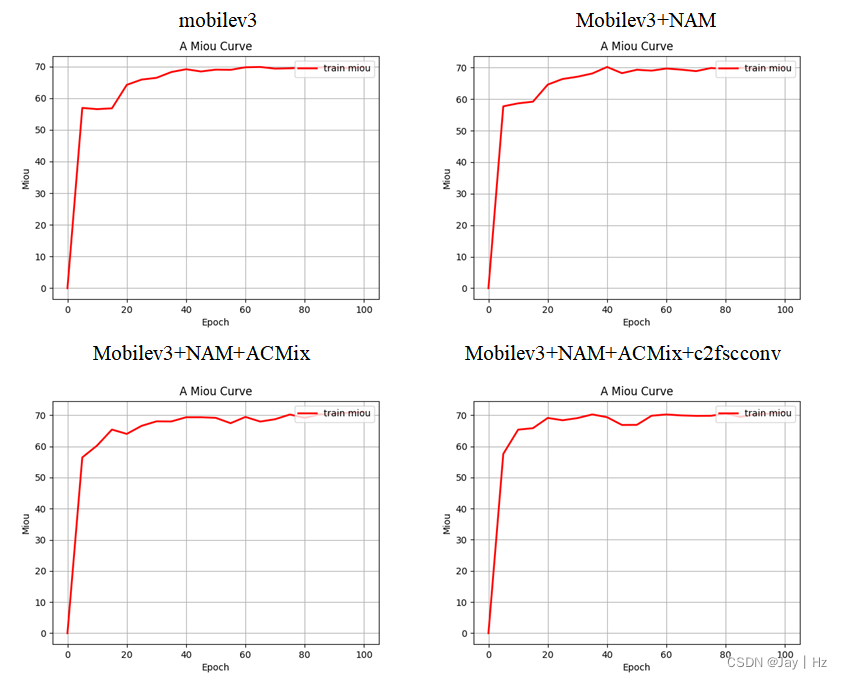

总结
按照论文中的方法,依次进行了实验,AIFI模块没有成功,但是代码在文中给出了,有兴趣的小伙伴可以自行尝试。依次添加trick确实可以提点,除了加入c2fscconv模块。但由于我的实现和原文有一点不同,也许会造成影响。
整体来说训练出来的模型能够较为准确的分割出路面上的裂纹,但是整体iou不高。其原因还是数据集的问题,我这个裂纹数据集是在网上随便找的,比较杂乱,如果用论文中的数据集精度应该差不多了太多。
有精力有时间的小伙伴可以按照我的文章一步步复现效果,本专栏的初衷也是希望大家照着一步步实现。如果急需项目的则可以直接点击链接购买,(内含该项目的所有代码,以及实验和结果,可直接使用)。整个专栏费用很低,全部都是干货,希望大家理解,毕竟服务器费用不便宜。















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









