







 超级会员免费看
超级会员免费看
基于改进Deeplabv3+的液压管道分割算法(一)
前言
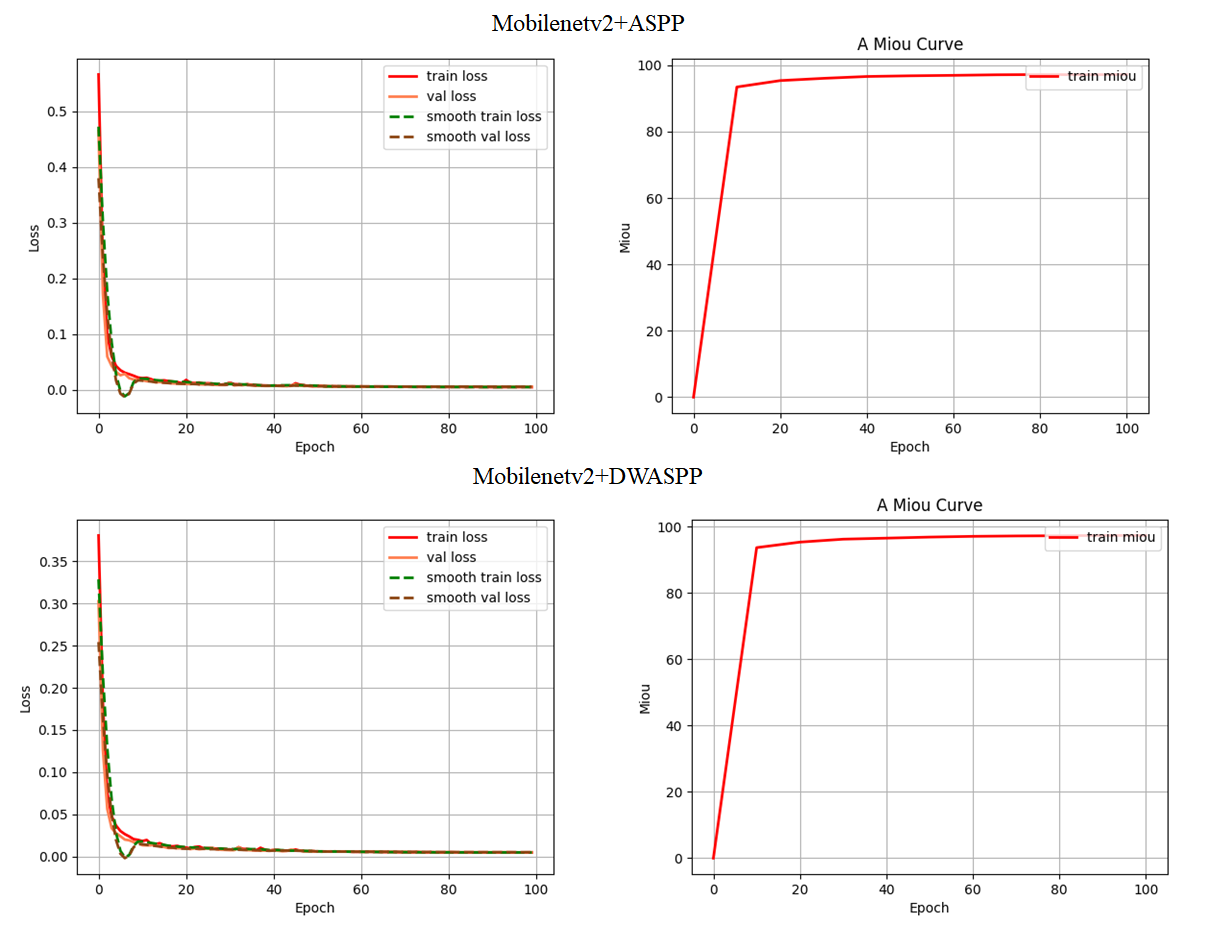
本文在论文[1]的基础上进行修改后复现,数据集使用的是独家液压管道数据集,旨在方法上的复现,供各位小伙伴们参考。首先,在DeepLabv3+模型中引入轻量级主干网络MobileNetv2(原文为自己设计的MFENet,这个复现有点花时间,后面机会再弄),用于提取形状各异、大小不一的瑕疵特征;其次,引入卷积注意力模块和空间通道注意力模块,分别实现对细小目标边界信息的捕捉和瑕疵区域的关注;接着,在解码部分添加两类多层次特征融合模块,以减少细节信息丢失问题。整个改进还是非常成功的,参数量大幅减少,且精度没有下降。
试读文章

参考文章:《DeepLabv3++:一种基于语义分割的布匹瑕疵检测模型_潘海鹏》,Deeplabv3+基础实现
参考代码:

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









