









Improving the Faithfulness of Attention-based Explanations with Task-specifific Information for Text Classifification
1. 必备知识
模型的可解释性:对神经网络的解释可以通过识别输入的哪些部分对给定的预测很重要来获得。一种方法是使用更容易解释的稀疏线性元模型。另一种方法是计算保留和省略输入标记之间的模型预测差异。
2. Motivation
在自然语言处理中,神经网络架构经常使用注意机制来在输入token表示上产生概率分布。注意力已被经验证明可以提高各种任务的表现,而其权重已被广泛用于模型预测的解释。最近的研究发现相反的注意力分布可以产生与原始的注意力分布等价的预测,这表明注意力的权重并不能提供可靠的解释,因此有研究人员认为它不能被认为是编码器和任务的忠实解释,而本文作者尝试通过将特定于任务的信息引入注意力权重来提高文本分类不同编码器之间基于注意力的解释的忠实度。
3. Method
3.1 Neural Text Classification Models
传统的用attention机制进行文本分类任务的做法是:对于每个输入的token都有其对应的one-hot-embedding,这个embedding e i e_i ei之后被送入编码器产生隐状态:
h i = E n c ( e i ) h_i=Enc(e_i) hi=Enc(ei)
整个输入的文本序列由 h i h_i hi通过attention分数 a i a_i ai加权求和获得:
c = ∑ i c i , c i = h i α i , c ∈ R N c=\sum_i c_i, c_i=h_i\alpha_i,c∈R^N c=i∑ci,ci=hiαi,c∈RN
最终,向量c经过一个全连接层,再经过softmax激活函数之后预测标签。
Encoders
编码器包括循环、非循环以及transformer的编码器,大致有双向LSTM, GRU, CNN, MLP, BERT
Attention Mechanisms
由编码器获得的隐状态 h i h_i hi参与attention分数的计算,计算公式如下所示:
a i = exp ( ϕ ( h i , q ) ) ∑ k = 1 t exp ( ϕ ( q , h k ) ) a_i=\frac{\exp(\phi(h_i,q))}{\sum_{k=1}^t \exp(\phi(q,h_k))} ai=∑k=1texp(ϕ(q,hk))exp(ϕ(hi,q))
其中 q q q是一个可训练的self-attention向量。公式中的 ϕ \phi ϕ函数致有两种实现方式,一个是tanh,一个是dot
ϕ ( h i , q ) = q T tanh ( W h i ) \phi(h_i,q)=q^T \tanh(Wh_i) ϕ(hi,q)=qTtanh(Whi)
ϕ ( h i , q ) = h i T N \phi(h_i,q)=\frac{h_i^T}{\sqrt{N}} ϕ(hi,q)=NhiT
3.2 Task-Scaling (TaSc) Mechanisms
受到简洁且高解释性的词袋模型的启发,其赋予每一个单词单独的权重,作者假设通过attention分数和非语境的词形分数来获得输入单词的语境表示 c i c_i ci,提高基于attention的可解释性。作者觉得获得一个更少语境序列表示的向量 c c c就可以减少attention的信息混合,因此作者提出了一种非语境的此类型分数 s x i s_{x_i} sxi来丰富文本表示 c c c
c = ∑ i h i α i s x i , c ∈ R N c=\sum_i{h_i\alpha_is_{x_i}},c∈R^N c=i∑hiαisxi,c∈RN
主要有三种机制来计算 s x i s_{x_i} sxi
1. Linear TaSc (Lin-TaSc)
该方法通过一个新的向量 u u u来估计词表里每个单词的标量权重。给定输入序列,通过查询 u u u获得每个单词的标量权重,而u会被随机初始化,并在每个训练步中更新一部分,因为每个输入序列的单词只是单词表的一个子集。之后可以获得基于任务限制的每个输入token的新的embedding e ^ i \hat e_i e^i
e ^ i = u i e i \hat e_i=u_ie_i e^i=uiei
直觉上来说,向量 e i e_i ei是训练在大规模语料库上的embedding向量,是与上下文无关的单词本身的表示;而作者追加一个系数 u i u_i ui可以将适配 e i e_i ei至特定任务上,得到更符合该任务的表示。便 s x i s_{x_i} sxi可由独立用上下文但是又面向任务的embedding求和得到:
s x i = ∑ d e ^ i s_{x_i}=\sum^d \hat e_i sxi=∑de^i
这里只进行求和而不加以平均,目的在于保持原本面向任务的或大或小的embedding。因为之前的attention分数只能反映关于文本上下文单词的关注程度,作者的这种做法在于引入关于单词本身的非上下文信息,从而使得attention分数能够获得表意更丰富的序列表示c。
2. Feature-wise TaSc (Feat-TaSc)
上述所说的Lin-TaSc对于embedding所有维度上给予相同的权重,但是有时候这些维度重要性并不相同。这里提出的Feature-wise TaSc旨在给每个维度的向量学习不同的重要性分数。
为了实现这一目的,作者又新设定了一个学习矩阵 U U U。类似于Lin-TaSc,对于每一个输入序列x,查询 U U U获得每个单词的重要性分数向量 u i u_i ui,矩阵 U U U每一次训练都会更新一部分权重。此时, s x i s_{x_i} sxi的计算如下:
s x i = u i ⋅ e i s_{x_i}=u_i·e_i sxi=ui⋅ei
3. Convolutional TaSc (Conv-TaSc)
Lin-TaSc以及Feat-TaSc两种机制改变了原始的词的embedding,但是没有考虑到embedding维度之间的交互。Conv-TaSc扩充了原始的Lin-TaSc,选择带有n channel的CNN,选择步幅为1,kernel为一维,这样会使输入的单词保持上下文独立性。通过CNN可以获得过滤后的embedding向量 e ^ i f \hat e_i^f e^if,最终的 s x i s_{x_i} sxi分数计算如下:
s x i = ∑ d e ^ i f s_{x_i}=\sum^d \hat e_i^f sxi=∑de^if
3.3 Evaluating Attention-based Interpretability
1. Attention-based Importance Metrics
α \alpha α:归一化后attention的分数
▽ α i \triangledown\alpha_i ▽αi:使用预测之后的标签对每个attention分数求梯度:
▽ α i = ∂ y ^ ∂ a i \triangledown\alpha_i=\frac{\partial{\hat y}}{\partial{a_i}} ▽αi=∂ai∂y^
α ▽ α \alpha\triangledown \alpha α▽α:使用归一化的attention分数乘上述梯度
2. Faithfulness Metrics
- Decision Flip - Most Informative Token:把一个句子中最重要的token去掉,计算最终预测正确率与之前的差值(预测的反转);
- Decision Flip - Fraction of Tokens:使得一个预测发生反转平均需要去掉多少个单词。
4. Experiment
4.1 Predictive Performance

- 所有的TaSc模型都获得了可比较的性能,并且在某些情况下,在数据集和注意机制上都优于NoTaSc。
4.2 Decision Flip: Most Informative Token
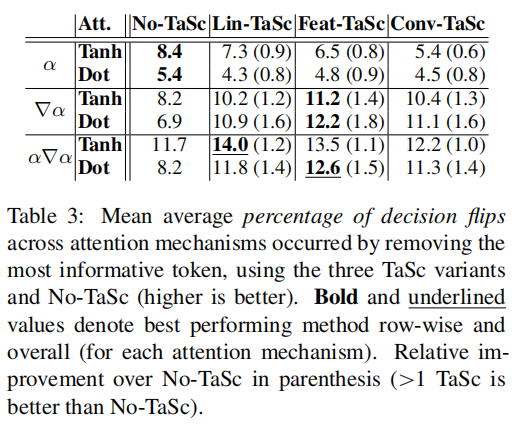
- TaSc变体在识别出最重要的单一标记方面非常有效,在基于注意力的重要性指标上,18个案例中有12个优于No-TaSc。这表明,当分配给输入标记的重要性时,注意机制受益于TaSc中封装的非情境化信息。
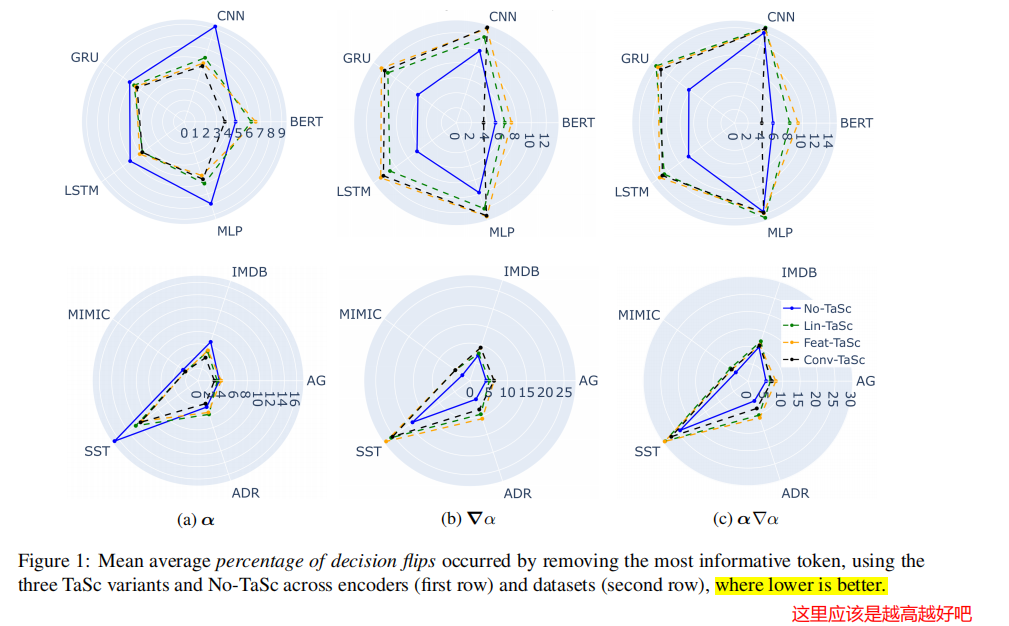
- 在使用∇α和α∇α的所有编码器变体上,TaSc变体实现了比No-TaSc更好的性能。
4.3 Decision Flip: Fraction of Tokens
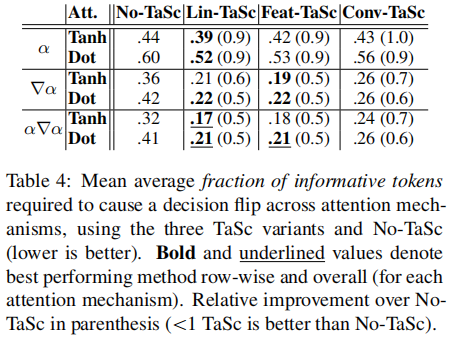
- 与No-TaSc相比,使用任何TaSc机制训练的模型的基于注意力的解释平均需要更低比例的令牌来触发Decision Flip
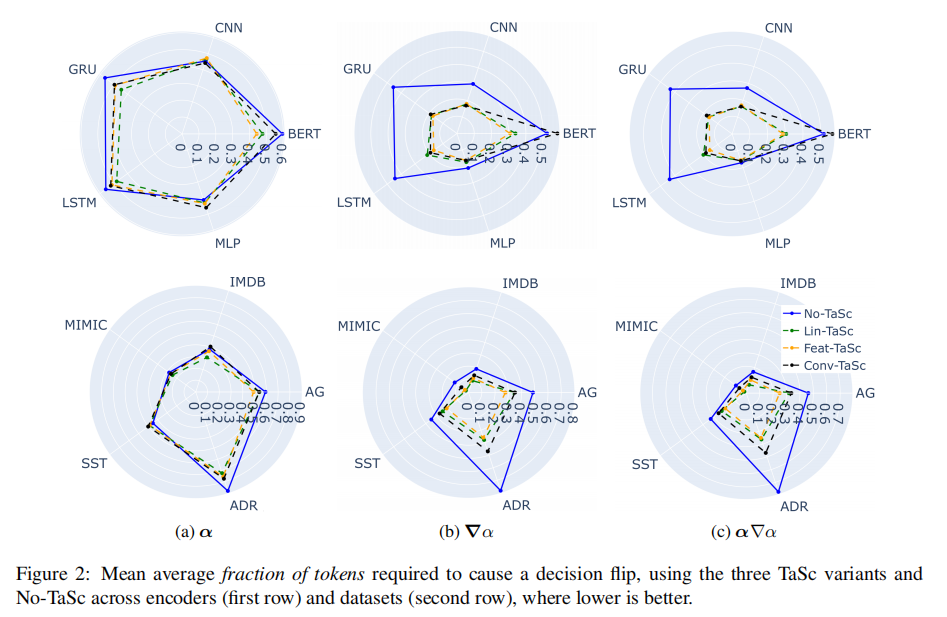
- 除了使用BERT的Conv-TaSc外,所有三个TaSc变体都获得了类似的性能。假设使用BERT,Conv-TaSc无法捕获嵌入维度之间的交互作用,因为这可能是由于BERT嵌入的上下文化程度更高(即包含更多的重复信息)。
4.4 Robustness Analysis
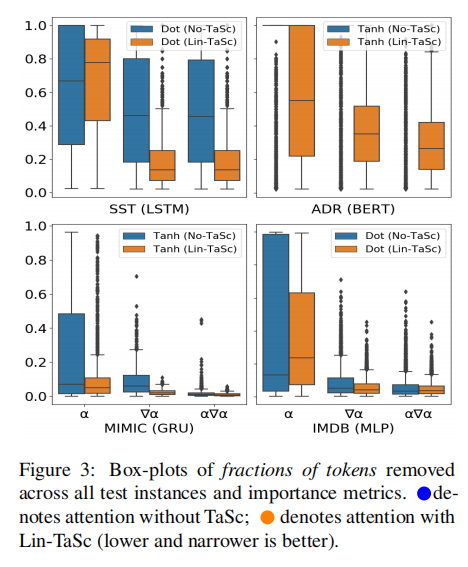
- 在某些情况下,使用α导致Lin-TaSc决策翻转所需的令牌的中位数比例高于No-TaSc。然而,与使用∇α和α∇α的No-TaSc相比,Lin-TaSc导致的中位数始终较低(方差显著减少),这是更有效的重要性指标。这在使用BERT的ADR中尤其明显,与No-TaSc相比,25%和75%的百分位数更接近中值。减少的方差表明,不同实例之间的解释忠实度保持一致。
4.5 Qualitative Analysis
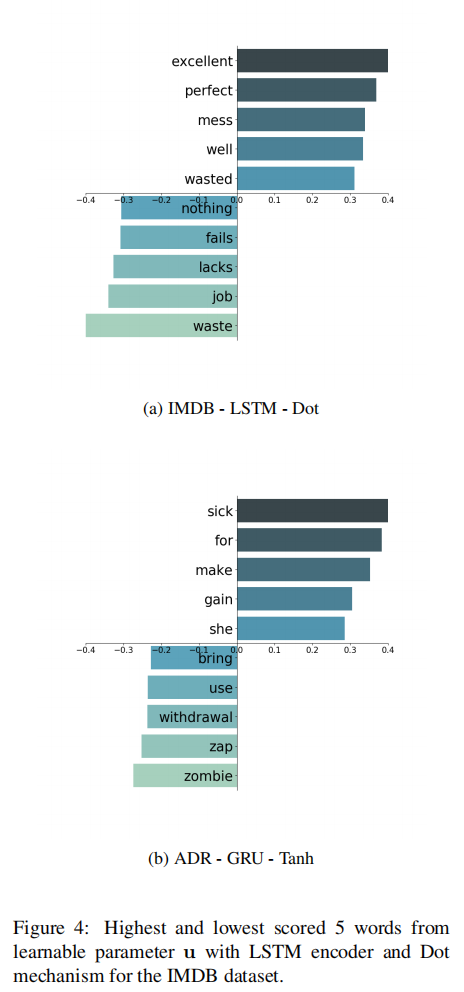
- 表达情感的单词确实被分配了很高的分数(例如,优秀的,浪费的,完美的),消极的则相反。
5. Conclusion
本文主要针对常见的attention机制的可解释性的真实性进行探索,并提出了一系列的attention改进版本;主要改进思路是针对原来attention只能关注到基于上下文的信息,而忽略了单词本身的信息,因此加入单词本身的信息并在相关任务上进行变动,为attention分数注入了基于任务的单词非语境信息,从而使得模型更能关注重要的单词;后续的大量实验也证明了这一点。
参考
知乎世界很大然并卵**














 2207
2207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









