









Paying More Attetion to Attention:Improving the Performance of Convolutional Neural Networks via Attention Transfer 论文阅读
Sergey Zagoruyko, Nikos Komodakis 2017 ICLR
摘要
(1)正确定义CNN的注意力,然后使用这种类型信息去迫使学生网络模仿强大的教师网络,从而极大改进学生网路性能。
(2)通过改进各种数据集和CNN网络架构,提出几种新颖的转移注意力的方法。
引言
人类为了充分认知环境需要注意,注意力是视觉经验和与感知密切相关的关键方面。人工注意力让系统更“关注”一个对象,从而获得更多细节。注意力就像心理学中的注意力,已成为理解CNN背后机制的研究工具。
非注意力和注意力感知过程的假设:
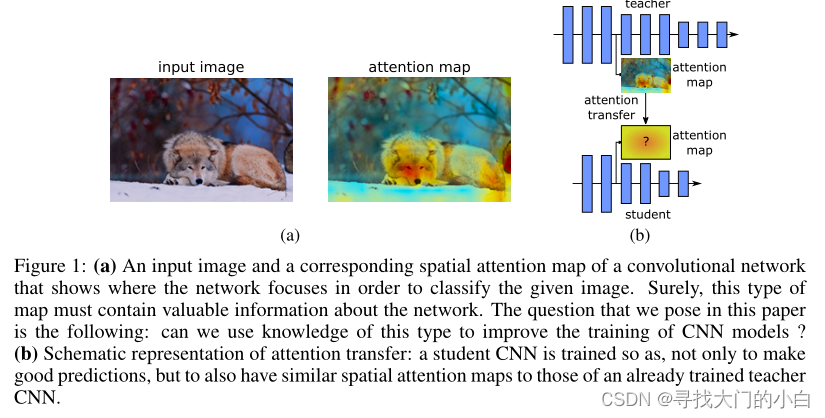
(1)非注意过程 有助于观察一般场景并获得高层信息,与其他思维方式相关联,可帮助我们控制注意力过程并定位到场景的某个部分,这表示具有不同知识、不同目标、不同策略的不同观察者能从字面上以不同方式看同一场景。引出本文主题:人工视觉系统的注意力有何不同,我们能用注意力信息改进网路性能么?总而言之,教师网路能否通过向学生网络提供其外观信息来提高学生网络性能?
本文将注意力视为一组空间图,通过编码网络最关注的空间区域来决定其输出(e.g.图像分类)这些图跟网络各个层有关,所以可以捕捉低、中、高层表示信息。本文定义两种空间注意图:activation-based 和 gradient-based
本文工作
1.提出一种将注意力作为知识从一个网络转移到另一个
2.提出使用activation-based 和 gradient-based的空间注意力图
3.在多个数据集和深度网络结构(残差或非残差)验证了本文方法的性能提升
activation-based注意力转移比full-activationtransfer更好,并且能与知识蒸馏(KD)结合
相关工作
早期工作 Larochelle & Hinton (2010), Denil et al. (2012)受人类注意力机制理论 Rensink (2000) 启发,并通过受限波兹曼机(Restricted Bolz-mann Machines)完成。使用RNN在神经机器翻译与其他NLP任务相当 e.g. Bahdanau et al. (2014)。计算机视觉相关任务也进行了探索如image captioning Xu et al. (2015), visual question answering Y ang et al. (2015), image captioning Xu et al. (2015), visual question answering Y ang et al. (2015)。以上所有任务注意力都有用。
可视化注意力图在深度卷积神经网络是一个开放的问题。最简单的基于梯度的方法是计算网络输出的雅可比行列式,例如 Simonyan et al. (2014)。
Zeiler & Fergus (2014)提出了另一个方法,该方法包括附加一个名为“deconvnet”的网络,该网络与原始网络共享权重,并用于将某些特征投影到图像平面上。
知识蒸馏(Knowledge distillation)首次被 Hinton et al. (2015)提出; Bucila et al.(2006)采用迁移学习方法,通过从强大的教师网络借来的知识训练学生网络。尽管在某些特殊情况下,浅层网络已被证明能够在不损失准确性的情况下与更深层的网络差不多 Lei & Caruana (2014),之后知识蒸馏相关工作大多假设更深的网络能学更好的表示,例如FitNets,Romero et al.(2014)尝试使用更多参数的浅层网络来学习薄的深层网络。一些网络如ResNet和 Srivastava et al. (2015)可以以更高的准确率训练非常深的架构,并在大量数据集上实验证明了泛化能力。尽管ResNet的主要动机是增加深度,但后来 Zagoruyko & Komodakis (2016)等表明在一定深度后,大多数改进只能从容量上。
基于以上事实和深度网络比更宽的网络更难并行,本文重新审视了知识转移,与 FitNets相反,尝试学习更浅的学生网络。本文用类似于gradient-based 和 activation-based maps作为注意力图,与FitNets里的“hints”作用一样,虽然我们没引入新的权重。
方法
1. Activation-based Attention Transfer
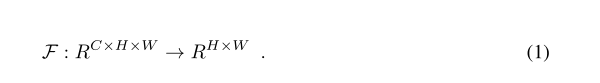
通过映射函数 F 将3D向量A∈R映射成扁平的2D向量(即空间注意力图)C为通道数。
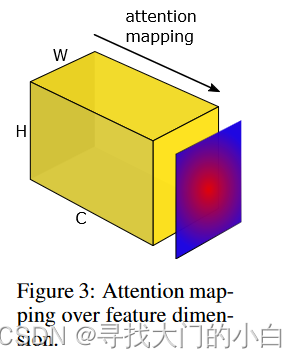
为了定义这样一个空间注意力映射函数,我们在本节中做出的隐含假设是隐藏神经元激活的绝对值(在给定输入上评估网络时产生的结果)可以用作关于那个神经元具体输入。因此,通过考虑张量 A元素的绝对值,我们可以通过计算这些值在通道维度上的统计数据来构建空间注意力图(见图 3)。
更具体地说,在这项工作中,我们将考虑以下基于激活的空间注意力图:
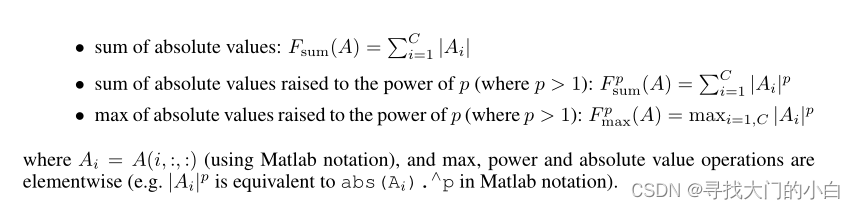
注意力图专注于网络中不同层的不同部分。在第一层中,低级梯度点的神经元激活水平较高,在中间,对于最具辨别力的区域(例如眼睛或车轮)较高,而在顶层,它反映了完整的对象。例如,为人脸识别训练的网络的中级注意力图 Parkhi et al. (2015)将在眼睛、鼻子和嘴唇周围有更高的激活,顶级激活将对应于全脸,如图
关于上面定义的不同的注意力映射函数,它们的属性可能略有不同。

在注意力转移中,给定教师网络的空间注意力图(使用上述任何注意力映射函数计算),目标是训练一个学生网络,该网络不仅可以做出正确的预测,而且具有类似于老师的注意力图。例如,在 ResNet 架构的情况下,可以考虑以下两种情况,具体取决于教师和学生的深度:
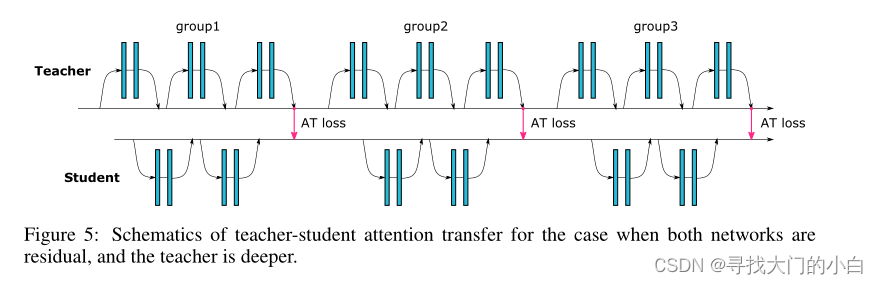
相同深度:可能在每个残差块之后都有注意力转移层
不同深度:对每组残差块的输出激活进行注意力转移
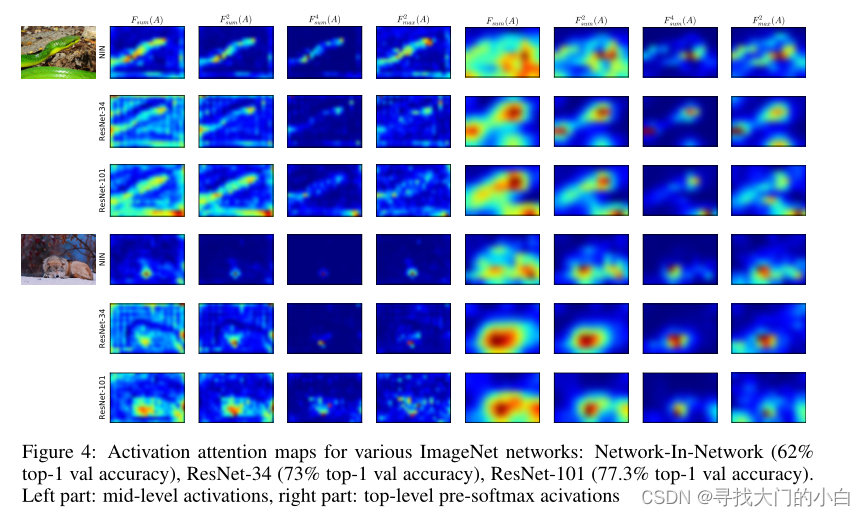
类似的情况也适用于其他架构(例如 NIN,在这种情况下,组指的是 3 × 3、1 × 1、1 × 1 卷积的块)。在图 5 中,我们提供了残差网络架构的不同深度情况的示意图。
不失一般性,我们假设转移损失放置在相同空间分辨率的学生和教师注意力图之间,但是,如果需要,可以对注意力图进行插值以匹配它们的形状。令 S, T 和 Ws, WT 分别表示学生、教师及其权重,令 L(W, x) 表示标准交叉熵损失。还让I 表示我们想要转移注意力图的所有师生激活层对的索引。然后我们可以定义以下总损失:

2. Gradient-based Attention Transfer
我们将教师和学生输入的损失梯度定义为:
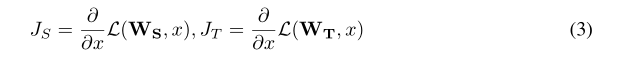
然后,如果我们希望学生梯度注意力类似于教师注意力,我们可以最小化它们之间的距离(这里我们使用 l2 距离,但也可以使用其他距离):
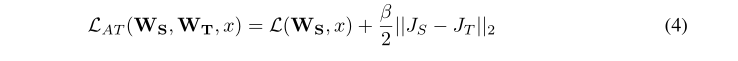
由于给出了 WT 和 x,得到所需的导数 w.r.t。 WS:
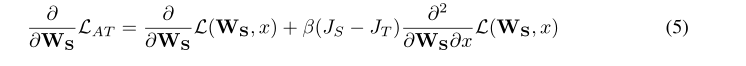
我们还提出在梯度注意力图上强制水平翻转不变性。为此,我们传播水平翻转的图像以及初始图、反向传播和翻转梯度注意力图。然后我们在获得的注意力和输出上添加 l2 损失,并进行第二次反向传播:
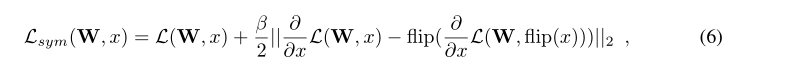
其中 flip(x) 表示翻转操作。这类似于Group Equivariant CNN方法Cohen & Welling (2016) ,但这不是硬性约束。实验表明这对训练有正则化作用。
实验
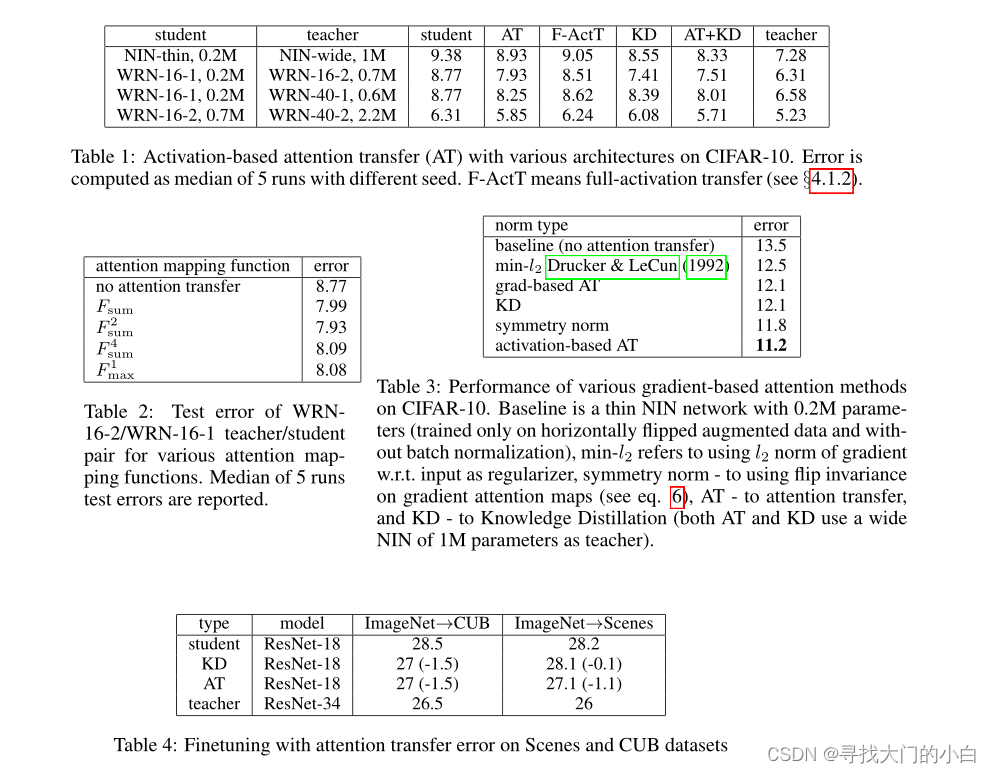
结论
我们提出了几种将注意力从一个网络转移到另一个网络的方法,并在多个图像识别数据集上获得了实验结果。看注意力转移在空间信息更重要的情况下如何工作会很有趣,例如。目标检测或弱监督定位,这是我们计划在未来探索的东西。
总的来说,我们认为我们有趣的发现将有助于进一步推进知识提炼,并总体上理解卷积神经网络。














 4383
4383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









