









1. Intuition
- 知识蒸馏通常用于模型压缩,用一个已经训练好的模型A去“教”另外一个模型B。这两个模型称为老师-学生模型。
- 通常模型A比模型B更强。在模型A的帮助下,模型B可以突破自我,学得更好。
下面举了一个水果分类的例子:

传统的训练:西红柿【1, 0, 0】,这是西红柿
有老师教:西红柿【1, 0, 0】+【0.7, 0.29, 0.01】,这是西红柿,但它跟柿子长得挺像。
2. Loss Function in Pytorch
2.1 Softmax:将一个数值序列映射到概率空间
函数Softmax(x):输入一个实数向量并返回一个概率分布。定义
x
x
x 是一个实数的向量(正数或负数都可以)。 然后,第$i个 Softmax(x) $的计算方式为:
exp
(
x
i
)
∑
j
exp
(
x
j
)
\frac{{\exp ({x_i})}}{{\sum\nolimits_j {\exp ({x_j})} }}
∑jexp(xj)exp(xi)
输出是一个概率分布: 每个元素都是非负的, 并且所有元素的总和都是1
import torch
import torch.nn.functional as F
torch.manual_seed(0)
<torch._C.Generator at 0x1ab80351250>
在图片分类问题中,输入m张图片,输出一个m*N的Tensor,其中N是分类类别总数。比如输入2张图片,分三类,最后的输出是一个2*3的Tensor,举个例子:
output = torch.randn(2, 3)
print(output)
tensor([[ 1.5410, -0.2934, -2.1788],
[ 0.5684, -1.0845, -1.3986]])
第1,2行分别是第1,2张图片的结果,假设第123列分别是猫、狗和猪的分类得分。
可以看出模型认为两张都更可能是猫。 然后对每一行使用Softmax,这样可以得到每张图片的概率分布。
print(F.softmax(output, dim=1))
# 这里dim的意思是计算Softmax的维度,这里设置dim=1,可以看到每一行的加和为1。
tensor([[0.8446, 0.1349, 0.0205],
[0.7511, 0.1438, 0.1051]])
2.2 log_softmax:在softmax的基础上取对数
print(F.log_softmax(output, dim=1))
print(torch.log(F.softmax(output, dim=1)))
# 输出结果是一致的
tensor([[-0.1689, -2.0033, -3.8886],
[-0.2862, -1.9392, -2.2532]])
tensor([[-0.1689, -2.0033, -3.8886],
[-0.2862, -1.9392, -2.2532]])
2.3 NLLLoss:对log_softmax与one-hot进行计算
该函数的全程是negative log likelihood loss. 若
x
i
=
[
q
1
,
q
2
,
.
.
.
,
q
N
]
x_i=[q_1, q_2, ..., q_N]
xi=[q1,q2,...,qN] 为神经网络对第i个样本的输出值,
y
i
y_i
yi为真实标签。则:
f
(
x
i
,
y
i
)
=
−
q
y
i
f(x_i,y_i)=-q_{y_i}
f(xi,yi)=−qyi
输入:log_softmax(output), target
print(F.nll_loss(torch.tensor([[-1.2, -2, -3]]), torch.tensor([0])))
tensor(1.2000)
通常我们结合 log_softmax 和 nll_loss一起用
output = torch.tensor([[1.2, 2, 3]])
target = torch.tensor([0])
log_sm_output = F.log_softmax(output, dim=1)
print('Output is [1.2, 2, 3]. If the target is 0, loss is:', F.nll_loss(log_sm_output, target))
target = torch.tensor([1])
log_sm_output = F.log_softmax(output, dim=1)
print('Output is [1.2, 2, 3]. If the target is 1, loss is:', F.nll_loss(log_sm_output, target))
target = torch.tensor([2])
log_sm_output = F.log_softmax(output, dim=1)
print('Output is [1.2, 2, 3]. If the target is 2, loss is:', F.nll_loss(log_sm_output, target))
Output is [1.2, 2, 3]. If the target is 0, loss is: tensor(2.2273)
Output is [1.2, 2, 3]. If the target is 1, loss is: tensor(1.4273)
Output is [1.2, 2, 3]. If the target is 2, loss is: tensor(0.4273)
2.4 CrossEntropy:衡量两个概率分布的差别
在分类问题中,CrossEntropy等价于log_softmax 结合 nll_loss(CrossEntropy用于衡量两个概率分布的差异,若其中一个概率分布为one-hot形式,则可以使用Log_softmax+NLLLoss代替交叉熵。)
N N N分类问题,对于一个特定的样本,已知其真实标签,CrossEntropy的计算公式为:
c r o s s _ e n t r o p y = − ∑ k = 1 N ( p k ∗ log q k ) cross\_entropy=-\sum_{k=1}^{N}\left(p_{k} * \log q_{k}\right) cross_entropy=−k=1∑N(pk∗logqk)
其中p表示真实值,在这个公式中是one-hot形式;q是经过softmax计算后的结果, q k q_k qk为神经网络认为该样本为第 k k k类的概率。
仔细观察可以知道,因为p的元素不是0就是1,而且又是乘法,所以很自然地我们如果知道1所对应的index,那么就不用做其他无意义的运算了。所以在pytorch代码中target不是以one-hot形式表示的,而是直接用scalar表示。若该样本的真实标签为 y y y,则交叉熵的公式可变形为:
c r o s s _ e n t r o p y = − ∑ k = 1 N ( p k ∗ log q k ) = − l o g q y cross\_entropy=-\sum_{k=1}^{N}\left(p_{k} * \log q_{k}\right)=-log \, q_{y} cross_entropy=−k=1∑N(pk∗logqk)=−logqy
output = torch.tensor([[1.2, 2, 3]])
target = torch.tensor([0])
log_sm_output = F.log_softmax(output, dim=1)
nll_loss_of_log_sm_output = F.nll_loss(log_sm_output, target)
print(nll_loss_of_log_sm_output)
tensor(2.2273)
output = torch.tensor([[1.2, 2, 3]])
target = torch.tensor([0])
ce_loss = F.cross_entropy(output, target)
print(ce_loss)
tensor(2.2273)
2.5 More about softmax
import numpy as np
def softmax(x):
x_exp = np.exp(x)
return x_exp / np.sum(x_exp)
output = np.array([0.1, 1.6, 3.6])
print(softmax(output))
[0.02590865 0.11611453 0.85797681]
def softmax_t(x, t):
x_exp = np.exp(x / t)
return x_exp / np.sum(x_exp)
output = np.array([0.1, 1.6, 3.6])
print(softmax_t(output, 5))
[0.22916797 0.3093444 0.46148762]
这里的t指的就是问题,也可以说是知识蒸馏中比较重要的一步
print(softmax_t(output, 10000))
[0.33327778 0.33332777 0.33339445]
3. Dark Knowledge
3.1 先训练Teacher网络
teacher.py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data
torch.manual_seed(0)
torch.cuda.manual_seed(0)
class TeacherNet(nn.Module):
def __init__(self):
super(TeacherNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.3)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
output = self.fc2(x)
return output
def train_teacher(model, device, train_loader, optimizer, epoch):
model.train()
trained_samples = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
trained_samples += len(data)
progress = math.ceil(batch_idx / len(train_loader) * 50)
print("\rTrain epoch %d: %d/%d, [%-51s] %d%%" %
(epoch, trained_samples, len(train_loader.dataset),
'-' * progress + '>', progress * 2), end='')
def test_teacher(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, correct / len(test_loader.dataset)
def teacher_main():
epochs = 10
batch_size = 64
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True)
model = TeacherNet().to(device)
optimizer = torch.optim.Adadelta(model.parameters())
teacher_history = []
for epoch in range(1, epochs + 1):
train_teacher(model, device, train_loader, optimizer, epoch)
loss, acc = test_teacher(model, device, test_loader)
teacher_history.append((loss, acc))
torch.save(model.state_dict(), "teacher.pt")
return model, teacher_history
# 训练教师网络
teacher_model, teacher_history = teacher_main()
3.2 Teacher网络的暗知识
import numpy as np
from matplotlib import pyplot as plt
def softmax_t(x, t):
x_exp = np.exp(x / t)
return x_exp / np.sum(x_exp)
test_loader_bs1 = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1, shuffle=True)
teacher_model.eval()
with torch.no_grad():
data, target = next(iter(test_loader_bs1))
data, target = data.to('cuda'), target.to('cuda')
output = teacher_model(data)
test_x = data.cpu().numpy()
y_out = output.cpu().numpy()
y_out = y_out[0, ::]
print('Output (NO softmax):', y_out)
plt.subplot(3, 1, 1)
plt.imshow(test_x[0, 0, ::])
plt.subplot(3, 1, 2)
plt.bar(list(range(10)), softmax_t(y_out, 1), width=0.3)
plt.subplot(3, 1, 3)
plt.bar(list(range(10)), softmax_t(y_out, 10), width=0.3)
plt.show()
4. Teacher-Student
4.1 整体流程图
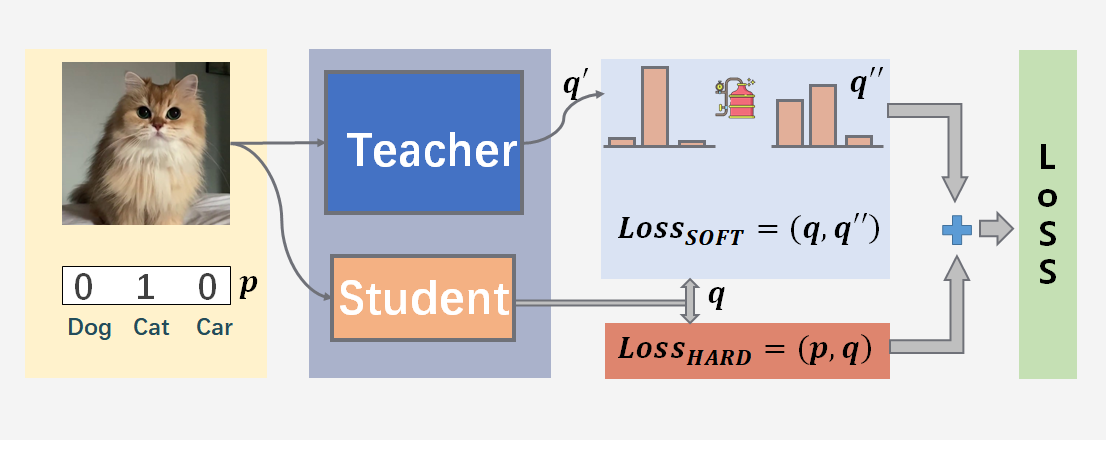
4.2 让老师教学生网络
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data
from teacher import teacher_model
class StudentNet(nn.Module):
def __init__(self):
super(StudentNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
output = F.relu(self.fc3(x))
return output
# 关键,定义kd的loss
def distillation(y, labels, teacher_scores, temp, alpha):
return nn.KLDivLoss()(F.log_softmax(y / temp, dim=1), F.softmax(teacher_scores / temp, dim=1)) * (
temp * temp * 2.0 * alpha) + F.cross_entropy(y, labels) * (1. - alpha)
def train_student_kd(model, device, train_loader, optimizer, epoch):
model.train()
trained_samples = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
teacher_output = teacher_model(data)
teacher_output = teacher_output.detach() # 切断老师网络的反向传播,感谢B站“淡淡的落”的提醒
loss = distillation(output, target, teacher_output, temp=5.0, alpha=0.7)
loss.backward()
optimizer.step()
trained_samples += len(data)
progress = math.ceil(batch_idx / len(train_loader) * 50)
print("\rTrain epoch %d: %d/%d, [%-51s] %d%%" %
(epoch, trained_samples, len(train_loader.dataset),
'-' * progress + '>', progress * 2), end='')
def test_student_kd(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, correct / len(test_loader.dataset)
def student_kd_main():
epochs = 10
batch_size = 64
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True)
model = StudentNet().to(device)
optimizer = torch.optim.Adadelta(model.parameters())
student_history = []
for epoch in range(1, epochs + 1):
train_student_kd(model, device, train_loader, optimizer, epoch)
loss, acc = test_student_kd(model, device, test_loader)
student_history.append((loss, acc))
torch.save(model.state_dict(), "student_kd.pt")
return model, student_history
student_kd_model, student_kd_history = student_kd_main()
4.3 学生单独去学
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data
from student import StudentNet,student_kd_history
from teacher import teacher_history
## 让学生自己学,不使用KD
def train_student(model, device, train_loader, optimizer, epoch):
model.train()
trained_samples = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
trained_samples += len(data)
progress = math.ceil(batch_idx / len(train_loader) * 50)
print("\rTrain epoch %d: %d/%d, [%-51s] %d%%" %
(epoch, trained_samples, len(train_loader.dataset),
'-' * progress + '>', progress * 2), end='')
def test_student(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, correct / len(test_loader.dataset)
def student_main():
epochs = 10
batch_size = 64
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data/MNIST', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True)
model = StudentNet().to(device)
optimizer = torch.optim.Adadelta(model.parameters())
student_history = []
for epoch in range(1, epochs + 1):
train_student(model, device, train_loader, optimizer, epoch)
loss, acc = test_student(model, device, test_loader)
student_history.append((loss, acc))
torch.save(model.state_dict(), "student.pt")
return model, student_history
student_simple_model, student_simple_history = student_main()
import matplotlib.pyplot as plt
epochs = 10
x = list(range(1, epochs+1))
plt.subplot(2, 1, 1)
plt.plot(x, [teacher_history[i][1] for i in range(epochs)], label='teacher')
plt.plot(x, [student_kd_history[i][1] for i in range(epochs)], label='student with KD')
plt.plot(x, [student_simple_history[i][1] for i in range(epochs)], label='student without KD')
plt.title('Test accuracy')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(x, [teacher_history[i][0] for i in range(epochs)], label='teacher')
plt.plot(x, [student_kd_history[i][0] for i in range(epochs)], label='student with KD')
plt.plot(x, [student_simple_history[i][0] for i in range(epochs)], label='student without KD')
plt.title('Test loss')
plt.legend()
5. Theoretical Analysis
L2正则化:
l o s s = C E ( y ^ , y ) + λ ∣ ∣ W ∣ ∣ 2 2 loss=CE(\hat y,y)+\lambda||W||_2^2 loss=CE(y^,y)+λ∣∣W∣∣22
C E ( y ^ , y ) CE(\hat y,y) CE(y^,y)算的是极大似然likelihood,我们希望两个概率分布越接近越好,我们会minimize这个数, λ ∣ ∣ W ∣ ∣ 2 2 \lambda||W||_2^2 λ∣∣W∣∣22先验知识prior,是人为加进去的。
KD:
l o s s = C E ( y ^ , y ) + λ l o s s _ s o f t ( y ^ , y ) loss=CE(\hat y,y)+\lambda loss\_soft(\hat y,y) loss=CE(y^,y)+λloss_soft(y^,y)
参考B站 不打不相识















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









