







分类决策树是一种描述对实例进行分类的树形结构。决策树由节点和有向边组成,节点有两种类型,内部节点和叶节点。内部节点表示一个特征或者属性,叶节点表示一个类。
决策树的算法通常递归的选择最优特征。首先,构建根节点,将所有的训练数据集都放在根节点,选择一个最优特征,按照这个特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果还有子集不能被基本分类,那么继续对这些子集选择新的最优特征,继续对其进行分割,如此递归下去,直到所有训练子集基本分类正确。
那么怎么选择最佳特征呢?决策树使用信息增益来进行判断。
1.信息增益
熵是表示随机变量不确定性的度量。设 X 是一个有限取值的离散随机变量,其概率分布为
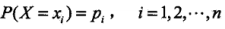
则随机变量 X 的熵定义为
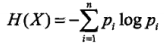
定义 0log0 = 0。由于熵之依赖于 X 的分布,而与 X 的取值无关,所以将 X 的熵记作H(p)。熵越大,随机变量的不确定性就越大。
设有随机变量 (X, Y) ,其联合概率分布为
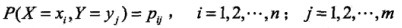
则条件熵 H(Y|X) 表示在已知随机变量 X 的条件下随机变量 Y 的不确定性,其定义为
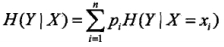
其中
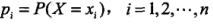
有了上述两个定义之后就可以得到信息增益。信息增益表示得知特征 X 的信息而使得类 Y 的信息不确定性减少的程度。
特征 A 对训练集 D 的信息增益 g(D, A),定义为集合 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差,即
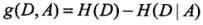
经验熵 H(D) 表示对数据集 D 进行分类的不确定性,而经验条件熵 H(D|A) 表示在特征 A 给定的条件下对数据集 D 进行分类的 不确定性。而信息增益则表示由于特征 A 而使得对数据集 D 的分类的不确定性减少的程度。
 信息增益计算步骤:
信息增益计算步骤:
 2. ID3 算法
2. ID3 算法
算法步骤:
输入:训练集 D ,特征集 A ,阈值 e
输出:决策树 T
1.若训练集 D 中所有的实例属于同一类 C,则决策树为单节点树,将 C 作为该节点的类标记,返回 T
2.若 A 为空集,则 T 为单节点树,并将 D 中实例树最大的类作为单节点的类标记,返回 T.
3.否则计算 A 中各特征对于 D 的信息增益,选择信息增益最大的特征 Ag,如果 Ag 的信息增益小于 e ,则设置 T 为单节点树,并将 D 中实例树最大的类作为该节点的类标记,返回T。否则,对 Ag 中每一个可能值 ai,依 Ag = ai 将 D 划分成若干非空子集 Di
4.对每个非空子集,利用除 Ag 以外的特征递归调用1~3步
3. ID3 算法C++代码
该方法为决策树ID3算法,针对 string 类型
//decisiongTree.h
#ifndef DECISIONTREE_H_
#define DECISIONTREE_H_
#include<string>
#include<vector>
#include<map>
using std::string;
using std::vector;
using std::map;
class decisionTree
{
public:
struct TreeNode
{
//节点信息
int Attribute; //此节点对应的第几个特征进行分割
string LeafNode; //如果是叶子节点,此值反映分类结果, 其他情况都是0;
vector<TreeNode*> children; //孩子节点的地址。
map<string, TreeNode*> AttributeLinkChildren;
//属性指向孩子节点,键表示属性值,值指向子节点,对应的树形结构中的树枝
};
decisionTree(string path = " ") :filePath(path){
}
bool readFile(vector<vector<string>>& dataSet, vector<string>& label);//读取txt文件
float calcShannonEnt(const vector<vector<string>>& dataSet);//计算熵
void splitDataSet(const vector<vector<string>>& dataSet, vector<vector<string>>&retDataSet, int axis, string value);//划分数据集
float chooseBestFeatureToSplit(const vector<vector<string>>& dataSet); //最佳划分特征
string majorityCnt(const vector<string>& classList);//叶子节点投票函数
void createTree(TreeNode* p,const vector<vector<string>>& dataSet);//建树
string predicet(TreeNode* p, const vector<string>data);//预测函数
private:
string filePath;
};
#endif
//实现文件
#include<iostream>
#include<map>
#include<opencv2/opencv.hpp>
#include<string>
#include<vector>
#include<set>
#include<fstream>
#include<sstream>
#include"decisionTree.h"
using std::set;
using std::vector;
using std::string;
using std::cout;
using std::endl;
using cv::Mat;
float decisionTree::calcShannonEnt(const vector<vector<string>>& dataSet)
{
/*
函数功能:计算熵
dataSet:样本集,最后一列为标签
*/
int len = dataSet.size 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











