






机器学习
什么是机器学习?
定义
有两种定义
Arthur Samuel described it as: “the field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition.
不通过明确的编程也能让计算机有能力学习
Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
如果计算机程序在 T 中的任务上的性能(由 P 衡量)随着经验 E 提高,则称该计算机程序从经验 E 中学习关于某类任务 T 和性能度量 P。
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
机器学习算法类型
无监督学习:让机器自己学习
监督学习 :教会机器学习
其他的:强化学习、推荐系统
监督学习
给算法一个正确的数据集(有对应结果),然后让这个算法能够通过另外的数据得到新的正确的答案。(也称为回归问题)
另一方面,一个数据集中可能有很多的特征(分类问题,如判断肿瘤的良性恶性),使用支持向量机的算法可以用数学技巧让计算机处理无限的数量特征。
总结:监督学习是我们有一个知道输入和输出相对应的数据集,通过找出他们之间的关系,来对新的输入进行输出的预测,它可以分成回归问题和分类问题,回归问题试图在连续输出中预测结果,分类问题则是在离散输出中预测结果。
无监督学习
无监督学习与监督学习相比,它没有明确目的的训练方式,不能知道结果是什么;无监督学习的数据也没有标签,不会被明确分类;无监督学习无法量化效果如何;
无监督学习的一些用法(聚类、降维):
1、发现异常。通过无监督学习,能够快速对行为进行分类,也许不能明白分类的依据,但是可以快速排除正确用户,对异常行为进行深入分析。
2、用户细分。通过很多维度的用户细分,能够让广告的投放更有针对性,效果也更好。
3、推荐系统 。无监督学习通过聚类推荐一些相关商品。
代价函数
如下所示可以为一个y=a+bx函数模型的代价函数,也被称作平方误差函数,平方误差代价函数。式子中m代表了样本的数量,h(x)代表模型的预测值,y则表示了真实值。θ0和θ1就对应了a和b的俩个参数。选择参数θ的目的是求的最小的代价函数,此类代价函数一般用于线性回归。
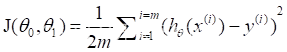
梯度下降
梯度下降算法能够使代价函数取得最小值
梯度下降算法如下:
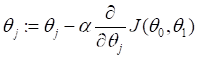
在此式子中,算法将会运行到程序拟合才停止。其中,j可以取0,1, := 表示赋值,α表示学习率,用来控制梯度下降时所跨出的步子。α越大,梯度下降速度就很大。α后面则是一个导数的表达式。
梯度下降线性回归公式,默认x(i)0的值都是1,i(上角标)代表第i个样本,j(下角标)代表第i个样本的第j个特征
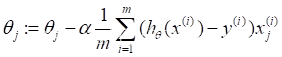
线性回归
形如:y = theta0 + theta1 * x1 + …
当拟合效果不是很好时,需用到上面的梯度下降方法。注意:在单特征时,可以求的最优解。但在多特征时,可能陷入局部最优解的问题。
也可使用正规方程直接求的最佳theta的值,其中theta = pinv(X’ * X) * X’ * y;注意:当数据十分大时,使用正规方程计算将花费大量时间。
Logistic回归
分类问题
邮件分类:是否为垃圾邮件
肿瘤分类:是否为恶性肿瘤
可以归结于一个y属于{0,1}的问题,0是负类,指不存在我们所期望的东西。1是正类,指存在我们所期望的
如何将预测值划分到(0,1)之间?
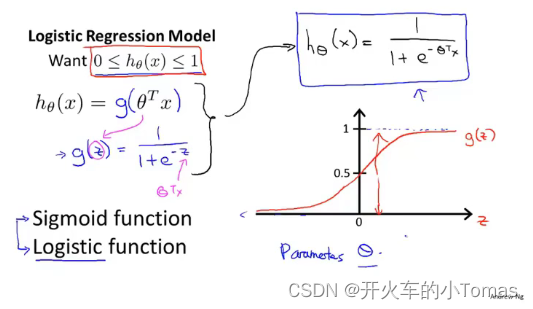
使用激活函数(sigmoid函数、Logistic函数),即如上图的右上角所示的函数。
一个简单例子:
将原来的线性回归函数作为参数,组成一个新的预测函数,其中第一个h-theta(x)函数是预测输出y=1的概率。

g(z)的函数图像如下:

此时,当z>=0时,函数g>=0.5,可以令输出y的值为1;z<0时,函数g<0.5,此时可令输出y的值为0。便可进行分类。又由上图可知当原来的线性回归函数值(theta’ * x)大于等于0时,输出y为1;当它小于0时,输出y为0。通过这个不等式,我们便可以确定决策边界。注意:决策边界仅由当时的参数决定,并不由数据集决定。
我们将h(x)的值当作是输入一个x,通过函数计算产生结果y=1的概率。
代价函数
从线性回归定义logistic的代价函数可以如下图所示,如果将蓝色箭头的函数代入到红色箭头函数,会发现代价函数的J(θ)是一个非凸函数,它有很多个局部最优点,所以梯度下降不一定能够收敛到全局最小值。
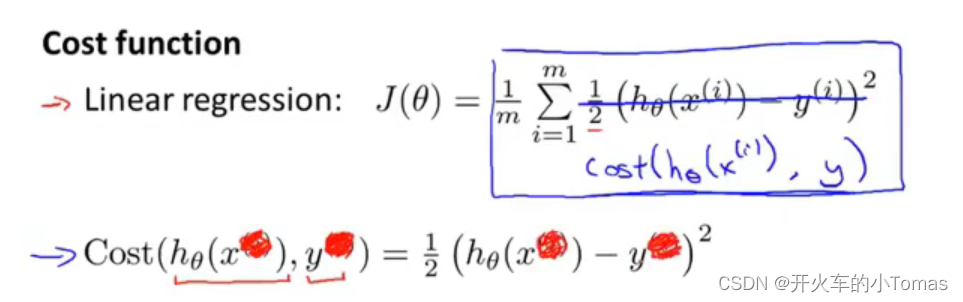
logistic代价函数模型,使用如下的函数可以使J(θ)为凸函数,从而可以使用梯度下降找到全局最优。当y=0的时候,代价函数如下图所示。我们预测值越接近1,代价就越大。我们预测值越接近0,代价也就越接近于0。(即实际不是恶性肿瘤时,预测为恶性肿瘤,代价高,预测不成功;预测为良性肿瘤,代价小,预测成功)
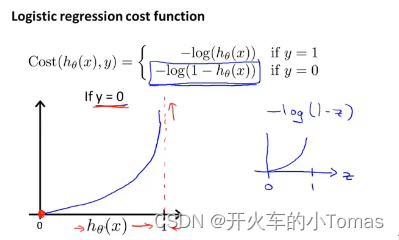
对代价函数进行简化,先看一下原来的代价函数定义

将y=1,y=0的式子相融合
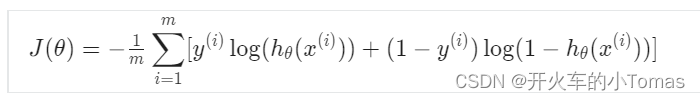
要求的最小代价的J,仍可以使用梯度下降法求的参数theta的最佳值。如下图

其他的优化算法
Conjugate gradient,BFGS,L-BFGS
优点在于不需要计算学习参数alpha,拟合速度比梯度下降快。
缺点是算法较为复杂,可以以后进行研究
调用方法:
一对多分类
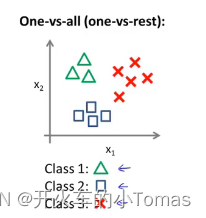
如上图,我们可以将其分解为三个独立的二元分类问题
拟合问题
欠拟合:(算法有高偏差)没有很好的拟合数据
过拟合:(算法有高方差)虽然拟合了数据集,但是各个拟合点之间的拟合线十分曲折,对新数据拟合的偏差较大
如何解决过拟合问题:
1、减少选取特征的数量(热力图,模型选择算法)
2、正则化(保留多特征,但是减少量级或参数theta的大小)
正则化处理数据
保留多特征的参数,但是加入惩罚项使得参数所占比重减少,从而使得代价减少。而参数值越小,将会是一个更简单的假设模型,使得函数越平滑从而减少过拟合现象。所以新的代价函数模型如下所示:

通常不会对第0个参数附加惩罚项,所以求和是从i=1开始(加了也对结果影响不大),后面这一项从λ开始的称为正则化项,λ称为正则化参数。
λ的作用是控制两个不同目标之间的取舍:
第一个目标与目标函数的第一项有关,让我们能够更好的拟合数据。
第二个目标与目标函数的第二项有关,让我们的参数尽量保持一个小数值。
如果λ数值设置的过大,将会使得假设函数的全部项被忽略,从而使得数据欠拟合。

梯度下降求最佳θ
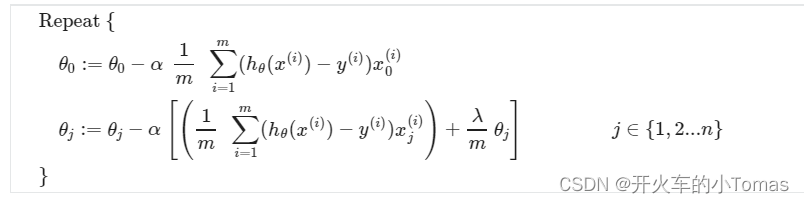

正规方程求最佳θ
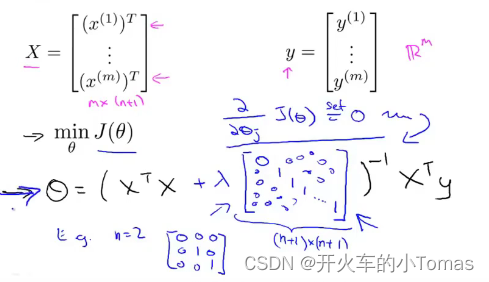
另:只要正则化参数λ>0,括号内的矩阵就可逆。
logistic正规求最佳θ

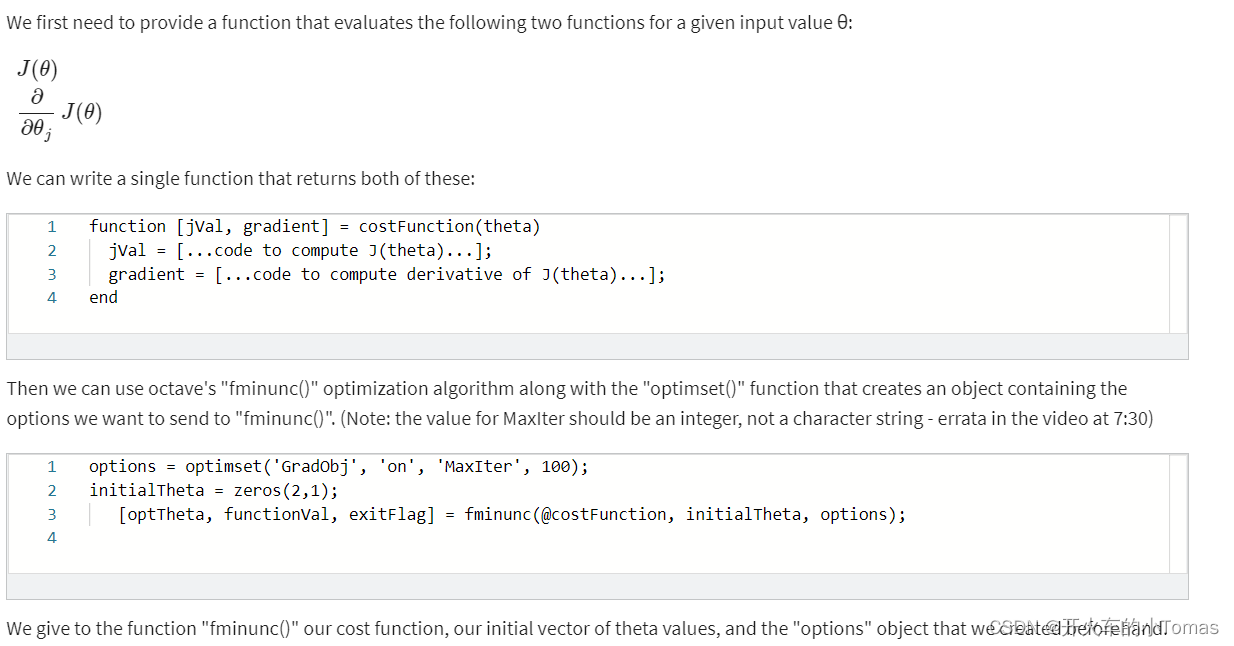
优化算法

jVal将计算J(θ)的值,gradient将计算出各个参数的梯度值。
神经网络
n个特征组合的二次项个数大约是(n^2)/2个。
带有sigmoid或者logistic激活函数的人工神经元,激活函数是指非线性函数g(z),
神经模型的表示形如:[x0x1x2]→[ ]→hθ(x),也可如下图右上角所示。

其中[x1,x2,x3]代表了输入层,也可以补充x0作为偏置单元、偏置神经元(根据实际情况决定)
可以输出函数值的层代表输出层。其余中间的层都为隐藏层。
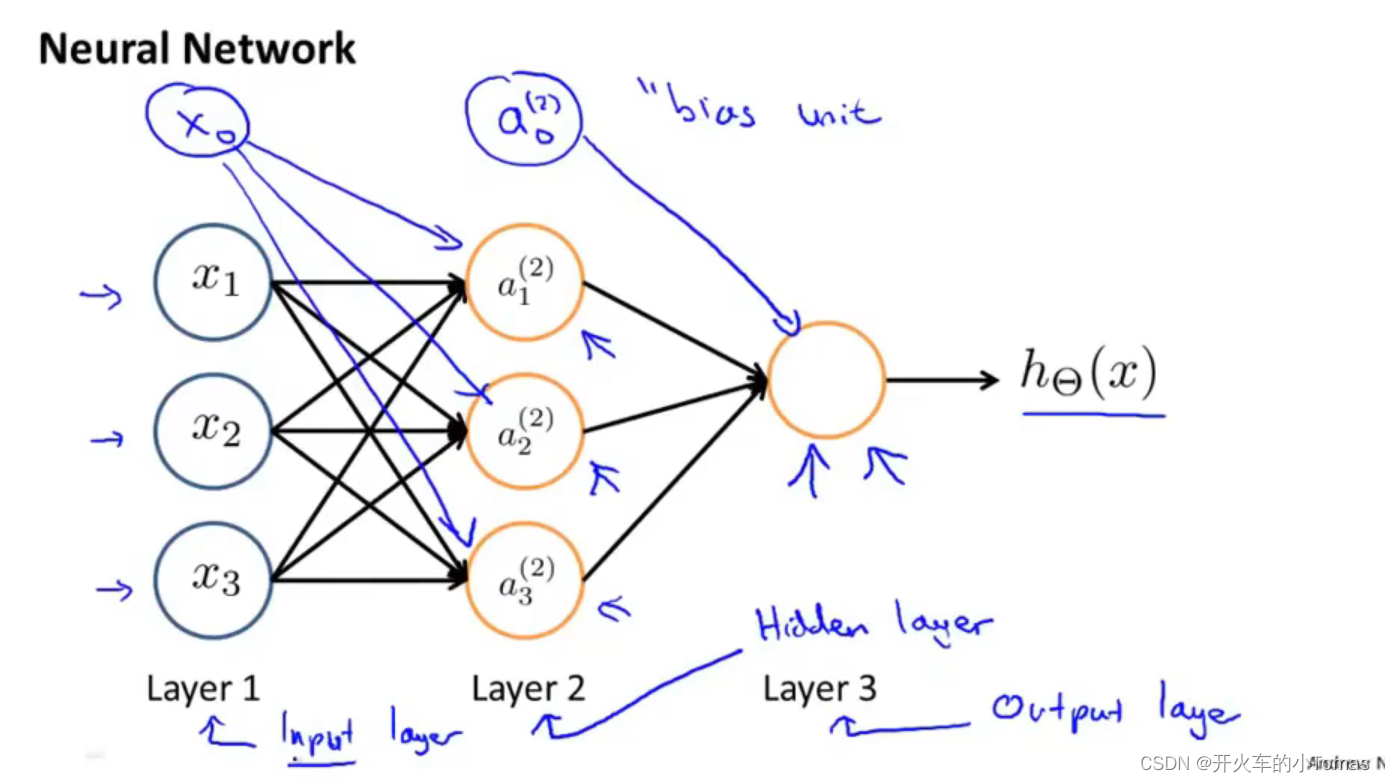
在式子中,a的上标表示第j层,下标表示第i个单元(第j层第i个神经元或单元的激活项(激活项:由一个具体神经元计算并输出的值))。theta表示映射第j层到j+1层的权重矩阵。通常它的维度是(j+1层的单元数) * (j层的单元数 + 1 )
计算h(x)的过程也被称作前向传播
公式向量化
我们可以将g函数中的参数看作z向量,每一个z向量都是theta向量乘以x向量。


神经网络代价函数
一些字母的含义:
1、L 表示神经网络的总层数。
2、S_l 表示第l层的单元数(神经元的数量),不包括第l层的偏置单元。
3、K 表示输出层的单元数目。
当分类结果大于等于3时,其代价函数如下所示
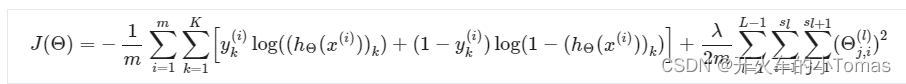
反向传播算法
计算上图取得最小数值的θ
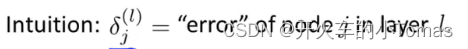
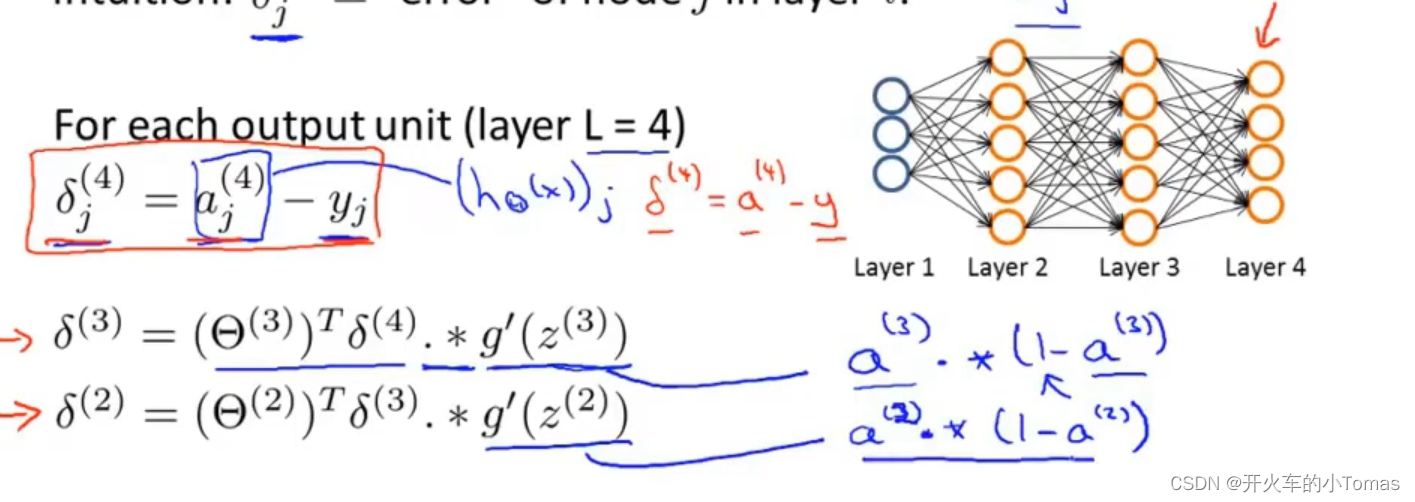
通过如上的符号表示第L层第j个神经元的误差。每一层的误差计算如下图所示。

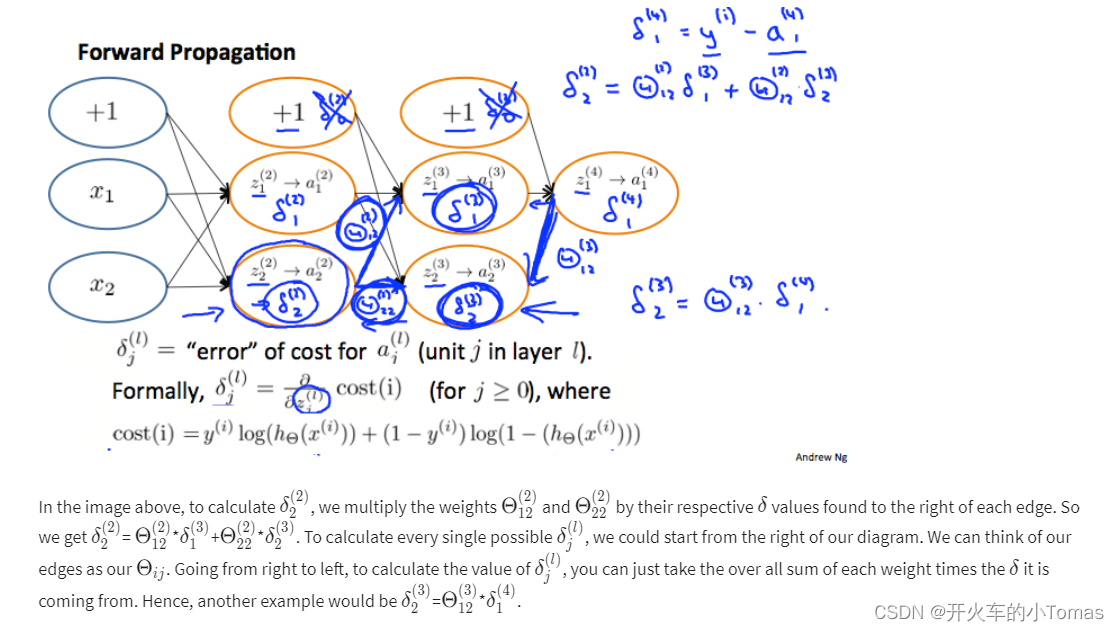
计算算法:
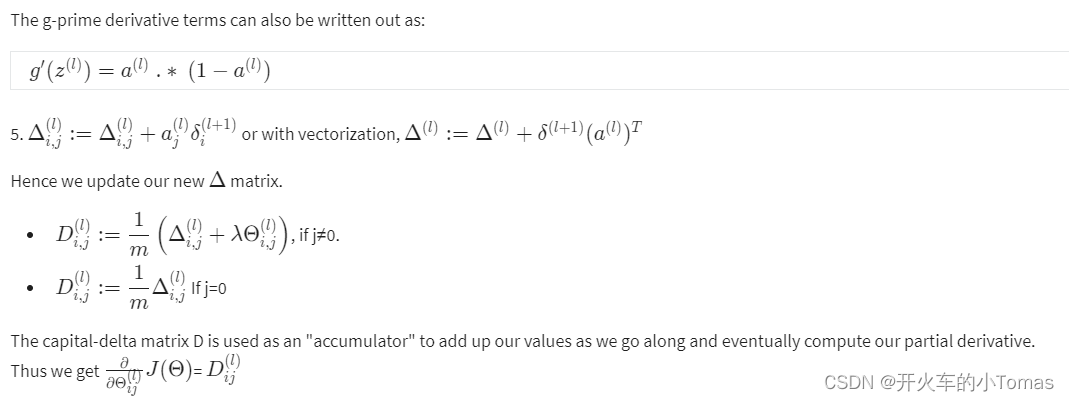

在程序中计算时,需要将矩阵转为向量

最后的结果需要将向量转为矩阵
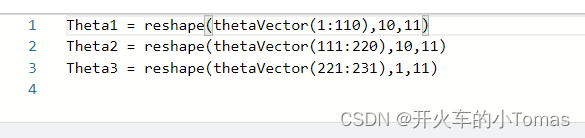
梯度检测
梯度检测可以确保我们的反向传播工作正常。我们使用如下的数值计算来估算梯度值。
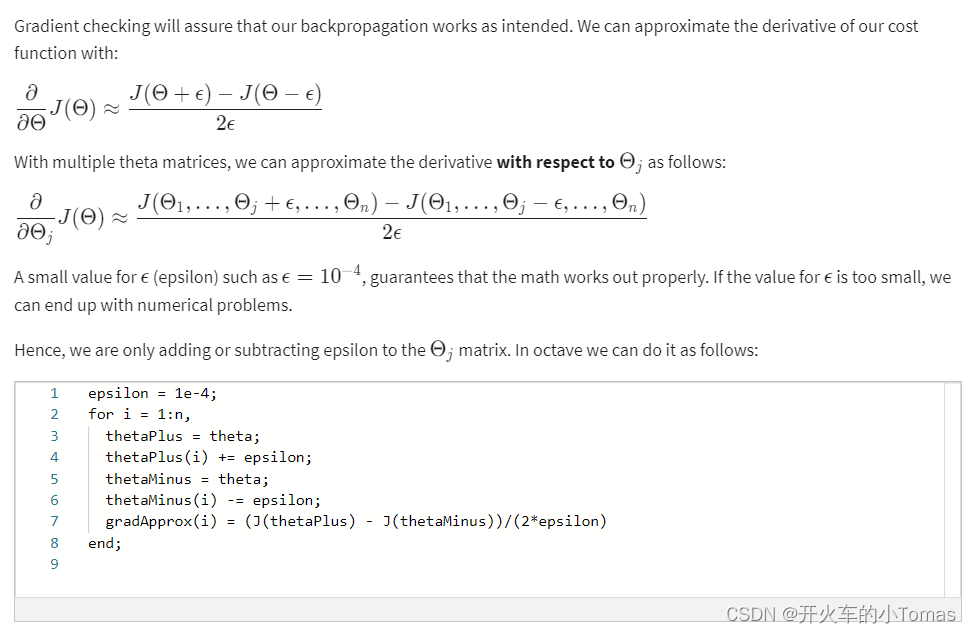
当我们计算出的梯度值与反向传播得到的梯度值近似相等时,即可关闭梯度检测,防止程序运行过慢。
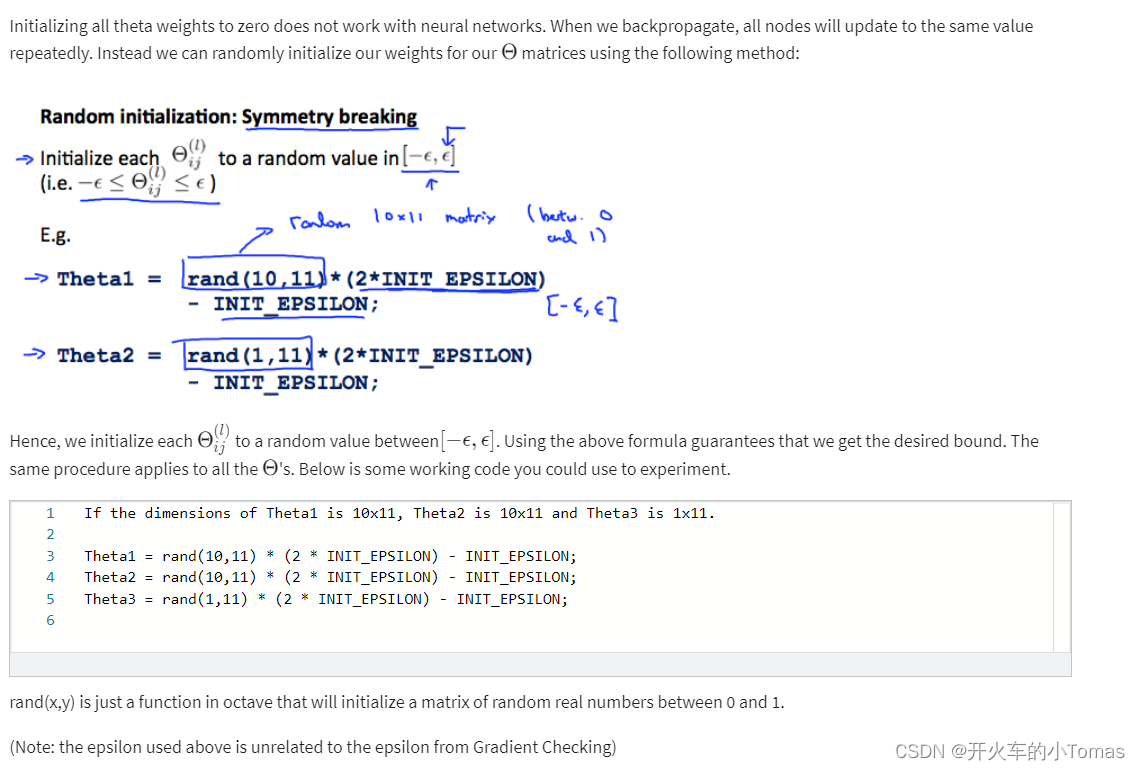
随机化参数
我们需要将theta参数随机化(不能全为相同的权重,这样会使的神经网络的计算没有差异),随机化可如下图所示。

总结
我们需要注意神经网络并不是一个凸函数,所以可能取不到全局最优解,但是局部最优解对问题也是能够解决的。
算法评估和误差分析
下一步我们该做什么
在运行了算法进行预测后,可能会发现与实际有着极大的差别。通常会有如下做法去完善我们的算法:
1、增加训练集数量。————解决高方差————过拟合使用
2、减少特征值。——————解决高方差————过拟合使用
3、获取更多的特征。————解决高偏差————欠拟合使用
4、增加多项式特征。————解决高偏差————欠拟合使用
5、减少正则化参数。————解决高偏差————欠拟合使用
6、增加正则化参数。————解决高方差————过拟合使用
但是以上的方法通常要花费很长的时间去实现和部署,而且我们甚至不知道这样的方法是否对我们的算法有实际的帮助。所以我们需要使用机器学习诊断法,来帮助我们优化算法,这需要时间去理解和实现,但是可以节省时间发现某些方式是无效的。
评估假设
当参数足够少的时候,可以通过画图来评估我们假设函数是否过拟合。
当参数很多的时候,我们可以将我们的数据集按7:3的比例分成训练集和测试集(最好进行随机选取)。
评估假设的步骤:
1、取得训练集最小化代价函数的参数。
2、计算测试集的错误偏差。

在这里是如果你的预测与标签不同,则err=1表示你进行了误判。否则误差值err定义为0,表示预测无误。
如何选择模型
模型选择问题:选择一个对数据集最合适的多项式次数或选择正确的特征来构造学习算法或学习算法中的正则化参数lambda。
当我们用训练集拟合过参数theta时,通过训练误差来选择我们合适的多项式次数,这相当于新增一个特征d(该特征表示我们的多项式次数)。这时我们不能通过测试集来评测我们模型的泛化能力(对于新数据样本的适应能力)。因为这些参数就是拟合的测试集数据,所以在测试集上可能表现的很好,但对于新样本来说就不一定很好了。
所以为了解决选择模型时出现的问题,我们将数据集分成三份,分别为训练集,(交叉)验证集(Cross validation set),测试集。它们的比例为6:2:2。通过验证集来选择模型
偏差与方差
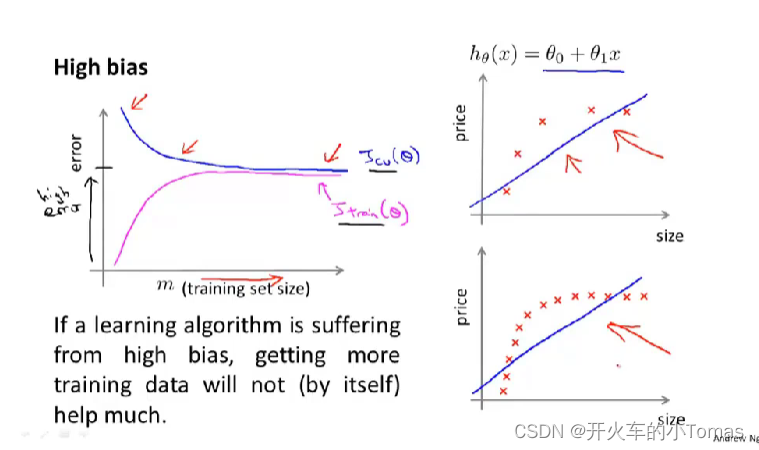
偏差即欠拟合:如果算法有偏差问题,训练集误差和交叉验证集误差都会很大(交叉验证误差可能很接近训练误差)。
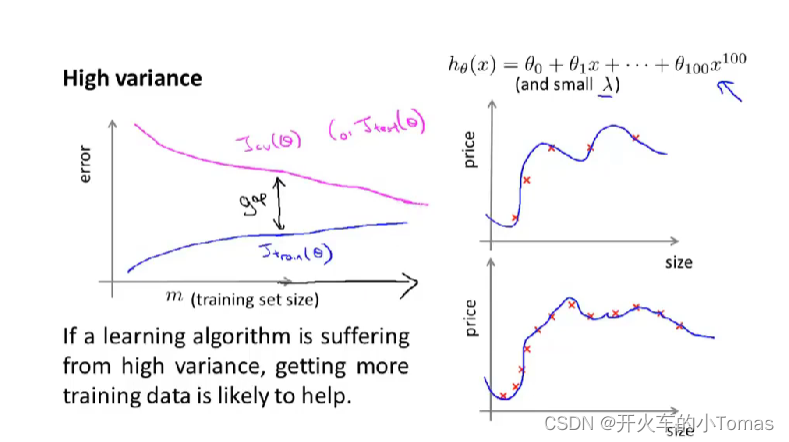
方差即过拟合:如果算法有方差问题,训练集误差将会很小,交叉验证误差远大于训练误差。

如何选择合适的正则化参数:可以从最小值开始,每间隔2倍取值。通过得到的lambda来确定不同参数的值,再使用交叉验证集进行误差分析。
正则化参数的变化对误差的影响如下图:
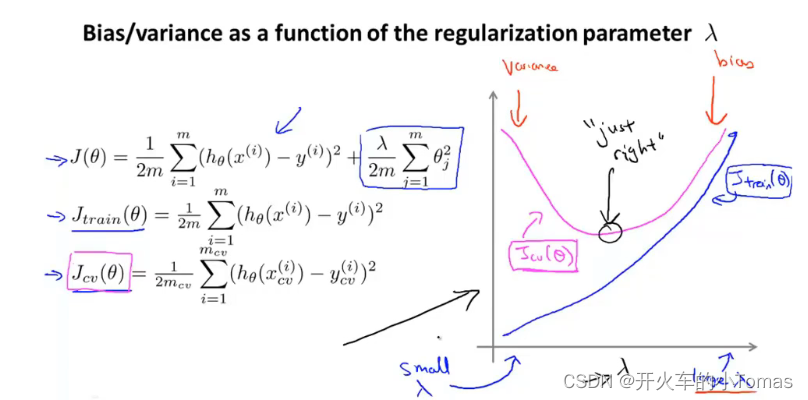
学习曲线
可以用来判断是过拟合还是欠拟合。
欠拟合状态:
过拟合状态:
误差度量值
误差分析和设定误差度量值的重要性:设定某个实数来评估我们的学习算法并衡量它的表现。
如果使用分类精确度作为一个算法的评估的度量,在偏斜类问题(某一类的样本比另一类的样本多得多)中,可能会被算法所欺骗(比如100人里有1个人癌症,癌症率为1%,只要算法预测所有人都没得癌症,在同样本中它给出的癌症率也是1%,这样的算法并没有泛用性)
所以要使用下面的Precision和Recall来评估。
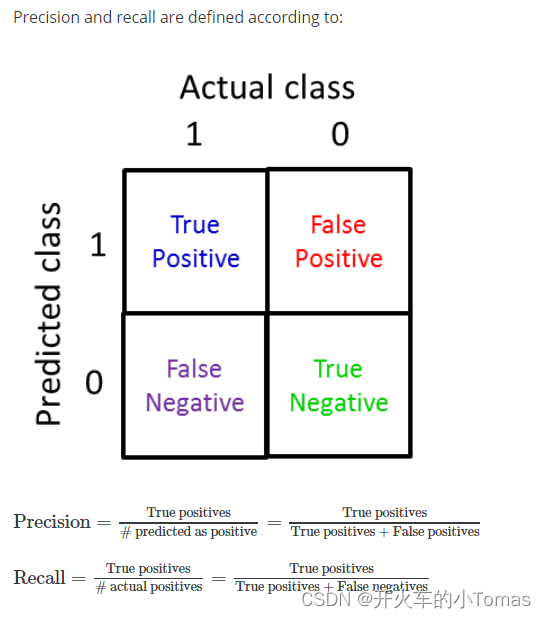
如何去权衡Precision和Recall的值?
可以通过如下的F1公式来获得相关的评定。

支持向量机

支持向量机(大间距分类器)直接给出y的值而不是概率。

核函数的定义

在上图中,随机选择三个标记点l(i),通过标记点来定义相似度函数(核函数,图中为高斯核函数f(i))。
所以我们能够构建预测函数y。
而标记点我们可以直接选取样本点。

选择优化目标中的C参数,C参数可近似看作之前λ参数的倒数。当C很大时,高方差,过拟合,相当于没有正则化。当C很小时,高偏差,欠拟合。

使用SVM前需要准备参数C和核函数。
一个线性核函数也叫无核函数(可以用在特征很多,数据很少的时候)
还有高斯核函数,它需要准备另一个参数(可以用在特征很少,数据很多的时候)

如何选择算法模型

无监督学习
聚类算法
K-Means算法
如果要对一个数据集分成俩个簇,K-Means算法的步骤如下。
首先随机生成俩个点,这俩个点叫做聚类中心。然后进行迭代
1、簇分配:遍历每个样本,将每个样本分配给距离聚类中心最近的中心点。
2、移动聚类中心:将聚类中心移动到该聚类中所有数据的均值处。
如何初始化聚类中心?
首先K的数量小于样本数量,随机的选择K个训练样本,让聚类中心等于这几个样本。样本没有选好可能会使得算法计算出局部最优结果。解决方法是多次运行K-Means算法(一般是50-1000次之间,也只能在K值<10的情况下会得到较大改善,K值较大的话只可以给一个合理的起始点去找到一个好的聚类结果),从中选取代价最小的一个。
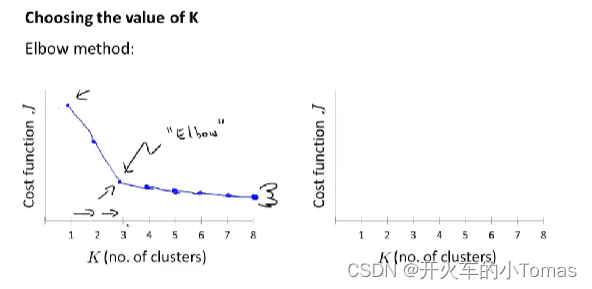
如何选择聚类的数量K?
有一个elbow法则,随着聚类数量的增加,一开始代价函数会下降的很快,到某一个数量后,代价函数下降变换,通常会选择那一个拐点。

优化目标:
大多数情况下可能没有足够明显的拐点。可以根据我们的使用目的进行决定。

降维
目的
数据压缩,节约数据存储空间。
可视化。
PCA(主成分分析)算法

当特征差距过大时,要进行特征缩放,均值标准化。
均值标准化,先计算每个特征值的均值,

如何计算参数k:

异常检测
高斯分布参数的计算

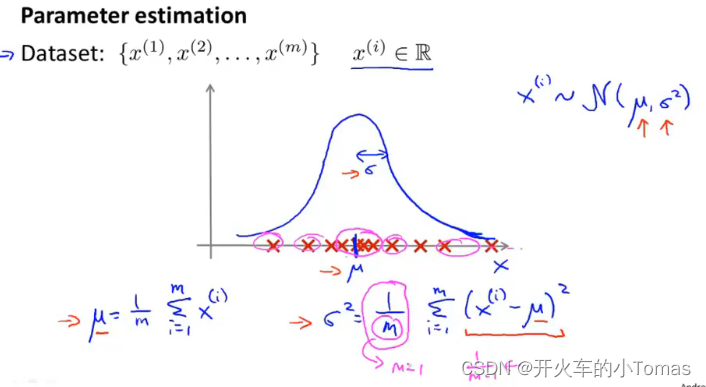
处理异常的算法
用数据集建立概率模型P(x),看特征出现的频率。

开发和评估异常算法


如何区别异常检测和监督学习?
对于异常检测来说,它的异常样本的数量通常是非常小的,异常样本的种类是多种多样的(所以很难让机器学习去了解异常的种类)。并且它拥有很大数量的正常样本。
对于监督学习来说,它会有很大数量的正样本(通常是不希望出现的东西,如恶性肿瘤)和负样本,这样它会有足够的样本去学习正样本通常长成什么样。
协同过滤算法
执行算法的时候要观察用户的实际行为,来协同地得到每个人对电影地评分值,通过评分又能帮助系统更好地学习特征,更好地特征能够更好的预测用户的评分。

重复的计算参数和x没有效率,将两者结合可以提升效率,并且与此前不同的是,将删除掉x0,θ_0这一个数字,原因是算法可以自动地去选择参数,如果需要一个为1的特征,它可以自己灵活地设置。
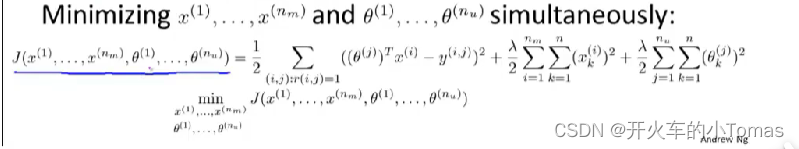

处理大数据集
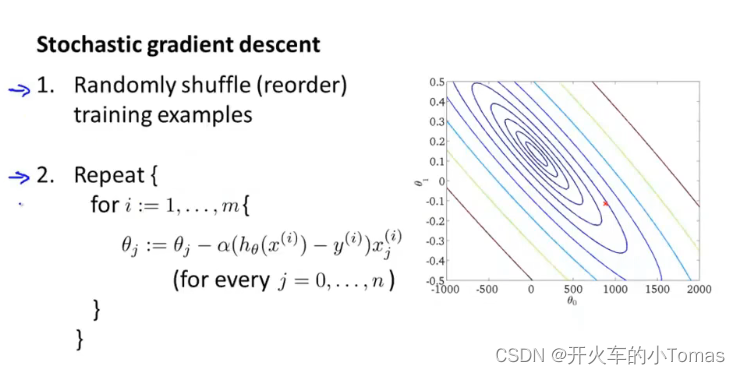
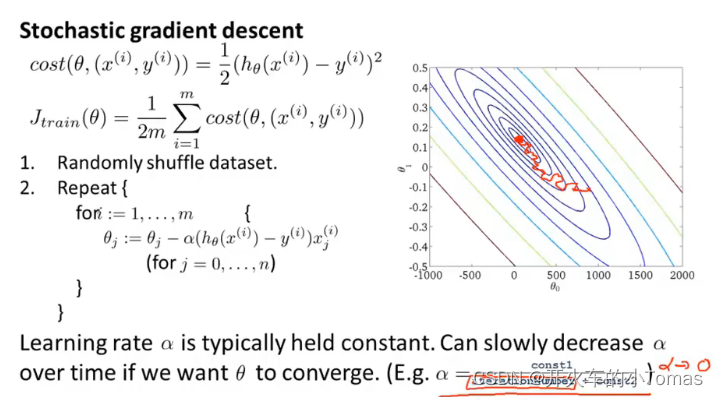
随机梯度下降
当数据集很大的时候,前面所介绍的梯度下降方法计算量将会很大。
所以使用随机梯度下降的方法,逐渐接近全局最优解
Mini-Batch梯度下降
多出了一个参数b,表示每次迭代需要使用的样本,可以取值2~100之间。


缺点是需要时间确定参数b的值,一旦确定了并且有一个很好的向量化方法,则速度要比随机梯度下降要快。
检查随机梯度下降是否正确

有几种情形的图如下
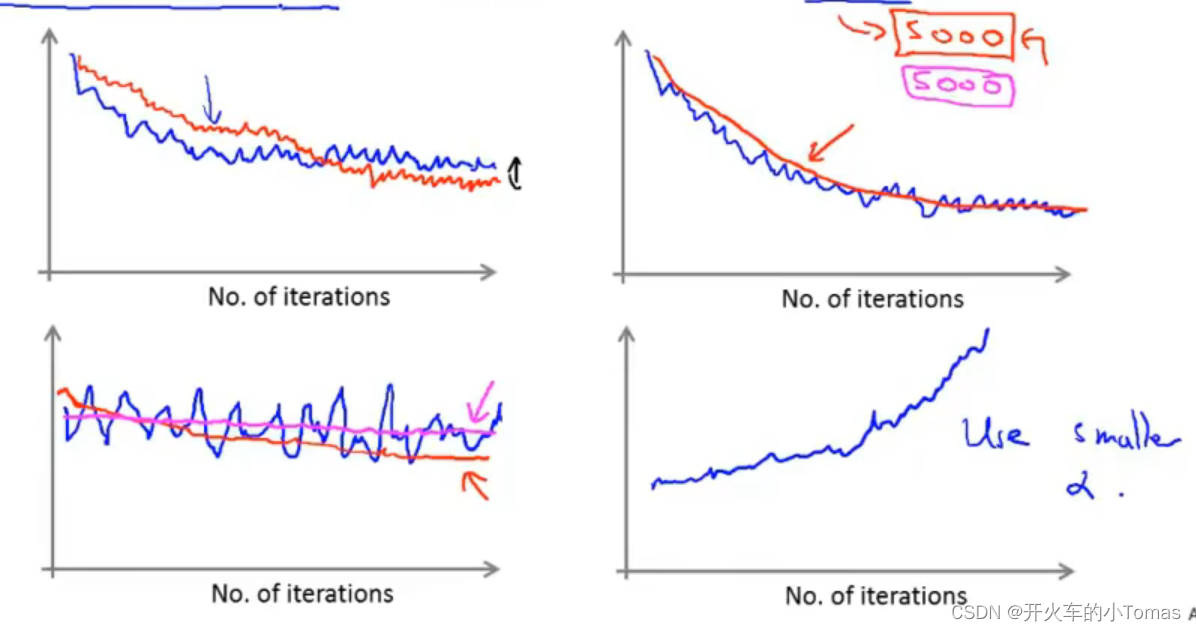
1、如果曲线噪声太大,上下幅度大,可以增加求均值的样本的数量
2、如果cost函数再上升,则使用更小的学习速率。
如果不断减小学习率到0,最后会得到一个非常好的假设。但需要计算额外的俩个参数。
减少映射与数据并行
MapReduce的思想
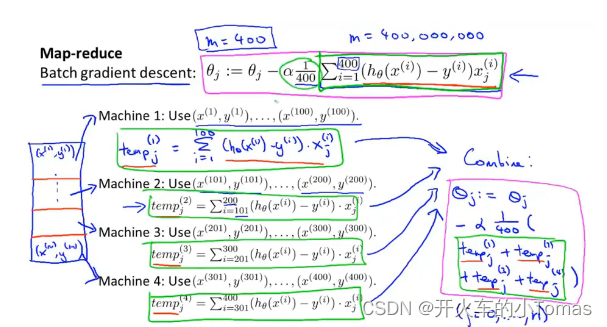
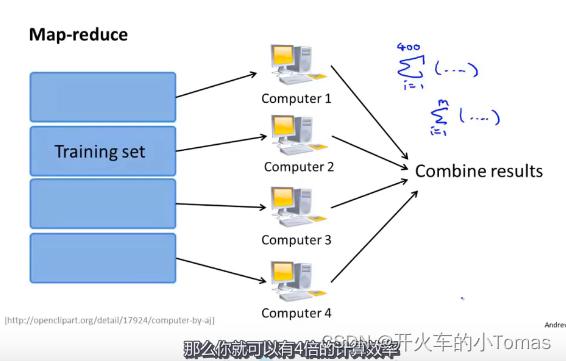
如图所示,我们可以将400的样本分别给四台机器计算100的样本,然后四台机器将结果汇总给中心服务器















 3635
3635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









