






paper: https://arxiv.org/pdf/2002.07953.pdf
code: https://github.com/VisionLearningGroup/DANCE
参考请引用:
Saito, K., Kim, D., Sclaroff, S., & Saenko, K. (2020). Universal Domain Adaptation through Self Supervision. ArXiv, abs/2002.07953.
Motivation:
当前大部分的域适应工作都是针对目标域中的样本类别都和源域样本类别相同。一般的方法都适直接对齐源域和目标域两个域的特征属性。但是这样有两个弊端:
目标域类比的四种情况:
closed-set (
L
s
=
L
t
L_s = L_t
Ls=Lt), open-set (
L
s
∈
L
t
L_s ∈L_t
Ls∈Lt) , partial (
L
t
∈
L
s
L_t ∈ L_s
Lt∈Ls) , or a mix of open and partial
- 在不知道目标域的样本类别是哪一种情况时,直接对齐两个域的属性很容易出现灾难性的错误对齐 (catastrophic misalignment),例如:当用closed-set方法对齐open目标集的时候,就会把unknown的类别也对齐到known里
- 无法获得unknown类别的鉴别性的特征表示,因为源域根本没有这个类别
Contribution:
- neighborhood clustering loss(相邻聚类损失)
- entropy separation loss(熵分离损失)
- 设计了DANCE模型可以被应用在任何一种域适应情况而不需提前知道目标集情况
- 成功的在没有任何监督的情况下学习到了目标域unknow类别样本的具有强鉴别语义的特征
Method:
baseline: resnet50
network大致框架(原文没给,主要针对提取的特征进行操作,但是引用了一篇文章的框架,如下)

Semi-supervised Domain Adaptation via Minimax Entropy
http://cs-people. bu.edu/keisaito/research/MME.html
ps:在最后一个分类器前面一层的特征F后另加了一个L2batchnorm正则化操作,W为分类器的权重向量[ w 1 ; w 2 ; : : : ; w K w_1;w2_; : : : ;w_K w1;w2;:::;wK],代表了源域每一类的归一化特征,在本文中可以叫做类中心(prototype)
Neighborhood Clustering (NC)

目的:最小化目标域样本对于相邻样本(unknown)或者源域类中心(known)的交叉熵损失, 目标域样本初步分类
f: 特征提取器G提取出的特征;
V
∈
R
N
t
∗
d
V∈R^{N_t * d}
V∈RNt∗d为memory bank存储所有目标域样本的特征
F
∈
R
(
N
t
+
K
)
∗
d
F∈R^{(N_t+K)*d}
F∈R(Nt+K)∗d为memory bank存储所有目标域样本和源域类中心的特征; d为最后一个全连接层的输出维度
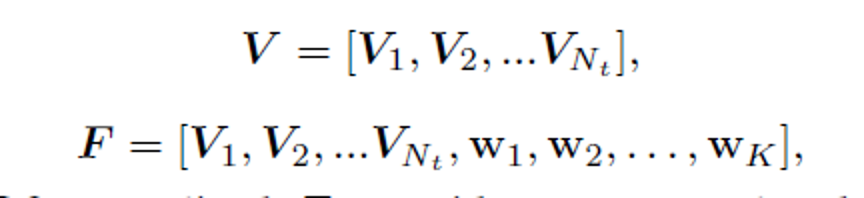
则目标域样本是其他样本的邻居(该样本被划分为unknown)或源域类中心(known)的邻居的概率为:

其中τ可以控制邻居的数量,所以这个近邻交叉熵损失可以计算为:

最小化损失就代表让目标域样本接近它的目标域近邻或者源域类中心
Entropy Separation loss (ES):
目的:让目标域中unknown样本进一步远离源域样本(known)
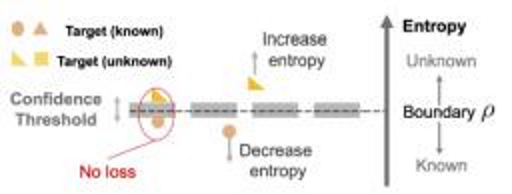
出发点:目标域中unknown样本更倾向于有一个更大的熵值相比于known样本,因为他和源域并没有一个共同的特征,来自于文献
【Kaichao You, Mingsheng Long, Zhangjie Cao, Jianmin Wang, and Michael I. Jordan. Universal domain adaptation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019】
方法:
p是目标域经过分类器后的输出,这样目标样本的熵值可以表示为
H
(
p
)
H(p)
H(p),我们定义一个边界阈值ρ,然后最大化
∣
H
(
p
)
−
ρ
∣
|H(p) - ρ|
∣H(p)−ρ∣,这样就可以让输出的熵值都远离ρ,而我们只需要让这个边界阈值为known样本和unknown样本的界限,即可让这两类样本互相远离。在这里,定义ρ为
log
(
K
)
2
\frac{\log(K)}{2}
2log(K),K为源域类别(known)的数量。ρ取值的根据作者简单说是因为
log
(
K
)
\log(K)
log(K)是
H
(
p
)
H(p)
H(p)的最大值。
但是,对于known和Unknown之间的边界阈值附近有很多争议的样本,并且由于源域变换为了目标域,真是的边界阈值也有可能会改变,所以作者针对这个最大化方法做了一个约束
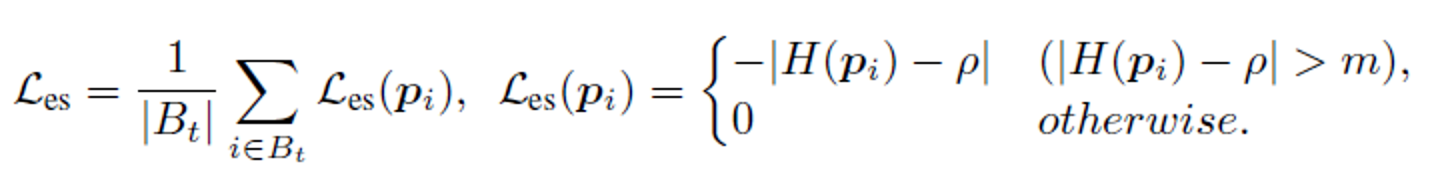
当设置了一个参数m后,我们就可以只处理相比于边界阈值置信度较高的样本(较远于边界阈值,也说明具有更有鉴别力的特征的样本),这样模型就能学到更有效的特征表示。
总loss:
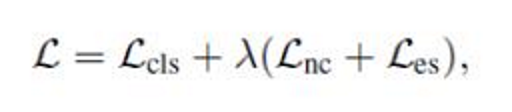
Experiment
Datasets:
Office: three domains – (Amazon (A), DSLR (D), Webcam (W)) and 31 classes
OfficeHome(OH): four domains and 65 classes.
VisDA (VD): 12 classes from two domains: synthetic and real images
Evaluation:
CDA and PDA: calculate the accuracy over all target samples
In ODA and OPDA: average the accuracy over classes including “unknown”.
Hyper-parameters:
λ = 0.05
m = 0.5
Comparisons:
- the universal comparison to the 5 baselines including state-of-the-art methods on CDA, PDA, ODA, and OPDA. 所有的方法使用固定的超参数,但是注意在测试的时候,每个任务上测试机都包括unknown类别,对于CDA和PDA,则直接用交叉熵损失针对于unknown类别。
- comparison with methods tailored for each setting.

此处还有和每一个类别中特意设置参数的4个表格对比结果没贴上,页数限制可以看原论文
Ablation by clustering “unknown” examples
为了评估该模型学习到的特征具有很好的质量,作者在训练结束后固定特征提取器G的参数,然后在后面加一个线性全连接层用作分类器,训练分类器参数,测试原有模型特征在unknow样本中恢复原有的类的能力。作者选择在ODA领域做实验,数据集为OfficeHome(15 “known” and 50 “unknown” classes).结果如下:

可以看到,相对于baseline方法ImgNet大大提升了性能,并且可以看到只有NC方法该模型已经实现了较好的能力,加入了ES后模型性能得到了进一步的提升。
The number of “unknown” classes
测试了unknown类别数量对于模型的影响,选取测试领域:ODA,定义了开放性指标Openness =
1
−
∣
L
s
∩
L
t
∣
∣
L
t
−
L
s
∣
1-\frac{|L_s∩L_t|}{|L_t-L_s|}
1−∣Lt−Ls∣∣Ls∩Lt∣
经测试,可以看到当Unknown类别逐渐增多时,所有模型性能都下降,但是DANCE依旧保持最好的性能。
conclusion
- we introduce Domain Adaptative Neighborhood Clustering via Entropy optimization (DANCE) which performs well on universal domain adaptation.
- We propose two novel selfsupervision based components: neighborhood clustering and entropy separation which can handle arbitrary category shift
- DANCE is the only model which outperforms the source-only model in all settings and the state-of-the-art baselines in many settings
- In addition, we show that DANCE extracts discriminative feature representations for “unknown” class examples without any supervision on the target domain.















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









