






UNSUPERVISED REPRESENTATION LEARNING BY PREDICTING RANDOM DISTANCES
文章:https://arxiv.org/pdf/1912.12186.pdf
代码:https://git.io/RDP
参考请引用:
Wang, H., Pang, G., Shen, C., & Ma, C. (2019). Unsupervised Representation Learning by Predicting Random Distances. ArXiv, abs/1912.12186.
Motivation:
- 许多无监督方法都在探索利用数据中容易获得信息,比如时间和空间邻近信息,然后利用这些信息设计一个监督信号去监督特征学习过程,这类的方法已经在文本\图像\视频类数据中取得了很好的效果,但是在tabular data(表格数据) 中并不适用,因为这类数据并没不包含所谓的时间和空间信息。
- 许多传统处理表格数据的方法计算量消耗比较大,很难去处理大规模或者高维数据
Contribution:
-
设计了一个预测随机距离模型Random Distance Prediction (RDP) model ,这个模型是训练一个神经网络去拟合在随机映射空间中每两个点之间的距离,这样做虽然简单但很有效,并且经过试验发现,神经网络拟合后的距离表示比原随机映射空间中的距离表示更具有代表性,即进一步优化了距离。
-
这个模型具有很高的灵活性,可以在此模型上加一些辅助性损失来处理具体的下游任务,如:聚类任务(通过加入重建损失)和异常点检测任务(通过加入novelty loss)
对文中思想的补充解释:
① 当随机映射空间中的距离包含有数据内部固有的结构信息时,训练一个神经网络拟合这个信息就是让神经网络去学习这个数据的结构信息。
②因为欧氏距离在高维空间中会失效,每两个点中的距离近乎为0,所以作者不去拟合原有空间的点对距离,而是先将数据到低维随机映射空间,然后在让神经网路去拟合这个距离。
Method

-
模型介绍:
∅:RD→RM: 要学习的神经网络,将数据从D维映射到M维空间
η:RD→RK: 现有的随机映射函数,将数据从D维映射到K维空间
l: 表示两个输入的差异函数
<,>: 距离函数,在本文中使用内积作为距离函数,由于处理的数据都是实数,所以内积变为点积所以上述模型的损失变为:
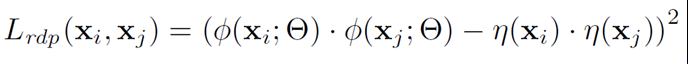
这是文章最核心的损失,也是本模型的唯一损失。
这片论文思想能成立的核心前提是随机映射空间中数据的距离包含有数据的类结构,所以作者接下来介绍了随机映射函数的方法 -
随机映射函数:
①线性方法:
X⊂ RN×D : 表示N个数据点,在D维空间中
随机映射矩阵 A⊂RK×D
映射方法:X′=AXT ,将原D维数据映射到K维空间中
作者调查文献,发现当ϵ ∈(0,0.5),并且 K = 20 log ( n ) ϵ 2 K=\frac{20\log(n)}{ϵ^2} K=ϵ220log(n)时,线性映射满足以下公式:
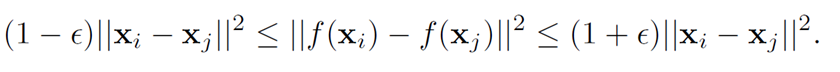
并且当映射矩阵A的元素符合高斯分布时,有:
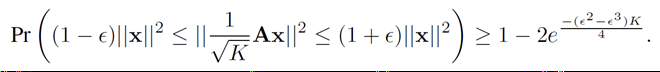
带入第一个上述公式可得:
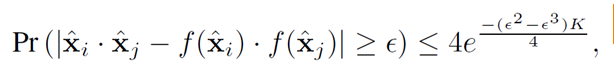
上式右端当K较大时是一个极小值,代表当满足以上条件时,线性随机映射将原数据点映射到随机空间后,数据点之间的距离近乎不变,即原数据点中的结构信息原封不动的转移到了随机映射空间中,就满足了论文思想成立的前提条件。
②非线性方法
常用的非线性映射方法是核函数方法,如多项式或者径向基函数,表达式为
k ( x i , x j ) = < φ ( x i ) , φ ( x j ) > k(x_i, x_j )=<φ(x_i ),φ(x_j )> k(xi,xj)=<φ(xi),φ(xj)>
根据(Rahimi & Recht, 2008), 一定存在一个函数g:RD→RK 将原数据点映射到随机空间后,这两个点的内积值约等于核函数值,即:
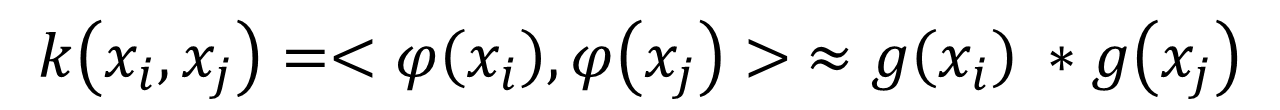
如果用映射矩阵A来表示的话,就是首先通过傅里叶变换和移不变变换后,在用Ax来得到一个映射输出
以上两个方法是为了证明随机映射方法保证了数据的结构信息不变,为论文思想提供了理论证明。 -
学习类结构信息
在映射空间每两个点距离包含类结构信息后,损失函数可以写成:
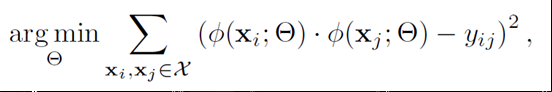
其中 y i j = η ( x i ) ∗ η ( x j ) y_{ij}= η(x_i )∗η(x_j ) yij=η(xi)∗η(xj)
Y η ∈ R N × N Y_η∈R^{N×N} Yη∈RN×N 是包含N个点的距离矩阵,包含有丰富的局部距离信息,即类结构信息
由于在随机映射时,存在着一些数据假设,如K值要大,A的元素要符合高斯分布,当数据假设不准确时,随机映射空间中每两个点之间的距离就不能完全准确的代表距离信息,存在着一些异常点,但是作者经过实验发现,在通过神经网络学习拟合这个距离时,会逐渐优化这个距离,即神经网络不仅会学习到随机映射空间中包含的类结构信息,还会改善这个信息。 -
融合一些辅助损失
作者提出的模型可以根据具体任务融合一些辅助损失,来提升特征的质量
在聚类任务中,可以加入重建损失:
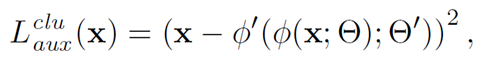
在异常点检测任务中,可以加入novelty loss:
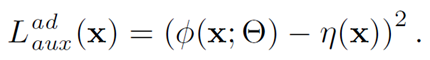
聚类试验:
数据集:R8, 20news, Sector and RCV1常用于文本分类; Olivetti常用于人脸识别

实验方法:用学习好的特征进行K-means聚类
评测指标:Normalized Mutual Info (NMI) score and F-score
对比方法:HLLE (Donoho & Grimes, 2003) in manifold learning, Sparse Random Projection (SRP) (Li et al., 2006) in random projection, autoencoder (AE) (Hinton& Salakhutdinov, 2006) in data reconstruction-based neural network methods and Coherence Pursuit (COP) (Rahmani & Atia, 2017) in robust PCA.
Baseline :在原有D维数据空间直接聚类的性能作为baseline,写作Org
由于此类方法针对表格数据,所以在处理文本和图像数据时先把数据类型转换为表格数据,图像:把每一个像素值作为一个特征值; 文本:用bag-of-words representation
根据作者代码打印网络模型:

RTargetNet: 随机映射方法,将原有数据映射到1024维空间,并保持参数固定
RNet: 要学习的神经网络模型,将原有数据映射到1024维空间。layers层参数输出距离去拟合RTarget模型输出距离,recon_layer层输出用于构建重建损失
实验结果:

消融试验:

探索输出维度对性能的影响:

针对图像数据单独做了一个实验:
数据集:Olivetti
对比方法:RotNet (Gidaris et al., 2018).

针对分类任务做了一个实验
分类器:前项3层神经网络
评测指标:F-score

结论:
- 提出一个无监督表征学习方法,通过预测随机距离,很简单但很实用
- 这个预测随机距离,不仅学到了数据类结构信息,而且纠正了一些不准确的距离信息
- 模型很灵活,可以加入到一些具体任务中















 7144
7144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









