







实现完上面的之后,我把一个视频,大约2h,利用格式工厂导出音频,将其进行语音识别,报错,告知需要转化为wav才能操作,这里我直接使用格式工厂对音频进行格式转化,先完成核心代码的编写。
转化完wav格式后,报错
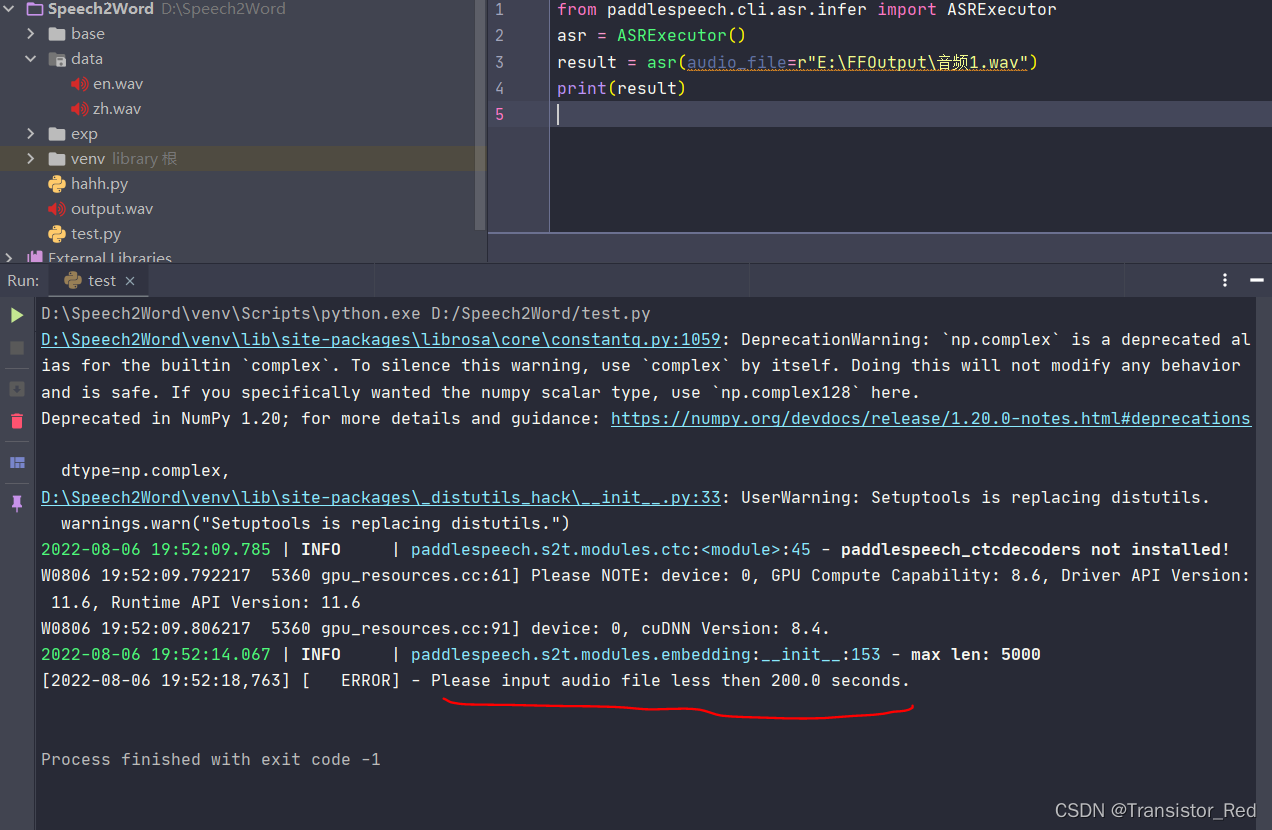 错误很容易解决:将音频分片就行了,这里参考博客
错误很容易解决:将音频分片就行了,这里参考博客
代码参考
from paddlespeech.cli.asr.infer import ASRExecutor
import csv
# import moviepy.editor as mp
import auditok
import os
import paddle
from paddlespeech.cli.text.infer import TextExecutor
import soundfile
import librosa
import warnings
warnings.filterwarnings('ignore')
'''
音频切分
'''
# 输入类别为audio
def qiefen(path, ty='audio', mmin_dur=1, mmax_dur=100000, mmax_silence=1, menergy_threshold=55):
audio_file = path
audio, audio_sample_rate = soundfile.read(
audio_file, dtype="int16", always_2d=True)
audio_regions = auditok.split(
audio_file,
min_dur=mmin_dur, # minimum duration of a valid audio event in seconds
max_dur=mmax_dur, # maximum duration of an event
# maximum duration of tolerated continuous silence within an event
max_silence=mmax_silence,
energy_threshold=menergy_threshold # threshold of detection
)
for i, r in enumerate(audio_regions):
# Regions returned by `split` have 'start' and 'end' metadata fields
print(
"Region {i}: {r.meta.start:.3f}s -- {r.meta.end:.3f}s".format(i=i, r=r))
epath = ''
file_pre = str(epath.join(audio_file.split('.')[0].split('/')[-1]))
mk = 'change'
if (os.path.exists(mk) == False):
os.mkdir(mk)
if (os.path.exists(mk + '/' + ty) == False):
os.mkdir(mk + '/' + ty)
if (os.path.exists(mk + '/' + ty + '/' + file_pre) == False):
os.mkdir(mk + '/' + ty + '/' + file_pre)
num = i
# 为了取前三位数字排序
s = '000000' + str(num)
file_save = mk + '/' + ty + '/' + file_pre + '/' + \
s[-3:] +  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3147
3147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









