




摘要
近期的零样本学习(ZSL)方法已经整合了细粒度分析,即细粒度ZSL,以减轻众所周知的已见/未见域偏差和视觉-语义映射问题的错位,并取得了深远的进展。值得注意的是,这种范式与现有的封闭集细粒度方法不同,因此可能带来独特且非平凡的挑战。然而,据我们所知,对于这个主题仍然缺乏系统的总结。为了丰富这个领域的文献,并为其未来的发展提供坚实的基础,本文提出了对ZSL中细粒度分析最新进展的广泛回顾。具体而言,我们首先提供了现有方法和技术的分类,对每个类别进行了彻底的分析。然后,我们总结了涵盖公开可用数据集、模型、实现以及一些更多细节的基准,作为一个库。最后,我们勾勒了一些相关的应用。此外,我们讨论了重要的挑战,并提出了潜在的未来方向。
介绍
传统的识别任务大多在封闭集场景下进行,即测试类别是训练类别的子集,或者最多与训练类别相同。然而,在现实世界的应用中,新颖的类别可能会轻易出现。为了将识别扩展到未见类别,零样本学习(ZSL)已经出现并在机器学习和计算机视觉社区引起了广泛关注。在实践中,ZSL 可以通过使用一组语义描述符来形成视觉到语义映射问题,这些描述符被已见和未见类别共享。这些语义是高级别的、每个类别的,并且比标记的真实数据样本更易于获得,例如作为知识转移桥梁的单词或句子描述。由于没有观察到任何未见类别样本,训练的模型本质上对已见类别具有偏见,即领域偏差。此外,视觉特征和语义也是相互独立的,因此进一步挑战了它们的对齐。通过对文献的研究,大多数 ZSL 方法通过以粗粒度的方式提取每个样本的全局特征来解决视觉到语义问题。然而,这不可避免地会降低整体识别率,特别是对于那些在类别之间具有小间隔和大内部变化的样本,例如各种“哈士奇亚种”之间的视觉差异可能远大于“哈士奇”和“狼”之间的差异。为了更好地缓解这些问题,近年来的 ZSL 研究越来越关注细粒度方面,并在理论、算法和应用方面取得了巨大进展。
观察表明,细粒度 ZSL(FZSL)更有利于在已见/未见类别之间转移知识,其要点在于捕捉微妙的视觉差异,这些差异不仅在类别之间具有区分性,而且与它们的多样化和复杂的语义非常吻合。尽管细粒度 ZSL 最近取得了进展,但对其进展、挑战和前景的全面概述尚不可用。为了填补这一空白,本文旨在系统地回顾细粒度 ZSL 的当前发展情况,涵盖了在 ZSL 细粒度扩展中使用的各种方法和技术,并进一步为其未来发展提供基础。总之,我们的贡献有四个方面,即,
• 我们提出了细粒度 ZSL 的全面分类,并对其背后的方法和技术进行了彻底分析(第3节),这有助于研究人员更好地探索他们的兴趣领域。
• 我们提供了一个库,以便概述常用的数据集、具体的实验设置和其他细节(第4节)。
• 我们勾勒了各个领域中最具代表性的细粒度 ZSL 应用系列(第5节),这引发了跨学科研究和视野。
• 我们讨论了该领域面临的重要挑战,并分享了对未来研究方向的见解(第6节),这总结了关于细粒度 ZSL 的第一次调查。
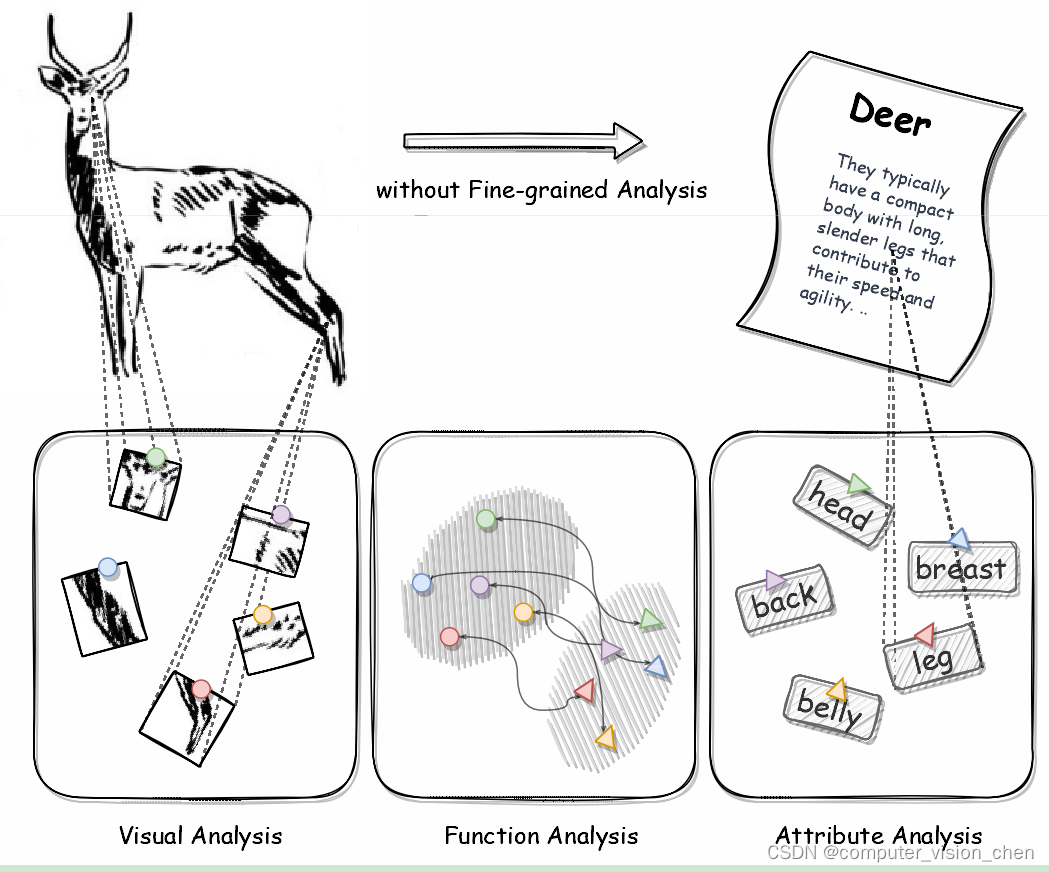
图1:与传统的ZSL相比,FZSL通常研究类关系,FZSL包含更精细、更细腻的概念,通常体现在三个分析领域,包括视觉、属性和映射函数。
问题定义

鉴于已见域 ( D_s = { (x_s, y_s, a_s) \ | \ x_s \in X_s, y_s \in Y_s, a_s \in A_s } ),其中 ( X_s, Y_s ) 和 ( A_s ) 分别表示视觉样本、类别标签和语义(例如一组属性),同样地,令未见域 ( D_u = { (x_u, y_u, a_u) \ | \ x_u \in X_u, y_u \in Y_u, a_u \in A_u } )。在不失一般性的情况下,零样本学习的任务可以建模为学习一个映射/关系函数 ( \Psi: X_s \rightarrow A_s ),其中 ( X_u ) 严格来说是训练不可访问的。在推断过程中,学得的函数 ( \Psi ) 仅应用于识别未见域的样本,即零样本学习,或者来自已见和未见域的联合,即泛化零样本学习(GZSL)。值得注意的是,零样本学习的成功依赖于 ( A_s ) 和 ( A_u ) 之间的共享属性,它们作为从已见到未见域的桥梁。以类别为基础的关系建模已经取得了有希望的结果,作为接近零样本学习问题的最常见做法,其识别目标为:
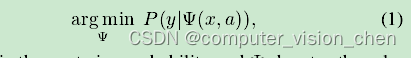
bibtex格式论文
@misc{guo2024finegrained,
title={Fine-Grained Zero-Shot Learning: Advances, Challenges, and Prospects},
author={Jingcai Guo and Zhijie Rao and Zhi Chen and Jingren Zhou and Dacheng Tao},
year={2024},
eprint={2401.17766},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











