







文章目录
发布本文的时间为2025.4.4
🌕yolov5-segment的灵感来源于YOLACT
网上有很多关于YOLOv5检测模型的输出和后处理的教程(也有YOLOv5问题区的讨论)。我一直在寻找类似的关于分割模型的资料,但似乎网上的信息很少,或者至少我没有找到太多。直到昨天,我才明白YOLOv5的分割模型灵感来源于YOLACT。
在此,我提供一些信息,帮助大家了解YOLOv5是如何处理其分割输出的。
在深入了解YOLOv5的分割模型之前,我们先通过其论文中的简单示意图来看看YOLACT是如何工作的。
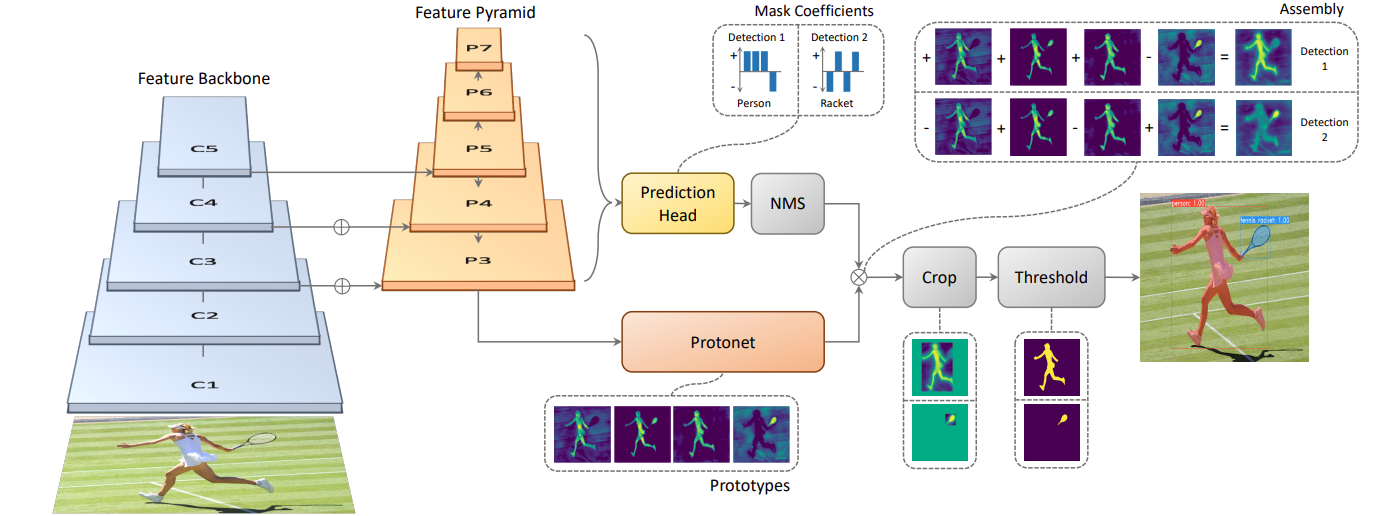
🌕什么是YOLACT?
YOLACT(You Only Look At Coefficients)是一种实时实例分割模型,其核心思想是将实例分割任务拆解为两个并行的子任务:
-
原型生成(Prototype Generation):
- 功能: 生成一组原型掩膜,这些掩膜代表了不同的对象形状特征。
- 实现: 使用全连接卷积神经网络(Fully Connected Convolutional Network,FCN)生成这些原型掩膜。网络的最后一层包含k个通道,每个通道对应一个原型掩膜,因此生成的原型掩膜数量等于k。
-
掩膜系数(Mask Coefficients):
- 功能: 将上述生成的原型掩膜与特定对象相结合,以生成精确的实例分割掩膜。
- 实现: 通过预测每个锚点(anchor)对应的掩膜系数,来调整和组合原型掩膜。这些系数决定了每个原型掩膜在最终掩膜中的贡献程度。
在生成过程中,YOLACT将原型掩膜与掩膜系数相乘,得到每个实例的最终掩膜。随后,这些掩膜会经过裁剪和阈值处理,以确保分割结果的精确性和有效性。
通过这种方法,YOLACT能够高效地进行实例分割,同时保持较高的处理速度和精度。
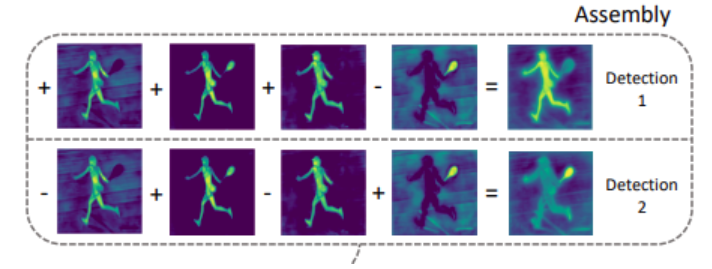
🌕yolov5-sgment的推理的过程
用zidange.jpg这张图来展示整个过程。

🌙predict.py中,模型输出的结果是什么?
先来看代码segment\predict.py:
# Inference
pred, proto = model(im, augment=augment, visualize=visualize)[:2]
模型推理产生了两个输出,一个是pred,一个是proto,它们的维度分别为:
pred = torch.Size([1,25200,117])
proto = torch.Size([1, 32, 160, 160])
🌙pred每个维度代表的含义
1 是批次大小
25200 是包括所有锚点的总预测数(与检测网络相同)
而 117 等于 85 + 32。这意味着有 80 个类别,5 个定位信息(x, y, w, h, conf),最后 32 个是掩膜系数。
🌙proto每个维度代表的含义
1 是批次大小
32 是原型掩膜的数量,每个掩膜的大小为 160x160 像素。
🌙proto中的原型掩膜是什么样的?
那么,这 32 个原型掩膜是怎样的呢?我们来取3个原型掩膜看看:
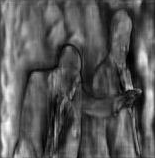


模型输出的这32个原型掩膜是看不出目标的,所以需要掩膜系数(mask coefficients).
模型现在已经输出了大小为 ([1, 25200, 117]) 的pred,这里面已经包含了掩膜系数(mask coefficients),下一步,pred将会输入到NMS。
🌙对pred进行非极大值抑制(NMS)处理
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
对zidange.jpg的预测结果pred进行非极大值过滤后,pred的尺寸变为 torch.Size([3, 38]).
3代表着输入图片中有两个目标,两个人,一个领带
38是6+32
6代表着x,y,w,h,conf,class
32代表着掩膜系数(mask coefficients)
🌙掩膜系数x原型掩膜
现在,用这32个掩膜系数(mask coefficients)去乘32上面的32个proto,就会得到最终的MASK,其中一个领带的分割结果如下:


🌕参考链接
This is how one can interpret YOLO v5 segmentation output!!! #12834


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











