







 本文详细介绍了YOLOv56.0的模型框架,包括输入、Backbone(如CSPDarknet53和ResNet)、Neck(PANet)、Head以及多尺度输出。还探讨了正负样本匹配和损失函数,以及Focus结构和yaml文件的配置。
本文详细介绍了YOLOv56.0的模型框架,包括输入、Backbone(如CSPDarknet53和ResNet)、Neck(PANet)、Head以及多尺度输出。还探讨了正负样本匹配和损失函数,以及Focus结构和yaml文件的配置。
目录
🌕目标检测要解决的3大问题:
1、有没有?
图片中是否有要检测的物体?(检测物体,判定前景背景)
2、是什么?
这些物体分别是什么?(检测到的物体是什么)
3、在哪里?
这些物体在哪里?(画框,描边,变色都行)
🌕模型框架
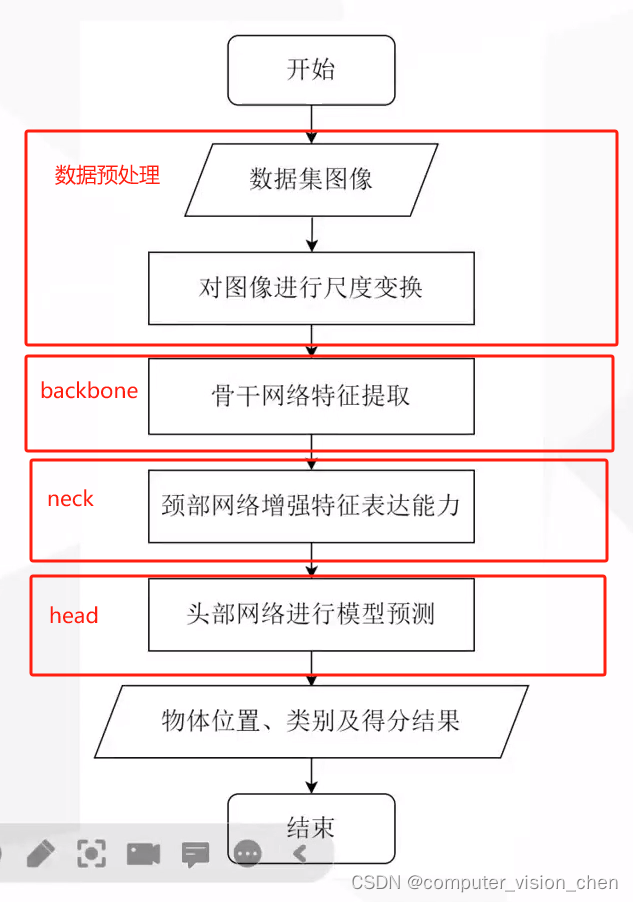
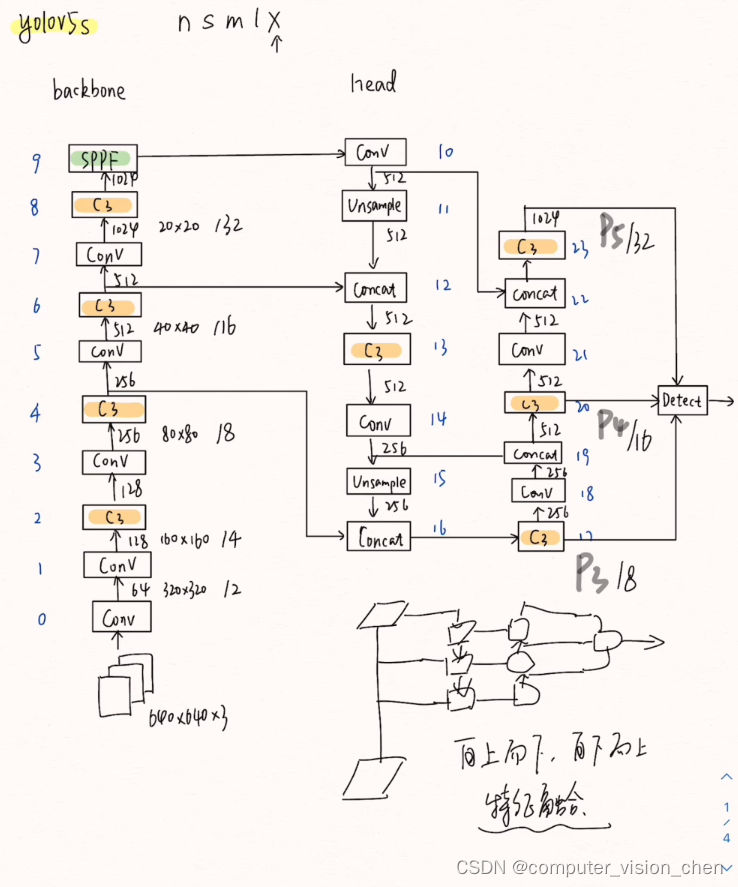
🌙yolov5的6.0版
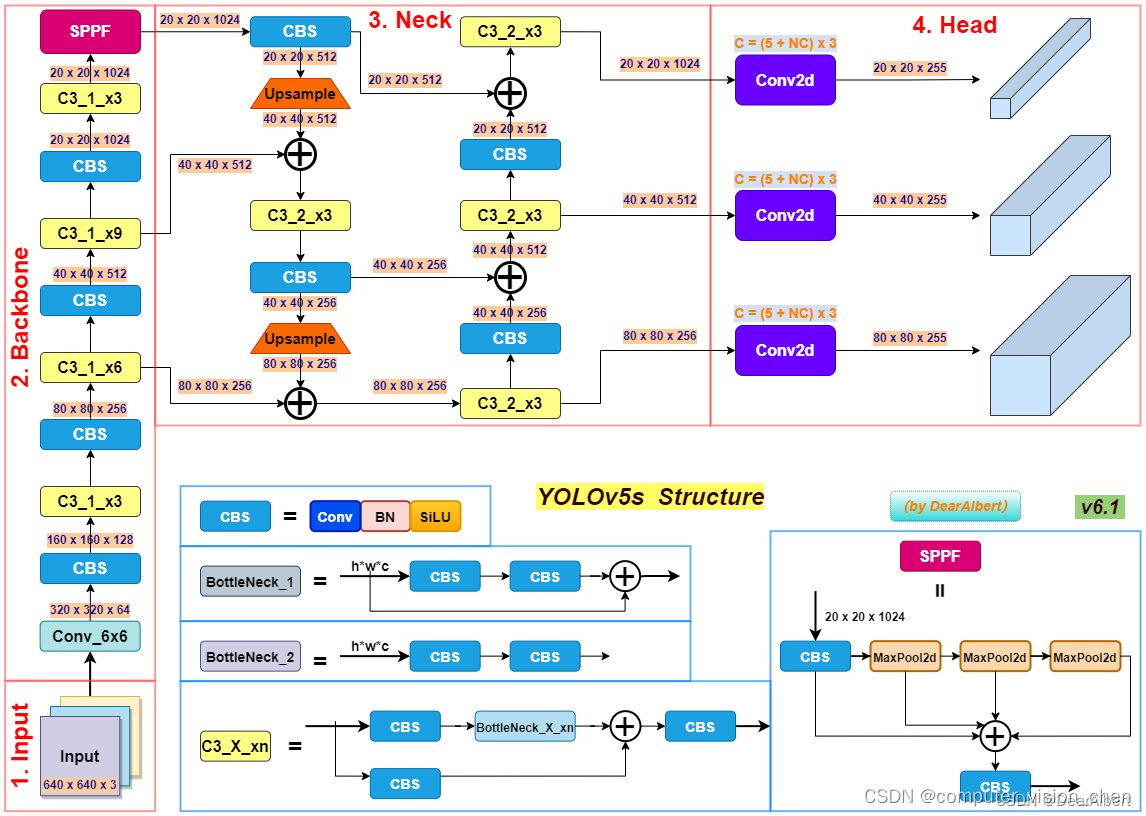
🌕对Yolov5的描述
Yolov5的模型主要由 输入、Backbone、Neck、Head、输出 五部分组成。
🌙输入
输入 640x640x3
🌙backbone
Backbone:负责提取输入图像的特征。
在Yolov5中,常见的Backbone网络包括CSPDarknet53或ResNet。这些网络都是相对轻量级的,能够在保证较高检测精度的同时,尽可能地减少计算量和内存占用。
其结构主要有Conv模块、C3模块、SPPF模块。
Conv模块主要由卷积层、BN层和激活函数组成。
C3模块则将前面的特征图进行自适应聚合。
SPPF模块通过全局特征与局部特征的加权融合,获取更全面的空间信息。
🌙neck
Neck:Neck部分负责对Backbone提取的特征进行多尺度特征融合,并把这些特征传递给预测层。
例如,在Yolov5采用的PANet结构中,通过多次上采样、拼接、点和点积来设计聚合策略,以此更好地利用多尺度特征。
🌙head
Head:Head主要负责进行最终的回归预测,即利用Backbone骨干网络提取的特征图来检测目标的位置和类别。
最后,输出端是模型预测的结果,包括每个目标的类别和其对应的边界框坐标等信息。
🌙输出
有三个尺度的输出:分别为:
20x20x255
40x40x255
80x80x255
输出的255是怎么来的?
每个gred cell生成三个锚框,每一个锚框对应一个预测框,每一个预测框有 5(x,y,w,h,置信度) + 80(80个类别的条件概率)
3x85=255
多尺度输出的作用
grid cell为20x20,输入为640x640的图像下采样32倍得到20x20,对应输入图像的感受野是32x32
grid cell为40x40,输入为640x640的图像下采样16倍得到40x40,对应输入图像的感受野是16x16
grid cell为80x80,输入为640x640的图像下采样8倍得到80x80,对应输入图像的感受野是8x8
20x20负责预测大物体,分配大的锚框。因为它有32x32的感受野。
40x40负责预测中等大小的物体,分配中等大小的锚框。因为它有16x16的感受野。
80x80负责预测小物体,分配小的锚框。因为它的感受野只有8x8。
🌕正负样本匹配 和 损失函数
正负样本匹配和损失函数 详见如下博客:
目标检测——YOLOv3、YOLOv4、YOLOv5、YOLOv7正负样本匹配、YOLO3损失函数理解
https://blog.csdn.net/weixin_45464524/article/details/128683900

🌕模块的细节
🌙自上而下,自下而上的特征融合,可以更充分提取特征
🌙backbone具体细节

-1表示,输入来自上一层,1表示模块个数。模块个数中的3,6,9是要乘以上面的depth_multiple参数的。
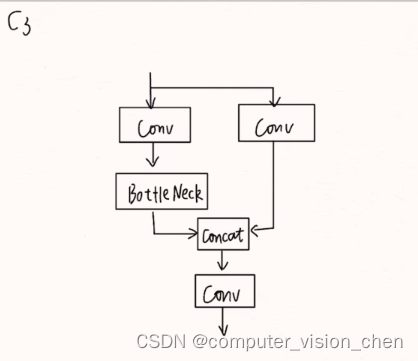
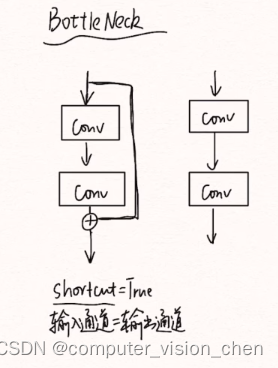
🌙C3模块
3指3个卷积
🌙SPPF模块
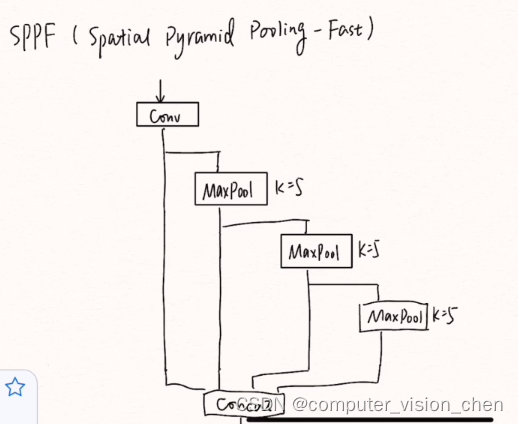
比spp更快,缓解多尺度检测问题
🌙Focus操作
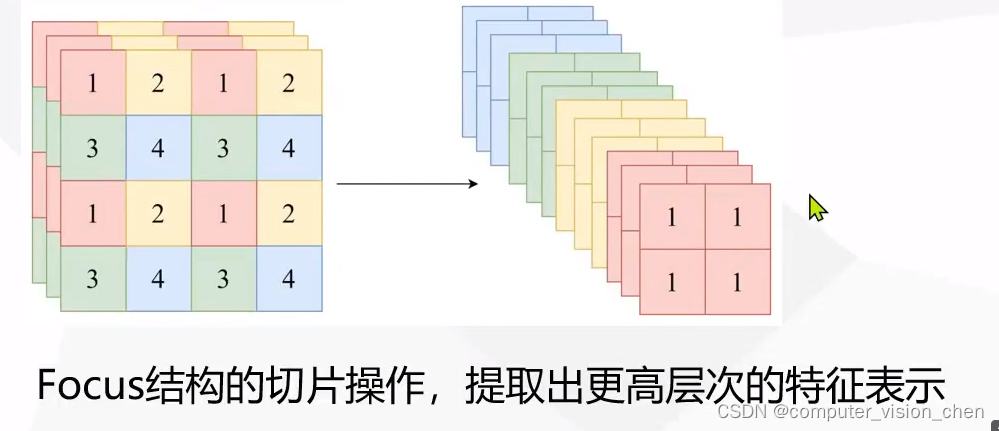
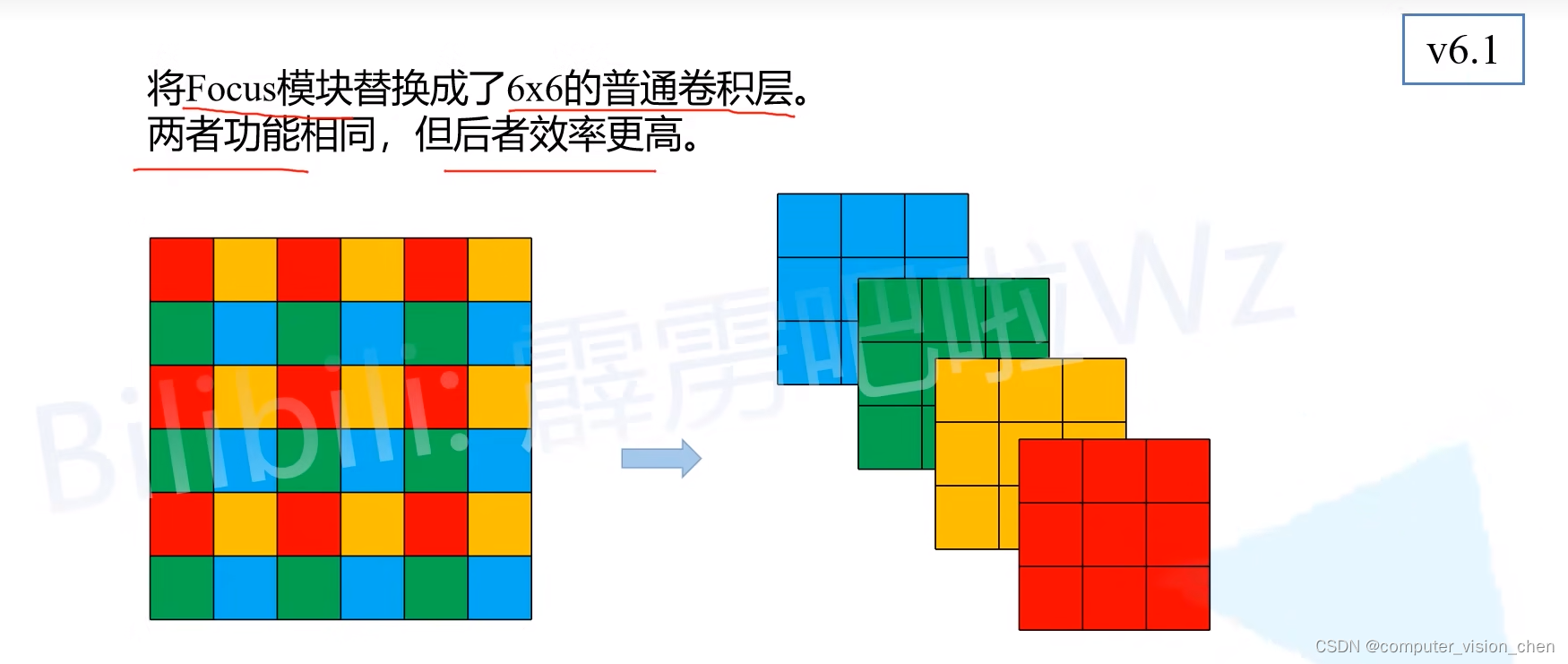
2023年yolov5的focus被替换成了6x6卷积层.
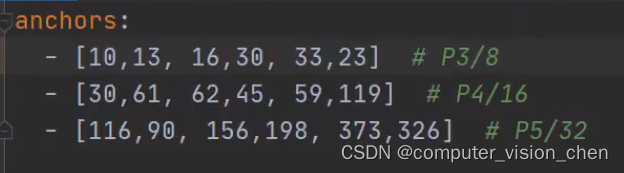
🌙anchors
先验框
🌕yaml文件解读
🌙基本参数

depth_multiple和width_multiple控制模型深度倍数和通道倍数,在smlx上不一样
🌙backbone参数
-1表示,输入来自上一层,1表示模块个数。模块个数中的3,6,9是要乘以上面的depth_multiple参数的。
🌙head参数

上面的画线部分,如[-1,6]表示输入不仅来自上一层还来自于第6层,是它们的拼接
🌕补充
🌙特征融合是怎么实现的?以特征自上而下融合为例
特征自上而下融合时,一种常见的做法是利用特征金字塔结构。在目标检测中,特征金字塔是指由不同尺度的特征图组成的层级结构,其中较高层级的特征图通常具有更低的空间分辨率但拥有更高级的语义信息,而较低层级的特征图则具有更高的空间分辨率但语义信息较少。
举例来说,假设有一个特征金字塔,其中底层是输入图像的高分辨率特征图,而顶层是低分辨率但具有更高级语义信息的特征图。在自上而下的特征融合过程中,高层级特征图的语义信息通过上采样(即增加分辨率)的方式逐层传递到低层级特征图。这个过程可以使用不同的方法,如插值或转置卷积来实现。
例如,假设有三个尺度的特征图,分别是高、中、低。高层级特征图具有较低的空间分辨率但包含语义信息,而低层级特征图具有较高的空间分辨率但信息较少。自上而下的融合过程可能会涉及将高层级特征图通过上采样逐步与中层级特征图融合,然后再进一步上采样和融合到低层级特征图。
如果有高、中、低三个尺度的特征图,可以采用以下方式将它们融合:
1.上采样: 首先,对高层级的特征图进行上采样,使其分辨率与中等层级的特征图相匹配。这可以通过插值方法(例如双线性插值)或转置卷积来实现。
2.融合: 然后将上采样后的高层级特征图与中等层级的特征图进行级联或元素级操作(如加法、串联等)。这个过程将高层级的语义信息与中等层级的细节信息结合起来。
3.重复: 进一步重复这个过程,将融合后的特征图再次上采样,与低层级的特征图融合,逐步融合更多尺度的信息。
🌙yolov5的特征融合方式是级联,什么是级联?
yolov5中的级联特征融合是在通道上操作的。具体如下:
假设我们有两个不同层级的特征图,它们的维度分别为:
特征图 A: 维度为 [3, 4, 5]
特征图 B: 维度为 [3, 4, 5]
这里的维度表示特征图的形状,比如 [3, 4, 5] 表示该特征图有3个通道,每个通道是一个 4x5 的特征图。
接下来,我们将这两个特征图进行级联操作。在Python中,使用PyTorch或TensorFlow等深度学习框架,可以通过以下方式实现级联操作:
import torch
# 假设特征图 A 和 B 分别是两个张量
# 为了示例,我们创建具有相同维度的假数据
feature_map_A = torch.randn(3, 4, 5) # 假设特征图 A 的数据
feature_map_B = torch.randn(3, 4, 5) # 假设特征图 B 的数据
# 将特征图 A 和 B 进行级联操作
concatenated_feature_map = torch.cat((feature_map_A, feature_map_B), dim=0)
# 打印级联后的特征图的形状
print(concatenated_feature_map.shape)
在上述代码中,我们首先创建了两个假设的特征图张量 feature_map_A 和 feature_map_B,然后使用 PyTorch 中的 torch.cat 函数将这两个特征图沿着指定的维度(这里是 dim=0)进行级联操作。最后,打印级联后特征图的形状,你会看到结果是 [6, 4, 5],表示两个特征图在第一个维度上连接在一起,形成了一个包含6个通道的特征图。
🌕其它
1,网络架构
通过解析代码仓库中的 .yaml 文件中的结构代码,YOLOv5 模型可以概括为以下几个部分:
Backbone: Focus structure, CSP network
Neck: SPP block, PANet
Head: YOLOv3 head using GIoU-loss
2,创新点
2.1,自适应anchor
在训练模型时,YOLOv5 会自己学习数据集中的最佳 anchor boxes,而不再需要先离线运行 K-means 算法聚类得到 k 个 anchor box 并修改 head 网络参数。总的来说,YOLOv5 流程简单且自动化了。
2.2, 自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
2.3,Focus结构
Focus 结构可以简单理解为将
大小的输入图片 4 个像素分别取 1 个(类似于邻近下采样)形成新的图片,这样 1 个通道的输入图片会被划分成 4 个通道,每个通道对应的 WH 尺寸大小都为原来的 1/2,并将这些通道组合在一起。这样就实现了像素信息不丢失的情况下,提高通道数(通道数对计算量影响更小),减少输入图像尺寸,从而大大减少模型计算量。
以 Yolov5s 的结构为例,原始 640x640x3 的图像输入 Focus 结构,采用切片操作,先变成 320×320×12 的特征图,再经过一次 32 个卷积核的卷积操作,最终变成 320×320×32 的特征图。
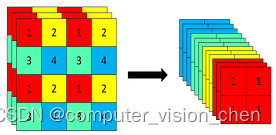
focus结构示例
3,四种网络结构
YOLOv5 通过在网络结构问价 yaml 中设置不同的 depth_multiple 和 width_multiple 参数,来创建大小不同的四种 YOLOv5 模型:Yolv5s、Yolv5m、Yolv5l、Yolv5x。


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











