







Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
(通过最大化多模态互信息实现一体化预训练)
时间:2022年
总结:
1、通过multi-task, single stage的方案替代了以前常见的single-task,multi-stage做法
2、把目前的Supervised Pre-training (SP) / Self-supervised Pre-training (SSP)/ Weakly-supervised Pre-training (WSP) 统一到一个框架(最大化输入和目标的互信息)
3、数学公式太多,看不进去了~~~
TLDR:TLDR 是 too long, didn't read 的缩写,直译的意思是太长了,不读,引申的意思是说,对一段话或者一篇文章的要点总结,扼要概述。
My two cents:意思相当于my opinion/take on this issue,我的拙见,我的观点。
参考引用知乎1:Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
参考引用知乎2:通过多模态互信息最大化实现一体化预训练
疑问:如何进行最大化输入和目标的互信息
前言
为了有效挖掘大规模模型的潜力,人们提出了不同来源的海量数据支持的各种预训练策略,包括监督预训练、弱监督预训练和自监督预训练。事实证明,结合多种预训练策略和来自不同模式/来源的数据可以极大地促进大规模模型的训练。然而,目前的工作采用多级预训练系统,复杂的流程可能会增加预训练的不确定性和不稳定性。因此,希望这些策略能够以单阶段方式集成。在本文中,我们首先提出了一个通用的多模态互信息公式作为统一的优化目标,并证明所有现有方法都是我们框架的特例。在这个统一的视角下,我们提出了一种一体化的单阶段预训练方法,称为最大化多模态互信息预训练(M3I预训练)。我们的方法在各种视觉基准上比以前的预训练方法取得了更好的性能,包括 ImageNet 分类、COCO 对象检测、LVIS 长尾对象检测和 ADE20k 语义分割。值得注意的是,我们成功地预训练了十亿级参数图像主干,并在各种基准上实现了最先进的性能
代码获取:https://github.com/OpenGVLab/M3IPretraining
总结:单阶段预训练方法:最大化多模态互信息预训练(M3I预训练)
疑问:全局平均池化(Global Average Pooling, GAP)
一、介绍
近年来,大规模预训练模型[5,13,27,30,37,55,65,89]以其强大的性能横扫了多种计算机视觉任务。为了充分训练具有数十亿参数的大型模型,研究人员设计了各种无注释的自我训练任务,并从各种模式和来源获取足够大量的数据。
一般来说,现有的大规模预训练策略主要分为三种类型:伪标签数据上的监督学习[20, 65](例如,JFT-300M [83])、网络爬行图像文本对的弱监督学习[37,55](例如,LAION-400M [56]),以及对未标记图像的自监督学习 [5,13,27,30,89]。在海量数据的支持下,所有这些策略都有各自的优势,并且已被证明对于不同任务的大型模型是有效的。为了追求大型模型的更强表示,最近的一些方法[47,77,80]通过在不同阶段直接使用不同的代理任务来结合这些策略的优点,显着推动各种视觉任务的性能边界。
然而,这些多阶段预训练方法的流程复杂且脆弱,可能导致不确定性和灾难性遗忘问题。具体来说,只有在完成整个多阶段预训练流程后才能获得最终性能。由于中间阶段缺乏有效的训练监控,当最终表现不佳时,很难定位有问题的训练阶段。为了消除这种困境,迫切需要开发一种能够利用各种监督信号的单阶段预训练框架。人们很自然地提出以下问题:是否有可能设计一种一体化的预训练方法来具有所有所需的表征属性?
总结:是否有可能设计一种一体化的预训练方法来具有所有所需的表征属性?
为此,我们首先指出不同的单阶段预训练方法通过通用的预训练理论框架共享统一的设计原则。我们进一步将该框架扩展到多输入多目标设置,以便可以系统地集成不同的预训练方法。通过这种方式,我们提出了一种新颖的单阶段预训练方法,称为 M3I 预训练,将所有所需的表示属性组合在一个统一的框架中,并在一个阶段中一起训练。
具体来说,我们首先介绍一个通用的预训练理论框架,可以实例化以覆盖现有的主流预训练方法。该框架旨在最大化输入表示和目标表示之间的互信息,该互信息可以进一步导出为具有正则化项的预测项。 (1) 预测项根据网络输入重建训练目标,这相当于通过为预测分布选择适当的形式而存在的众所周知的预训练损失。 (2)正则化项要求目标的分布保持高熵以防止崩溃,通常通过负样本或停止梯度操作隐式实现。如图1所示,通过采用不同形式的输入-目标配对数据及其表示形式,我们的框架可以包含现有的预训练方法,并为设计一种一体化的预训练方法提供可能的方向。
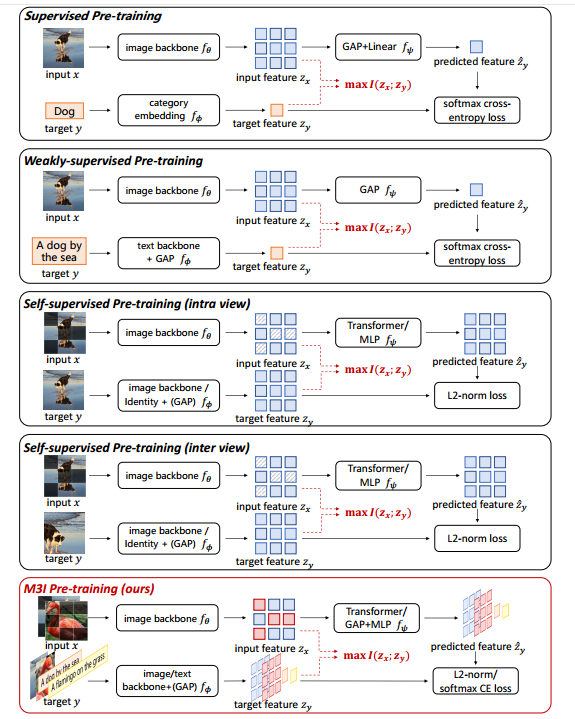
图 1. 不同预训练范式与 M3I 预训练之间的比较。现有的预训练方法都是在优化输入和目标表示之间的互信息,这些可以通过M3I预训练来集成。
inter:不同事物之间 intra:同一事物内部各部分之间。
















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









