







 本文提出了一种名为 TAILOR 的新框架,用于多标签情感识别,它通过对抗性多模态细化、BERT-like Transformer 编码器和标签模态对齐,提高了情感识别的准确性。该框架能够捕捉模态间的共性和多样性,增强标签的判别能力。实验表明,TAILOR 在 CMU-MOSEI 数据集上表现卓越,尤其是在对抗性和标签语义指导的表示学习方面。
本文提出了一种名为 TAILOR 的新框架,用于多标签情感识别,它通过对抗性多模态细化、BERT-like Transformer 编码器和标签模态对齐,提高了情感识别的准确性。该框架能够捕捉模态间的共性和多样性,增强标签的判别能力。实验表明,TAILOR 在 CMU-MOSEI 数据集上表现卓越,尤其是在对抗性和标签语义指导的表示学习方面。
题目:Tailor Versatile Multi-modal Learning for Multi-label Emotion Recognition
时间:2022年
总结:
1、作者提出一种基于对抗的模型,模型对抗性地描述了多个模态之间的共性和多样性,增强了标签表示的判别能力。
2、设计了一个BERT-like Transformer编码器,以粒度下降的方式逐步融合这些表示,并将其与标签语义相结合,生成特定的标签表示(tailored label representation)
3、
关键词:多模态多标签情感识别(MMER)、论文方法(TAILOR)、
文章目录
前言
多模态多标签情感识别(MMER)旨在从异构的视觉、音频和文本模态中识别各种人类情感。以前的方法主要侧重于将多种模态投影到一个共同的潜在空间中并学习所有标签的相同表示,这忽略了每种模态的多样性并且无法从不同角度捕获每个标签更丰富的语义信息。此外,模态和标签的关联关系尚未得到充分利用。在本文中,我们提出了用于多标签情感识别的通用多模态学习(TAILOR),旨在细化多模态表示并增强每个标签的判别能力。具体来说,我们设计了一个对抗性多模态细化模块,以充分探索不同模态之间的共性并加强每种模态的多样性。为了进一步利用标签模态依赖性,我们设计了一个类似 BERT 的跨模态编码器,以粒度下降的方式逐渐融合私有和通用模态表示,以及标签引导解码器,为每个标签自适应地生成定制表示标签语义的指导。此外,我们在对齐和未对齐设置下对基准 MMER 数据集 CMU-MOSEI 进行了实验,这证明了 TAILOR 相对于现有技术的优越性。
代码获得:https://github.com/kniter1/TAILOR
总结:对抗性多模态细化模块;设计了一个BERT-like Transformer编码器,以粒度下降的方式逐步融合这些表示,并将其与标签语义相结合,生成特定的标签表示(tailored label representation)
1. 介绍
在现实世界的应用中,视频通常具有异构表示(即视觉、音频和文本)的特征,并用各种情感标签(例如快乐、惊喜)进行注释。多模态多标签情绪识别(MMER)(Ju et al 2020;Zhang et al 2021a)是指通过利用视频中呈现的视觉、音频和文本模态来识别各种情绪。
多模态学习(Baltrusaitis、Ahuja 和 Morency 2019)处理从多个来源收集的异构信息,这引起了两个新问题:模态内表示和模态间融合。模态内表示学习主要利用多种模态的一致性和互补性来弥合异构模态差距。以前的方法将每种模态投影到共享的潜在空间中以消除冗余。然而,他们忽视了这样一个事实:不同的方式从不同的角度揭示了情感的独特特征。关于融合方式,现有的多式联运融合方法可分为:基于聚合的融合、基于对齐的融合以及它们的混合(Baltrusaitis、Ahuja和Morency 2019)。基于聚合的融合采用串联(Ngiam et al 2011)、张量(Zadeh et al 2017)或注意力(Zadeh et al 2018b)来组合多种模态。基于对齐的融合以潜在的跨模式适应为中心,它将流从一种模式调整为另一种模式(Tsai et al 2019)。多模态学习的关键挑战在于1)如何在保持每个模态多样性的同时整合共性; 2)如何交互地对齐不同的模态分布以实现模态间融合。
总结:
多模态学习的两个新问题:模态内表示和模态间融合。
多模态学习的关键挑战在于1)如何在保持每个模态多样性的同时整合共性; 2)如何交互地对齐不同的模态分布以实现模态间融合。
多标签学习(Zhang and Zhou 2014)处理复杂对象的丰富语义,其中标签相关性被认为是有效多标签学习的关键(Zhu, Kwok, and Zhou 2018)。许多方法通过标签向量之间的相似性来利用标签相关性,然后无缝地合并到相同的表示中。然而,它们无法反映标签之间的协作关系。另一方面,已经开展了许多研究,通过以逐个标签的方式学习特定于标签的表示来提高性能,这些表示是独立生成的,并且可能由于忽略标签相关性而导致次优问题(Zhang、Fang 和 Wang 2021)。多标签学习的关键挑战是如何在特征空间和标签空间中有效地编码每个标签的固有和判别特征。
总结:多标签学习的关键挑战是如何在特征空间和标签空间中有效地编码每个标签的固有和判别特征。
为了解决上述挑战,我们提出了用于多标签情感识别的多功能多模态学习(TAILOR),它足以应对模态异质性和标签异质性。为了弥合异质性差距,我们在以下 3 个空间中捕获模态交互、标签相关性和标签模态依赖。
1)在模态特征空间中,我们较少强调预训练。对于模态内表示,我们设计了一个对抗网络来明确提取通用语义和正交性约束的共性和多样性。对于模间融合,我们提出了一种新颖的基于粒度的融合,具有类似 BERT 的变压器编码器。
2)在标签空间中,我们采用自注意力(Vaswani et al 2017)来利用高阶标签相关性,可以进一步集成以捕获标签语义。
3)为了弥合模态特征空间和标签空间之间的差距,我们采用 Transformer 解码器将融合的多模态表示与标签语义对齐,其目的是在标签语义的指导下学习每个标签的定制表示。
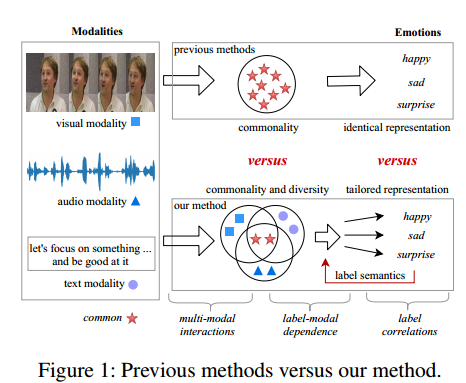
图 1 说明了以前的方法和我们提出的方法之间的区别。主要贡献可概括如下
• 提出了一种用于多标签情感识别(TAILOR)的多功能多模态学习的新框架,该框架以对抗性的方式描述了多种模态之间的共性和多样性,并增强了标签表示的判别能力。
• TAILOR 对抗性地提取私有和通用模态表示。然后设计一个类似 BERT 的 Transformer 编码器,以粒度下降的方式逐渐融合这些表示,并与标签语义相结合,生成定制的标签表示。
• 在基准CMUMOSEI 数据集上进行的大量实验证明了TAILOR 在对齐和未对齐设置中的出色性能。
总结:
以下 3 个空间中捕获模态交互、标签相关性和标签模态依赖。
对抗性地提取私有和通用模态表示。然后设计一个类似 BERT 的 Transformer
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









