



目录
8.3.2 与弱内存模型(如RISC-V RVWMO)的交互
第1章 引言:为什么需要缓存一致性
1.1 从单核到多核:性能瓶颈的转移
在计算机发展的早期,处理器性能的提升主要依赖于时钟频率的提高和指令级并行(ILP)技术的深化(如流水线、超标量、乱序执行)。著名的“摩尔定律”预示着晶体管密度约每18-24个月翻一番,这为频率提升提供了物理基础。然而,进入21世纪后,我们遭遇了“功耗墙”和“内存墙”两大瓶颈。
-
功耗墙:晶体管的动态功耗与时钟频率和电压的平方成正比(P ∝ CV²f)。当频率提升到一定程度后,功耗急剧增加,带来的散热问题难以解决。
-
内存墙:处理器速度的增长远远快于动态随机存取存储器(DRAM)速度的增长。这导致处理器在访问主内存时,需要等待数百个时钟周期,大部分时间处于“饥饿”状态。
为了在频率难以提升的背景下继续遵循摩尔定律提升系统整体性能,计算机架构师们转向了线程级并行(TLP)。与其制造一个更快但极其复杂和耗电的单核,不如将多个相对简单、功耗可控的处理器核心集成到同一个芯片上。这就是多核处理器的时代。
然而,这一架构的转变带来了一个根本性的挑战:如何让这些并行的核心高效、正确地对共享数据进行协同操作? 这个问题的核心,就是缓存一致性。
1.2 缓存的基础角色与价值
要理解一致性,必须先理解缓存为何存在。
1.2.1 存储器的层次结构
现代计算机系统采用了一种典型的“金字塔”型存储器层次结构,其设计原则基于两个关键的物理现象:
-
访问速度越快,单位成本越高,容量越小。
-
程序的局部性原理。
局部性原理包括:
-
时间局部性:如果一个内存位置被访问,那么它很可能在不久的将来再次被访问。
-
空间局部性:如果一个内存位置被访问,那么它附近的内存位置也很可能很快被访问。
存储器的层次结构如下图所示,从上至下,速度变慢,容量变大,单位成本降低。
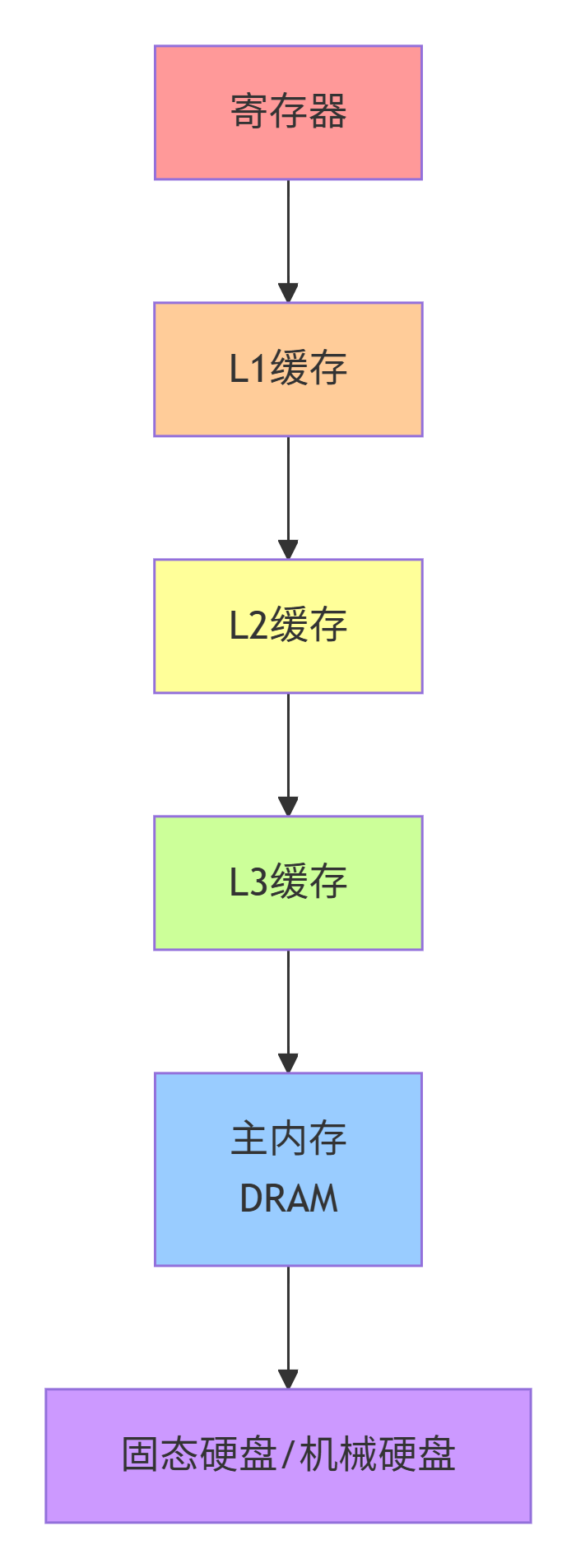
缓存就是位于CPU核心和主内存之间的高速存储器,其目的是将程序最常用到的数据副本保存在离核心最近的地方,从而降低平均数据访问延迟,缓解“内存墙”问题。
1.2.2 缓存命中与未命中
当CPU核心需要访问一个内存地址时,它首先在最快的一级缓存(L1)中查找。
-
缓存命中:所需数据在缓存中找到。CPU可以直接使用该数据,访问延迟极低(通常1-4个周期)。
-
缓存未命中:所需数据不在缓存中。CPU必须发起一次“未命中处理”,从下一级缓存(如L2)或主内存中加载该数据。这个过程会产生数十甚至数百个周期的延迟。
缓存的核心价值就在于通过精巧的设计,使得命中率尽可能高,从而将巨大的内存访问延迟“隐藏”起来。
1.3 缓存一致性问题产生的根源
在单核系统中,缓存是透明的。CPU看到的是一个统一的、一致的“内存视图”,因为所有对数据的操作都经过同一个缓存。然而,在多核系统中,每个核心通常都有自己的私有缓存(至少L1缓存是私有的)。
1.3.1 数据副本的引入
考虑一个双核系统,核心A和核心B各自拥有自己的L1缓存,它们共享主内存。当核心A和核心B都读取同一个内存地址X的数据时,会发生什么?
-
核心A读X,数据从内存加载到A的私有缓存。
-
核心B读X,数据从内存加载到B的私有缓存。
现在,内存地址X的数据在系统中存在三个副本:主内存一份,核心A缓存一份,核心B缓存一份。这三个副本在初始时刻内容是完全相同的。
1.3.2 经典的“丢失写入”与“脏读”问题举例
当某个核心试图修改其缓存中的数据时,问题就出现了。我们通过两个经典例子来说明。
例子一:丢失写入
假设初始状态:内存地址X的值为0,核心A和核心B的缓存中都有X的副本(状态为只读)。
| 步骤 | 核心A操作 | 核心A缓存X的值 | 核心B操作 | 核心B缓存X的值 | 内存X的值 | 问题描述 |
|---|---|---|---|---|---|---|
| 1 | X = 1; | 1 | 0 | 0 | 核心A将X写为1,但这个更新只发生在其私有缓存中,并未写回内存。 | |
| 2 | 1 | X = 2; | 2 | 0 | 核心B将X写为2,同样,更新只在其私有缓存中。 | |
| 3 | 1 | print(X); | 2 | 0 | 核心B读取X,它从自己的缓存中得到2,结果正确。 | |
| 4 | print(X); | 1 | 2 | 0 | 核心A读取X,它从自己的缓存中得到1! 核心B的写入“丢失”了,因为从未同步到核心A的缓存或内存。 |
这个例子展示了,在没有一致性保障的情况下,不同核心对同一内存位置的写入会相互覆盖或不可见,导致程序运行结果与预期严重不符。
例子二:脏读
假设初始状态同上。
| 步骤 | 核心A操作 | 核心A缓存X的值 | 核心B操作 | 核心B缓存X的值 | 内存X的值 | 问题描述 |
|---|---|---|---|---|---|---|
| 1 | X = 1; | 1 | 0 | 0 | 核心A写入1到其缓存。 | |
| 2 | 1 | print(X); | 0 | 0 | 核心B读取X。由于它不知道核心A已经修改了X,它直接从自己的旧缓存副本中读出0,或者从内存中读出0。它读到了一个过时的、脏的数据。 |
这个例子展示了,一个核心的更新未能及时通知到其他核心,导致其他核心读取到旧数据。
1.3.3 一致性与内存一致性模型的区别
这是一个至关重要且容易混淆的概念。
-
缓存一致性:关注的是单个内存位置在多个缓存中的多个副本,在任何时刻是否表现得像“只有一个副本”一样。它解决了上述“丢失写入”和“脏读”的问题,保证了对单个地址读写的正确性。MOESI协议要解决的就是这个问题。
-
内存一致性模型:关注的是不同内存位置的读写操作在多个核心上被观察到的顺序。它定义了对于一个核心发出的读写操作,其他核心将以何种顺序看到这些操作。常见的模型有顺序一致性(SC)、全存储排序(TSO)、松弛内存模型等。
一个简单的类比:
-
缓存一致性:确保所有观众(CPU核心)在看同一份乐谱(内存地址)时,看到的都是指挥(修改者)最新的那一页。它关心的是单一数据的同步。
-
内存一致性模型:定义了指挥(程序员/编译器)对乐谱不同页(不同内存地址)的翻页顺序,在所有观众看来应该是怎样的。它关心的是操作之间的顺序。
一致性是正确性的基础,只有在保证了一致性的前提下,讨论内存模型才有意义。
1.4 缓存一致性协议的分类
为了解决缓存一致性问题,人们设计了多种缓存一致性协议。它们可以从不同维度进行分类。
1.4.1 基于目录 vs. 基于侦听
这是最重要的分类方式,决定了协议的扩展性。
-
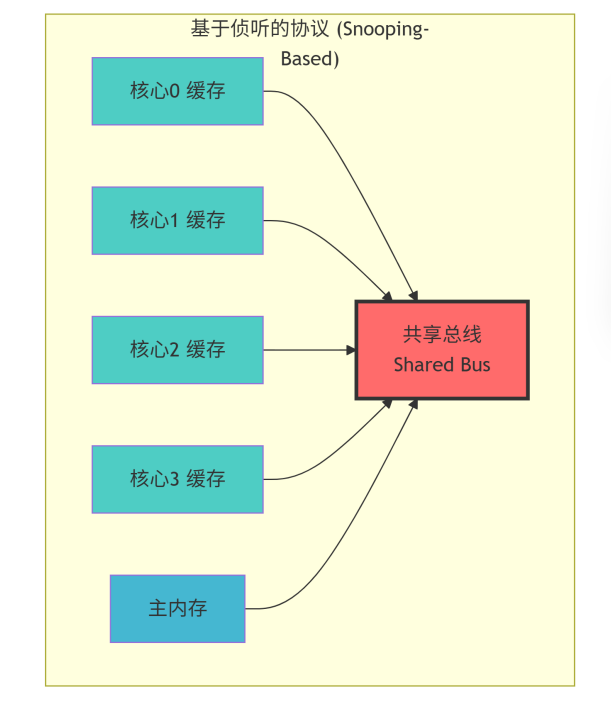
基于侦听的协议:
-
工作原理:所有缓存控制器都连接在一个共享的媒介(如总线)上。当一个缓存需要执行一个可能影响一致性的操作(如写入)时,它通过这个共享媒介向系统中所有其他缓存广播一个消息。其他缓存“侦听”到这个消息后,会根据协议规则采取相应行动(如无效化自己的副本)。
-
优点:实现相对简单,延迟较低(对于小规模系统)。
-
缺点:广播通信方式对共享媒介的带宽压力巨大,扩展性差。随着核心数增加,总线会成为瓶颈。MOESI协议最初就是作为侦听协议被提出的。
-
图示:
-
-
适用场景:通常用于核心数较少(如2-8个)的对称多处理(SMP)系统。
-
-
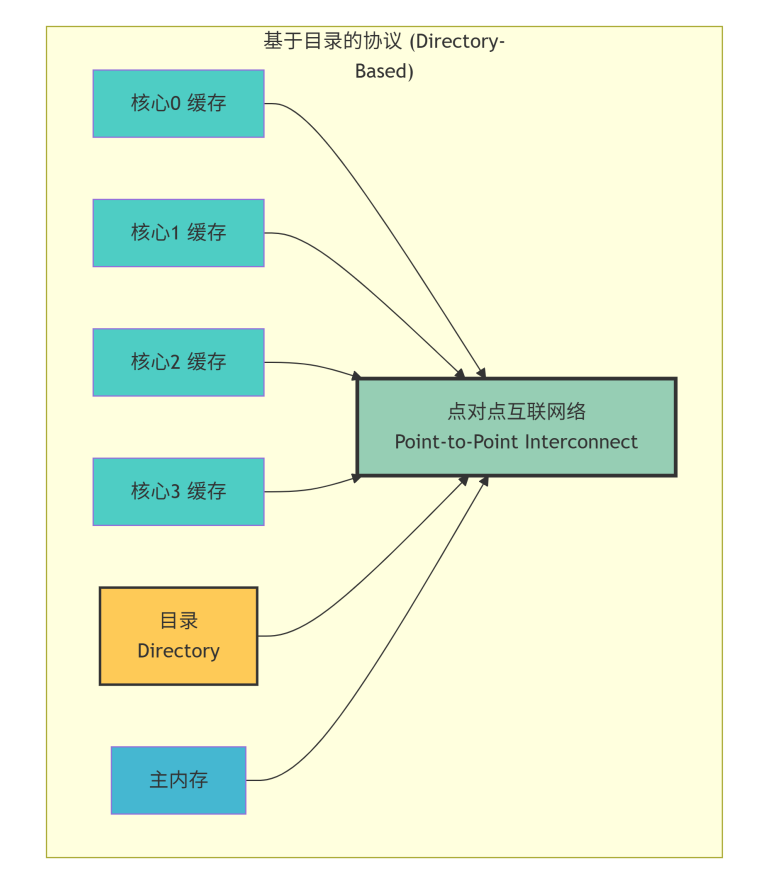
基于目录的协议:
-
工作原理:在系统中维护一个集中的目录,来记录每一个缓存行(一致性的基本单位)被哪些核心缓存了。当一个核心需要修改某个缓存行时,它不再广播,而是先查询目录。目录会准确地知道需要通知哪些核心,然后只向这些核心发送点对点的无效化或更新消息。
-
优点:将广播流量转换为点对点流量,扩展性好,适用于大规模多核系统(数十至数百核心)。
-
缺点:目录的存储开销和访问延迟成为新的设计挑战。
-
图示:
-
适用场景:大规模多核处理器(CMP),众核处理器。
-
1.4.2 写无效 vs. 写更新
这决定了在发生写操作时,协议如何维护一致性。
-
写无效协议:
-
工作原理:当一个核心想要修改一个缓存行时,它首先确保自己是这个缓存行的唯一持有者。它通过向其他持有该缓存行副本的核心发送“无效化”消息来实现这一点。其他核心收到消息后,将自己的副本标记为“无效”。此后,修改核心可以安全地在其私有缓存中进行写入,而其他核心如果再想读取,将发生缓存未命中,从而必须从修改核心或内存获取最新的数据。
-
优点:后续的多次本地写入无需任何通信开销,性能好。这是目前最主流的方案。
-
缺点:当多个核心频繁交替读写同一数据时,会导致大量的无效化和缓存未命中,这种现象称为“缓存乒乓”。
-
MOESI协议属于写无效协议。
-
-
写更新协议:
-
工作原理:当一个核心修改一个缓存行时,它不无效化其他副本,而是将更新后的完整数据广播给所有持有该缓存行副本的核心。这些核心接收到新数据后,会立即更新自己的副本。
-
优点:其他核心总能读到最新的数据。
-
缺点:即使其他核心暂时不需要该数据,更新流量也会占用大量互联带宽,通常性能较差。
-
1.4.3 MOESI协议的定位与优势
MOESI协议是缓存一致性协议发展历程中的一个重要里程碑。它源自较早的MSI和MESI协议,通过引入一个关键的O状态,解决了这些前身协议中的一个主要性能瓶颈。
-
MESI:包含Modified、Exclusive、Shared、Invalid四个状态。它已经是一个非常高效的写无效协议。
-
MOESI:在MESI的基础上增加了Owned状态。
MOESI的核心优势在于对“共享脏数据”的处理:
在MESI协议中,当一个处于Shared状态的缓存行被替换出去时,如果它是“脏的”(即与内存不一致),它不能简单地将之丢弃,因为它可能是系统中唯一的最新副本。它必须将其写回内存。这个过程会产生延迟和带宽消耗。
而在MOESI协议中,引入了O状态。一个处于O状态的缓存副本,是数据的“所有者”。它负责在收到其他核心的读取请求时提供数据,并负责在最终将数据写回内存。这样,当一个共享的脏缓存行需要被替换时,如果存在一个O状态的副本,该副本就会承担起数据所有的责任,而其他被替换的S状态副本可以直接丢弃,无需写回。这显著减少了不必要的内存写入操作,降低了带宽消耗。
因此,MOESI是一种高效的、基于写无效的缓存一致性协议,它既可以通过侦听方式在小规模系统中实现,也可以通过目录方式在大规模系统中实现。其设计的精巧之处在于通过O状态优化了共享写回数据的处理,在现代多核处理器中得到了极其广泛的应用(如AMD的HyperTransport和Intel的某些QPI实现中都能看到其思想)。
本章小结:
本章我们回顾了从单核到多核的演进历程,理解了缓存存在的根本价值,并通过生动的例子揭示了在多核环境下由私有缓存引入的数据不一致问题。我们明确了缓存一致性(解决单个地址多副本问题)与内存一致性模型(解决多地址操作顺序问题)的区别,并对缓存一致性协议进行了分类,最终将MOESI协议定位为一种高效、主流的写无效协议。在下一章中,我们将深入计算机系统内部,详细学习支撑MOESI协议运行的硬件基础架构。
第2章 系统架构基础
MOESI协议并非运行在真空中,它紧密依赖于底层硬件系统的支撑。本章将详细解析构成一个典型多核处理器的基本组件,以及它们如何协同工作,为缓存一致性协议提供舞台。
2.1 多核处理器系统组成
一个现代的多核处理器(Chip Multi-Processor, CMP)是一个复杂的片上系统(SoC)。其简化框图如下,展示了与缓存一致性相关的核心组件:
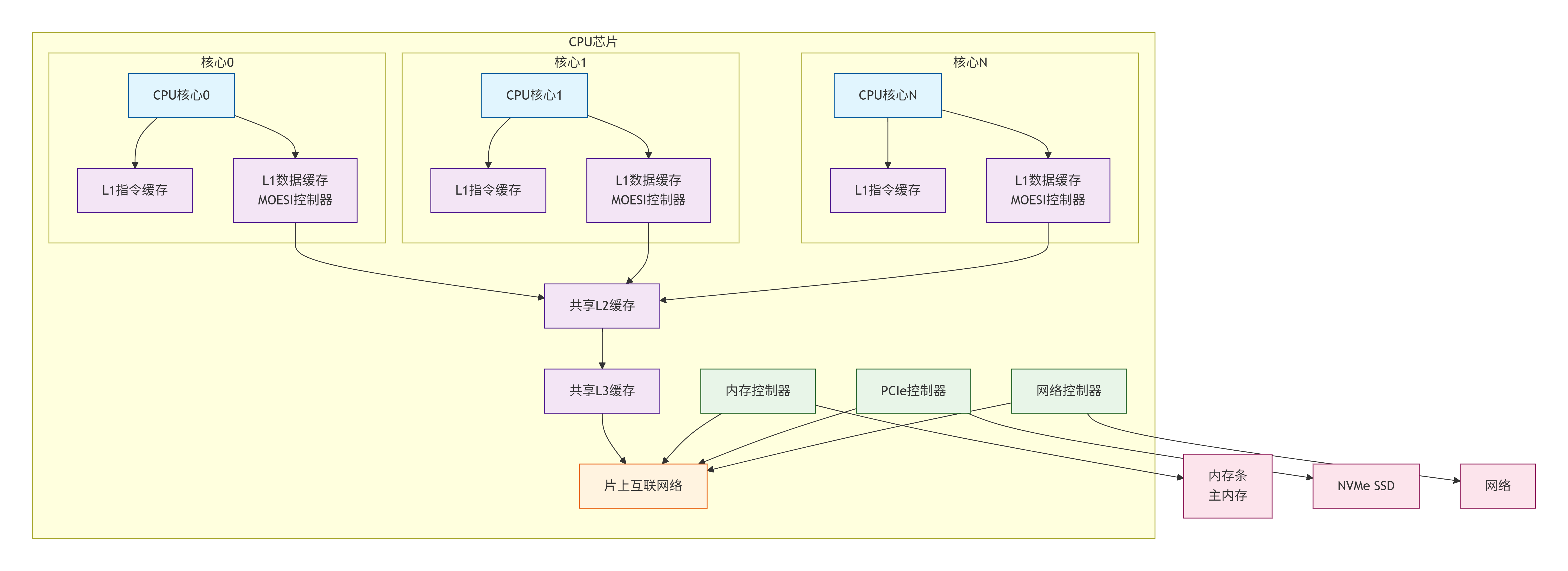
2.1.1 CPU核心与私有缓存
-
CPU核心:是指令执行的主体,包含算术逻辑单元(ALU)、寄存器文件、控制单元等。每个核心都能够独立地取指、译码、执行指令。
-
私有缓存:通常指一级缓存(L1 Cache),它在物理上和逻辑上都与一个特定的CPU核心紧密耦合,访问延迟极低(1-4个时钟周期)。L1缓存通常又分为:
-
L1指令缓存:专门用于缓存程序指令。
-
L1数据缓存:专门用于缓存程序数据。
-
MOESI协议管理的主要对象就是这些私有的L1数据缓存。每个核心的L1数据缓存都独立地缓存数据,从而产生了多个副本,引发一致性问题。
-
2.1.2 共享缓存与片上互联网络
-
共享缓存:通常指二级(L2)或三级(L3)缓存。这些缓存被芯片上的所有CPU核心共享。它们容量更大,但访问延迟也更高(10-50个周期)。共享缓存的作用是:
-
作为私有缓存的下一级存储,吸收L1的未命中请求。
-
减少对片外内存的访问,进一步缓解内存墙。
-
在多核之间共享数据时,可以作为高效的交换媒介。
-
-
片上互联网络:是连接所有核心、缓存、以及其它系统代理(如内存控制器)的“神经系统”。所有用于维护缓存一致性的请求、响应和侦听消息都通过它来传递。它的设计直接决定了协议的延迟、带宽和可扩展性。我们将在2.2节详细讨论。
2.1.3 内存控制器与主内存
-
内存控制器:负责管理处理器对主内存(DRAM)的访问。它接收来自片上互联的读写请求,并将其转换为符合JEDEC标准的DRAM命令和时序,最终将数据返回或写入DRAM芯片。
-
主内存:通常是基于DRAM的模块(如DIMM),它是存储系统的最后一级,容量最大,但访问延迟也最高(通常上百个周期)。在MOESI协议中,内存是数据的终极归属,当一份数据在所有缓存中都不存在,或者需要被替换出去时,才会与内存交互。
2.2 互联网络拓扑
互联网络决定了消息从一个组件传递到另一个组件的路径和方式。不同的拓扑结构在延迟、带宽、复杂度、成本和对一致性协议的支持上各有优劣。
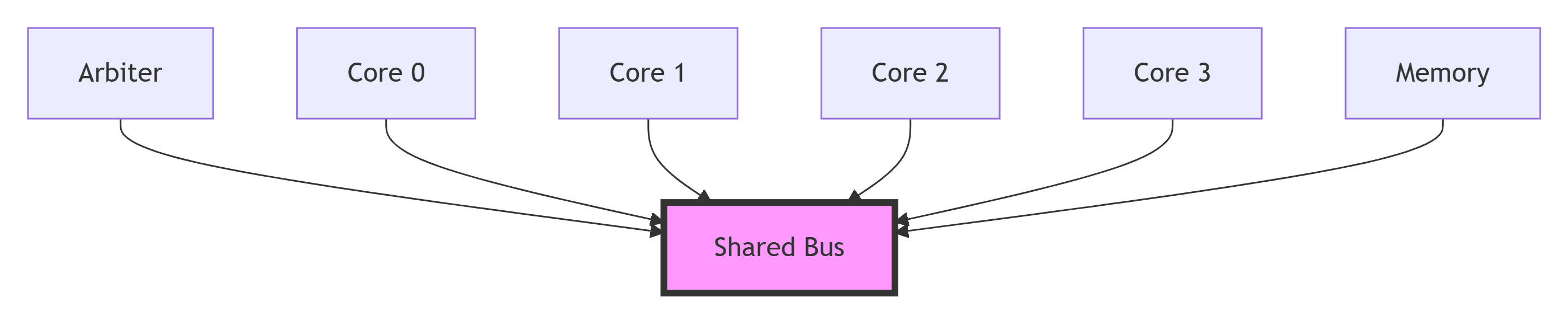
2.2.1 总线
-
描述:一组共享的通信线路,所有设备都连接到这组线路上。任何时刻只能有一个设备作为主控向总线发送数据。
-
工作机制:基于仲裁。当多个设备同时请求总线时,仲裁器决定哪一个获得使用权。其他所有设备都能“侦听”到总线上的通信。
-
优点:
-
实现简单,逻辑清晰。
-
天然的广播媒介,非常适合基于侦听的一致性协议(如最初的MOESI)。一次发送,所有节点都能收到。
-
-
缺点:
-
扩展性极差。总线是共享资源,随着核心数增加,对总线的争用会成为严重瓶颈,带宽受限。
-
单点故障:总线本身出现故障会导致整个系统瘫痪。
-
-
适用场景:核心数较少(2-8个)的嵌入式或低端多核处理器。
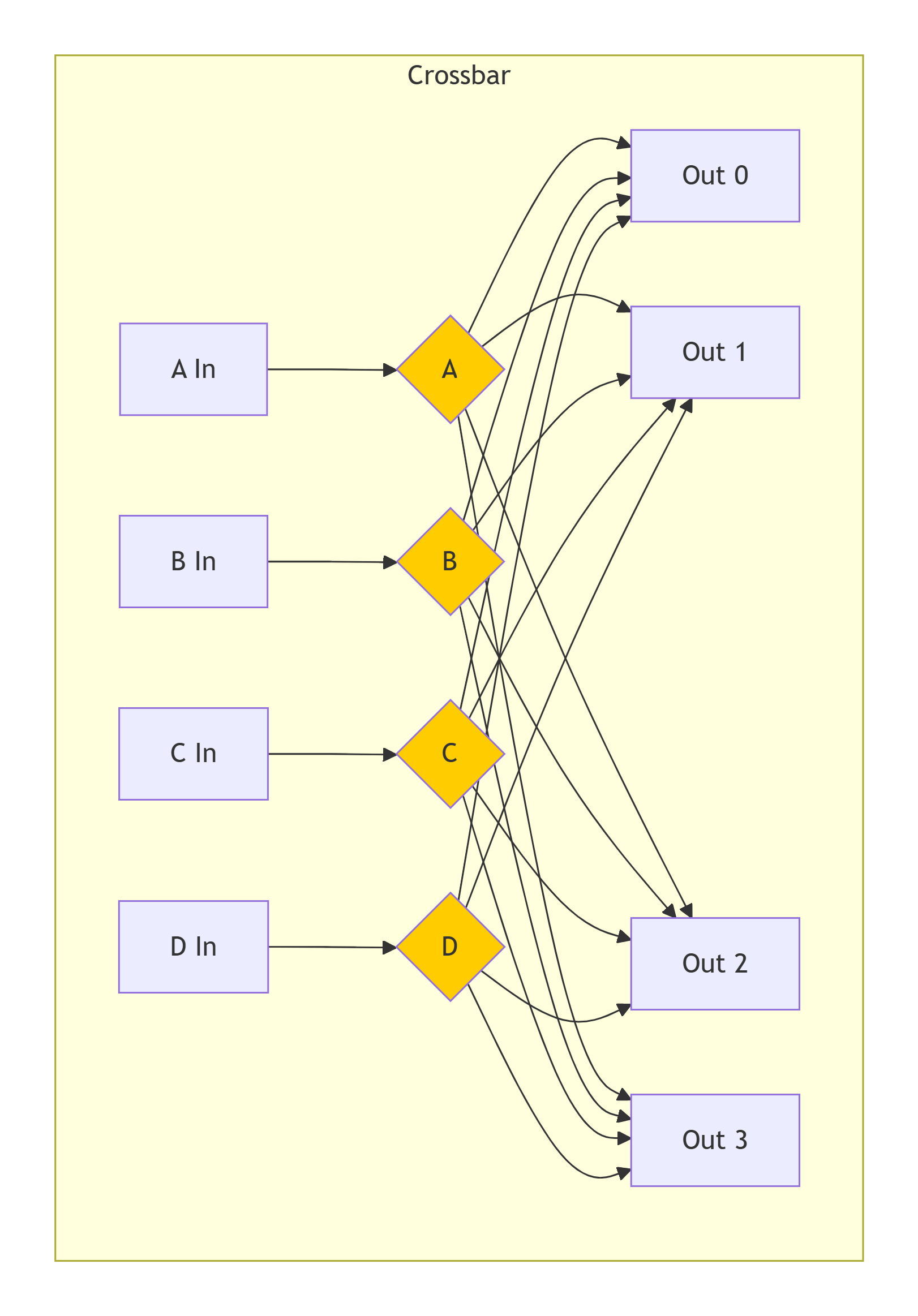
2.2.2 交叉开关
-
描述:一个非阻塞的交换矩阵,在N个输入和M个输出之间建立并行的点到点连接。它允许在输入和输出之间建立多个同时通信的路径。
-
工作机制:例如,一个4x4的交叉开关可以同时让
(In0->Out1),(In1->Out3),(In2->Out0),(In3->Out2)四对通信同时进行,只要输入和输出不冲突。 -
优点:
-
高带宽、低延迟(一旦路径建立)。
-
支持并发通信,可扩展性优于总线。
-
-
缺点:
-
硬件复杂度高,成本随端口数(N*M)平方级增长。
-
-
适用场景:中等规模的多核系统,或作为更大规模网络中的交换节点。
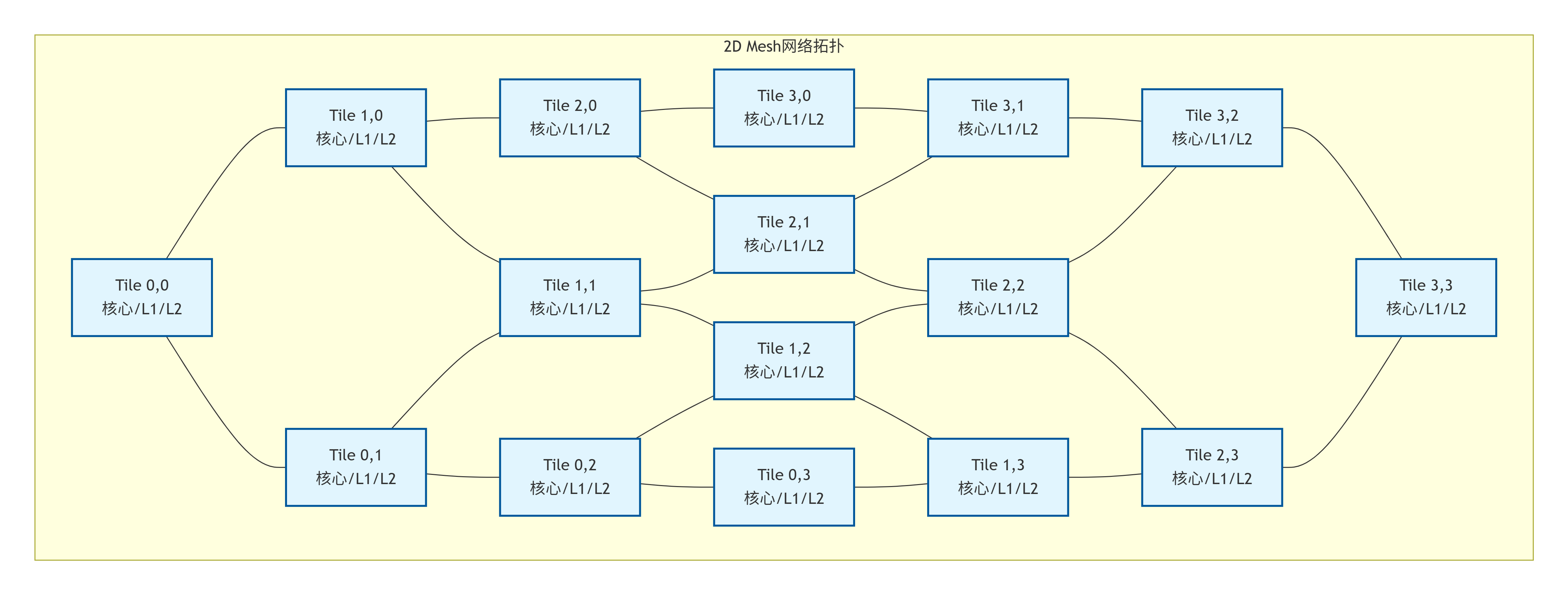
2.2.3 Mesh(网格)
-
描述:目前大规模多核处理器中最主流的拓扑。处理器的Tile(包含核心、缓存切片、路由器等)以二维网格形式排列。
-
工作机制:每个Tile通过路由器与东、南、西、北四个方向的邻居相连。消息通过数据包的形式,在网格中按照特定的路由算法(如XY路由)逐跳传递。
-
优点:
-
可扩展性极佳,布局规整,非常适合VLSI实现。
-
模块化设计,易于扩展规模。
-
提供了较高的对分带宽。
-
-
缺点:
-
网络延迟与曼哈顿距离成正比,位于对角线两端的节点通信延迟较高。
-
需要复杂的路由器设计和流控机制。
-
-
适用场景:英特尔至强、AMD EPYC等现代服务器CPU,以及许多众核研究芯片。
2.2.4 Ring(环)
-
描述:所有节点连接成一个环,每个节点有一个上游邻居和一个下游邻居。数据在环上单向或双向流动。
-
工作机制:消息被封装成数据包,在环上从一个节点传递到下一个节点,直到到达目的地。
-
优点:
-
实现复杂度低于Mesh,布线相对简单。
-
延迟可预测(对于小规模环)。
-
-
缺点:
-
带宽受限,因为所有数据包共享环的链路。随着节点增多,环的周长增加,延迟和争用都会变得严重。
-
可扩展性不如Mesh。
-
-
适用场景:英特尔酷睿系列等客户端CPU,其中核心数通常在几十个以内。

2.3 缓存结构详解
缓存的组织方式决定了它如何查找数据,以及MOESI状态信息存储在哪里。
2.3.1 缓存行:一致性的基本单元
缓存并非以字节为单位进行管理,而是以缓存行为基本单位。一个缓存行是一次从内存中加载的连续字节块。典型的大小是64字节。
-
为什么是缓存行? 利用了空间局部性原理。当程序访问一个地址时,它很可能很快会访问其相邻的地址。一次性加载一个块,可以减少未来访问的未命中次数。
-
对一致性的影响:MOESI协议管理的是整个缓存行的状态。即使只修改了缓存行内的一个字节,整个缓存行的状态也会发生变化,并可能触发无效化其他核心中整个缓存行的副本。这被称为假共享,是性能优化中需要特别注意的问题。
2.3.2 组相联映射
缓存通常被组织成一个由多个“路”和“组”构成的阵列。
-
直接映射:每个内存地址只能被映射到缓存中唯一的一个位置。冲突未命中率高。
-
全相联:每个内存地址可以被放在缓存中的任何位置。查找速度慢,成本高。
-
组相联:折中方案。缓存被分为S个组,每个组有W路。一个内存地址可以被映射到某个特定组中的任何一路。这是最常用的设计。
一个内存地址被划分为三个部分:
-
Tag:用于在同一组内的多路中进行比较,以确定是否命中。
-
Index:用于选择属于哪个组。
-
Block Offset:用于在缓存行内选择具体的字节。
2.3.3 Tag、Index与Offset
下图展示了一个容量为32KB,8路组相联,缓存行大小为64字节的缓存结构。

计算示例:
-
缓存大小 = 32KB = 2^15 bytes
-
缓存行大小 = 64 bytes = 2^6 bytes
-
路数(Ways) = 8 = 2^3
-
组数(Sets) = 总大小 / (行大小 * 路数) = 2^15 / (2^6 * 2^3) = 2^15 / 2^9 = 2^6 = 64 sets
-
Index位数 = log2(组数) = log2(64) = 6 bits (地址位11:6)
-
Block Offset位数 = log2(行大小) = log2(64) = 6 bits (地址位5:0)
-
Tag位数 = 地址总位数 - Index位数 - Block Offset位数 = 64 - 6 - 6 = 52 bits (地址位63:12)
2.3.4 状态位与脏位
在缓存行的元数据(Tag Store)中,除了地址Tag,还有用于维护一致性的状态位。
-
对于MOESI协议,每个缓存行需要至少3个状态位(因为2^3=8 > 5个状态)来编码M、O、E、S、I这五种状态。
-
“脏位”是状态的一部分:在MOESI中,处于M状态和O状态的缓存行被认为是“脏的”,因为它们包含的数据与主内存不一致。当这些行被替换时,必须写回内存。而E和S状态是“干净的”,可以直接丢弃。
2.4 事务与消息传递基础
一致性协议的本质是缓存控制器之间通过交换消息来协同管理状态。
2.4.1 请求、响应与侦听
-
核心请求:由CPU核心发起,是其执行 load/store 指令的体现。例如
PrRd(私有读)和PrWr(私有写)。 -
一致性请求:由缓存控制器在处理核心请求未命中时,代表核心向系统发出的请求。例如
BusRd(总线读,希望获取一个共享副本),BusRdX(总线独占读,希望获取独占权以进行写入),Upgrade(升级,从共享升级到独占,无需数据)。 -
侦听请求:当一致性请求在互联网络上传播时,其他缓存控制器会“侦听”到这些请求。它们需要根据自己本地缓存行的状态做出响应。
-
响应:
-
数据响应:提供所请求的缓存行数据。可能来自另一个缓存(如果其处于M/O/E状态)或来自内存。
-
确认响应:表明某个操作已完成,例如无效化确认。
-
2.4.2 事务ID与排序
-
事务ID:系统为每个进行中的事务分配一个唯一标识符。用于将请求与响应关联起来,特别是在无序的互联网络中。
-
排序:对于系统的正确性至关重要。例如,对于同一个地址的写操作必须在所有核心看来以相同的顺序发生。不同的互联网络拓扑和内存模型对排序有不同要求。总线天然提供了全序,而Mesh等点对点网络则需要额外的协议来保证排序。
本章小结:
本章我们构建了一个多核处理器的硬件蓝图。我们了解了核心、私有缓存、共享缓存、互联网络和内存控制器等关键组件及其角色。我们深入探讨了不同互联拓扑的优缺点,并详细解析了缓存的组织结构,特别是缓存行和组相联映射的概念。最后,我们介绍了事务和消息传递的基本类型。所有这些知识为我们下一章深入MOESI协议的核心——状态转换——打下了坚实的基础。在第三章,我们将看到这些硬件组件如何通过精妙的协议状态机动态交互,共同维护数据的一致性。
第3章 MOESI协议总览
在理解了缓存一致性的必要性(第1章)和系统架构基础(第2章)之后,我们现在可以正式深入MOESI协议的核心。本章将提供MOESI协议的全局视角,精确定义其五个核心状态,阐述其设计哲学,并通过与早期协议的对比来凸显其优势。最后,我们将构建一个简化的系统模型,作为后续深入分析的基础。
3.1 MOESI的五个状态定义
MOESI协议的精髓在于其五个状态。每个缓存行在任何时刻都处于且仅处于以下一种状态。理解这些状态是理解整个协议的基础。
3.1.1 Modified - 已修改
-
权限:独占的写权限。当前缓存是系统中唯一持有该缓存行有效副本的缓存。
-
数据一致性:缓存中的数据已被修改,与主内存中的副本不一致(即“脏”数据)。
-
责任:当前缓存负责在未来的某个时刻(如该行被替换时)将数据写回主内存。
-
核心行为:本地核心可以无延迟、无外部通信地对其进行任意次数的读或写操作。
-
类比:图书馆中,你借走了一本书(独占),并在书上做了笔记(修改)。你是这本书的唯一持有者,你的副本是最新的,图书馆的副本是旧的。
3.1.2 Owned - 独占
-
权限:共享的读权限。当前缓存和其他一个或多个缓存可能同时持有该行的副本。
-
数据一致性:缓存中的数据是已修改的(“脏”的),与主内存不一致。它是系统中该数据的权威副本。
-
责任:
-
当其他缓存发生读未命中时,有责任提供数据给请求者。
-
最终负责将数据写回主内存(当被替换或需要时)。
-
-
核心行为:本地核心可以读取,但不能直接写入。要写入必须先通过总线事务获得独占权(转换为M状态)。
-
类比:你是那本被做了笔记的书的“所有者”。你可以把书的内容分享给其他询问的人(提供数据),但如果你想在笔记上增加内容(写入),你需要先通知所有其他拥有副本的人,让他们把副本还回来(无效化)。
-
注意:这是MOESI协议区别于MESI协议的关键状态,它允许脏数据被共享。
3.1.3 Exclusive - 独占
-
权限:独占的写权限。当前缓存是系统中唯一持有该缓存行有效副本的缓存。
-
数据一致性:缓存中的数据与主内存中的副本完全一致(即“干净”数据)。
-
责任:无立即责任。如果被替换,可以直接丢弃,因为内存中已有最新数据。
-
核心行为:本地核心可以读取,也可以无声地转换为M状态并进行写入,无需通知任何其他组件。这是最理想的读命中状态。
-
类比:你从图书馆借走了一本书,且是唯一借阅者。书是干净的,你可以随时在书上做笔记(转为M状态),而无需通知图书馆。
3.1.4 Shared - 共享
-
权限:共享的读权限。当前缓存和其他一个或多个缓存同时持有该行的副本。
-
数据一致性:缓存中的数据是干净的,与主内存一致。数据可能来自内存或一个处于O状态的缓存。
-
责任:无特殊责任。如果被替换,可以直接丢弃。
-
核心行为:本地核心可以读取,但不能直接写入。要写入必须先通过总线事务获得独占权(转换为M状态)。
-
类比:你和几个人同时在看图书馆里的同一本书的复印本。你们都可以读,但如果任何人想修改书的内容,必须收回并销毁所有复印本,然后才能修改原始书籍。
3.1.5 Invalid - 无效
-
权限:无权限。该缓存行中的数据是无效的,不可使用。
-
数据一致性:不适用。
-
责任:无。
-
核心行为:本地核心对该地址的读或写操作都会导致缓存未命中,从而触发一个总线事务来获取数据。
-
类比:你手头没有这本书,也没有它的复印本。如果你想读或写,必须去图书馆借阅。
3.1.6 状态总结与对比表
| 状态 | 权限 | 数据一致性 | 副本数量 | 本地可读? | 本地可写? | 责任 |
|---|---|---|---|---|---|---|
| M (Modified) | 独占 | 脏 | 唯一 | 是 | 是(无声) | 最终写回 |
| O (Owned) | 共享 | 脏 | ≥1 | 是 | 否(需升级) | 提供数据、最终写回 |
| E (Exclusive) | 独占 | 干净 | 唯一 | 是 | 是(无声) | 无 |
| S (Shared) | 共享 | 干净 | ≥2 | 是 | 否(需升级) | 无 |
| I (Invalid) | 无 | 无效 | - | 否 | 否(需获取) | 无 |
关键洞察:
-
M和E状态都提供了无声写入的能力,是性能的关键。它们的区别在于数据是否是脏的。
-
O状态是MOESI的灵魂:它打破了“共享的数据必须是干净的”这一限制,允许脏数据被安全地共享,从而避免了在共享读频繁的情况下反复写回内存。
-
从S状态写入需要通信,因为需要无效化其他共享者。
3.2 MOESI协议的核心思想
3.2.1 状态机模型
MOESI协议本质上是一个分布式的、由事件驱动的有限状态机。
-
分布式:每个缓存控制器独立维护自己缓存中每一行的状态。
-
事件驱动:状态转换由两类事件触发:
-
本地请求:当前核心的读/写操作。
-
远端请求:通过总线/网络侦听到的其他核心的请求。
-
-
协议的正确性依赖于所有缓存控制器对同一套状态转换规则达成共识。
3.2.2 所有权与数据来源
MOESI协议引入了明确的“所有权”概念。
-
所有者:在任何时刻,对于一个缓存行,最多只有一个缓存可以处于M或O状态,这个缓存就是该行的“所有者”。
-
数据来源:当发生读未命中时,数据应该由所有者提供(如果存在),或者由内存提供(如果不存在所有者,即所有副本都是S或E状态)。
-
优势:这确保了数据请求者总能获得最新的数据,并且将内存更新延迟到必要时(如行被替换或没有共享者时),这被称为写回策略,优于每次都更新内存的写通策略。
3.2.3 与MSI/MESI协议的对比与演进
理解MOESI的演进路径,能更好地体会其设计动机。
-
MSI协议:这是最基础的写无效协议。
-
状态:Modified, Shared, Invalid。
-
瓶颈:从S状态写入时,需要发
BusRdX获取数据并无效化其他副本,即使请求者已经有数据了。更重要的是,当一个处于M状态的脏行被其他核心读取时,它必须先写回内存,然后才能降级为S状态并让请求者从内存读。这产生了一次不必要的内存写入。
-
-
MESI协议:在MSI基础上增加了E状态。
-
状态:Modified, Exclusive, Shared, Invalid。
-
优化:E状态允许无声写入,优化了首次写入的性能。同时,从M状态响应读请求时,数据可以直接从缓存提供给请求者,无需先写回内存,状态转换为S。这避免了MSI中的不必要的写回。
-
遗留问题:当多个核心共享一个脏数据时(即一个核心在M状态,其他核心通过它获取数据后变为S状态),当其中一个S状态的副本被替换时,如果它是“最后一个”共享者,它可能需要将数据写回内存,因为它不知道原始的“所有者”是谁。这导致了不必要的写回。
-
-
MOESI协议:在MESI基础上增加了O状态。
-
状态:Modified, Owned, Exclusive, Shared, Invalid。
-
最终优化:O状态明确了共享脏数据的所有权。处于O状态的缓存是唯一负责最终写回的缓存。其他S状态的副本被替换时,可以简单地丢弃。这彻底解决了MESI中最后一个共享者需要写回的问题,进一步减少了内存带宽的消耗。
-
演进总结:MSI -> MESI -> MOESI 的演进,是一个不断优化、减少不必要总线事务和内存访问的过程。
3.3 一个简化的MOESI系统模型
为了便于后续章节的讨论,我们定义一个简化的基于总线侦听的MOESI系统模型。
3.3.1 系统框图
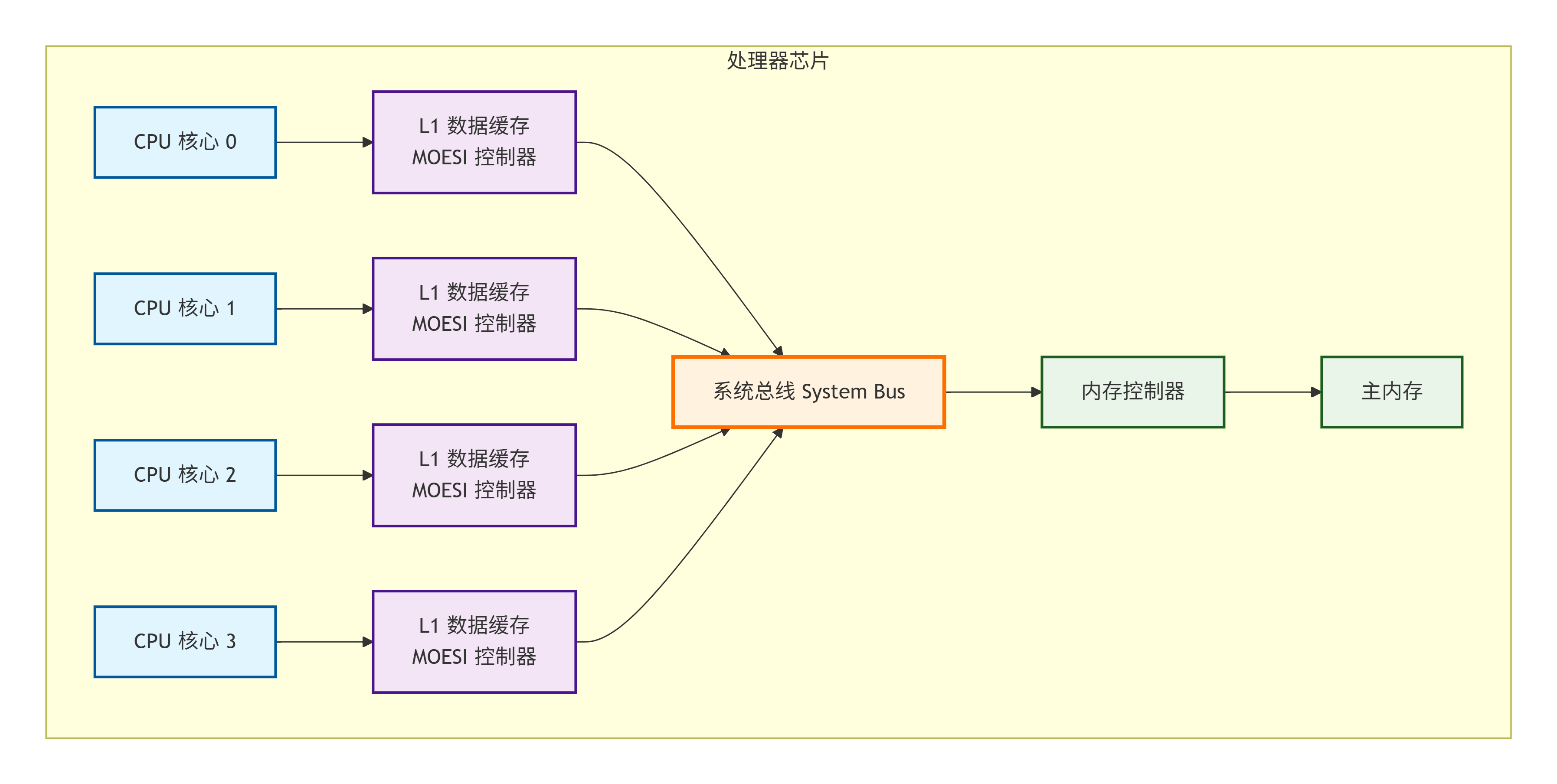
组件说明:
-
CPU Cores:执行指令,产生内存读写请求。
-
L1 D-Caches:私有数据缓存。每个缓存都集成了一个MOESI控制器,负责管理本地缓存行的状态并处理总线事务。
-
System Bus:共享通信媒介。所有一致性请求(如
BusRd,BusRdX)都在此广播。所有缓存控制器持续侦听总线上的活动。 -
Memory Controller & Main Memory:数据的最终归属地。当没有缓存能提供数据时,由内存负责响应。
3.3.2 消息类型定义
在我们的简化模型中,定义了以下基本总线事务类型:
-
BusRd:请求一个数据的共享副本。希望将状态变为S或E。 -
BusRdX:请求一个数据的独占副本。目的是写入,会无效化其他所有副本。希望将状态变为M。 -
Upgrade:请求将已有的共享副本(S状态)升级为独占权。无需数据传输,只需无效化其他副本。希望将状态变为M。 -
Flush:将脏数据(M或O状态)写回内存。通常在缓存行被替换时发生。
这些事务的详细交互和状态转换将是第4章的重点。
本章小结:
本章我们奠定了MOESI协议的全部理论基础。我们精确定义了M、O、E、S、I五个状态,明确了各自的权限、数据一致性和责任。通过与MSI和MESI协议的对比,我们清晰地看到了MOESI协议的演进路径和性能优势所在——即通过引入O状态,优化了共享脏数据的处理,减少了不必要的内存写入。最后,我们建立了一个简化的基于总线的侦听系统模型,为后续深入分析状态转换和消息流做好了准备。从下一章开始,我们将让这个状态机“动”起来,深入其每一个状态转换的细节。
第4章 MOESI状态转换详解
MOESI协议的精髓在于其分布式的状态机。每个缓存行在每个缓存控制器中都维护着一个状态(M、O、E、S、I),这些状态会根据两类事件进行转换:
-
本地核心请求:当前核心的CPU对缓存发出的读写操作。
-
远端侦听请求:通过互联网络收到的、来自其他核心缓存控制器的一致性请求。
协议通过定义这些事件触发下的状态转换和相应动作,来保证全局数据的一致性。
4.1 本地核心发起的操作
这是状态转换的驱动力之一,源于CPU执行 Load 和 Store 指令。
4.1.1 读命中/读未命中
-
读命中:CPU要读取的数据就在当前缓存中,且状态不是Invalid。
-
行为:缓存控制器直接从本地缓存行提供数据给CPU。状态不发生改变。
-
原因:本地已经有一份有效数据(无论是独占还是共享),读取操作不会影响其他副本的一致性。
-
示例:
-
状态为
S,核心读 -> 状态保持S,数据从缓存提供。 -
状态为
E,核心读 -> 状态保持E,数据从缓存提供。 -
状态为
M,核心读 -> 状态保持M,数据从缓存提供。 -
状态为
O,核心读 -> 状态保持O,数据从缓存提供。
-
-
-
读未命中:CPU要读取的数据不在当前缓存中,或其状态为Invalid。
-
行为:缓存控制器必须从系统中获取数据。它会向互联网络发出一个
BusRd(总线读)事务。这个事务的目的是获取一份数据副本,并通常期望以S(共享)状态缓存它。 -
后续:系统其他部分(其他缓存或内存)会对此
BusRd请求做出响应。当前缓存控制器在收到数据后,会根据响应信息决定最终的状态(可能是S或E)。具体逻辑在侦听处理部分详述。
-
4.1.2 写命中/写未命中
-
写命中:CPU要写入的数据就在当前缓存中。
-
行为:取决于当前缓存行的状态。
-
状态
M或E:核心可以直接写入本地缓存。因为状态M表示独占且已修改,E表示独占且干净,都没有其他共享副本。写入后,状态变为M(如果原来是E)。 -
状态
S或O:核心不能直接写入,因为存在其他共享副本。缓存控制器必须向互联网络发出一个BusUpgr(总线升级)或BusRdX(总线独占读)事务。这个事务的目的是无效化所有其他缓存中的副本,从而获得独占权。收到其他缓存的无效化确认后,才能将状态转换为M并进行写入。
-
-
示例:
-
状态为
S,核心写 -> 发出BusUpgr-> 收到响应后,状态变为M,然后执行写入。 -
状态为
O,核心写 -> 发出BusRdX-> 收到响应后,状态变为M,然后执行写入。
-
-
-
写未命中:CPU要写入的数据不在当前缓存中,或其状态为Invalid。
-
行为:缓存控制器必须获得该数据的独占权。它会向互联网络发出一个
BusRdX(总线独占读)事务。这个事务一方面会获取数据,另一方面会无效化所有其他副本。 -
后续:当数据返回后,缓存控制器会将其以
M状态缓存,并同时完成CPU的写入操作。
-
4.2 远端侦听请求触发的操作
这是维护一致性的关键机制。当一个缓存控制器观察到总线上有其他控制器发出的一致性请求时,它必须根据自己本地缓存行的状态做出响应。
4.2.1 读请求侦听
侦听到其他核心发来的 BusRd 请求。
-
本地状态
I:不采取任何行动。本地没有有效数据。 -
本地状态
S或O或E:-
行为:这些状态都意味着本地数据是有效的(
S/O/E)且可能是最新的(O/E)。缓存控制器需要提供数据吗?-
在基于总线的侦听协议中,通常由内存或拥有最新数据的缓存来提供数据。为了优化,如果缓存处于
E或M状态,它可以提供数据。但对于S,数据可能不是最新的(虽然干净),通常由内存或O状态的缓存提供。 -
关键点:如果本地状态是
E,在侦听到BusRd后,由于现在出现了另一个读者,独占性丧失,状态必须降级为S。 -
如果本地状态是
O,它已经是共享的,状态保持O,但它可能需要负责提供数据。
-
-
-
本地状态
M:-
行为:这是“脏”数据,内存中的数据是旧的。该缓存必须对
BusRd请求作出响应,将最新的数据提供出去(通常通过总线,或点对点响应)。 -
状态转换:由于现在出现了另一个读者,数据不再是独占的,但缓存中的副本仍然是最新的(脏的)。此时,状态从
M转换为O。这就是O状态的典型产生场景——一个被共享的脏数据。
-
4.2.2 写请求侦听
侦听到其他核心发来的 BusRdX 或 BusUpgr 请求。这些请求的目标是获得独占写入权。
-
本地状态
I:不采取任何行动。 -
本地状态
S或O或E:-
行为:这些状态都意味着本地有该数据的有效副本。但由于另一个核心将要进行独占写入,当前核心的副本必须失效。缓存控制器会将本地副本状态标记为
I(无效)。如果协议要求,它可能需要发出一个“确认”响应。 -
特殊处理(
O状态):如果本地处于O状态,意味着它是数据的“所有者”和唯一的最新副本(虽然是共享的)。在转换为I之前,它必须将数据提供给请求者,因为请求者的BusRdX需要获取数据。
-
-
本地状态
M:-
行为:这是最复杂的情况。本地拥有唯一的、已修改的副本,而另一个核心试图写入。当前缓存必须放弃所有权。
-
必须响应:将最新的
M数据提供给请求者。 -
状态转换:本地状态从
M转换为I。因为另一个核心将获得独占权并进行修改,当前副本立即过时。
-
-
4.3 完整的状态转换表与图
为了系统地描述所有可能的转换,我们使用状态转换表和状态转换图。
4.3.1 状态转换表
下表横轴是触发事件,纵轴是当前状态,单元格内容为:[动作] -> [新状态]。
| 当前状态 | 核心读 (PrRd) | 核心写 (PrWr) | 侦听 BusRd | 侦听 BusRdX / BusUpgr | 侦听 Flush (替换) |
|---|---|---|---|---|---|
| I (Invalid) | 发 BusRd -> S/E | 发 BusRdX -> M | - -> I | - -> I | - -> I |
| S (Shared) | 命中 -> S | 发 BusUpgr -> M | - -> S | 无效化 -> I | 写回? (若脏) -> I |
| E (Exclusive) | 命中 -> E | 写入 -> M | 提供数据? -> S | 提供数据 & 无效化 -> I | 丢弃 (干净) -> I |
| O (Owned) | 命中 -> O | 发 BusRdX -> M | 提供数据 -> O | 提供数据 & 无效化 -> I | 写回内存 -> I |
| M (Modified) | 命中 -> M | 写入 -> M | 提供数据 -> O | 提供数据 & 无效化 -> I | 写回内存 -> I |
注:S/E 表示最终状态可能是 S 或 E,取决于是否有其他缓存共享该数据。
4.3.2 状态转换图
以下Mermaid状态图直观地展示了所有转换关系。它是对上表的图形化表示,是理解和记忆MOESI协议的终极工具。
4.4 典型案例逐步分析
让我们通过几个具体的场景,一步步跟踪MOESI协议是如何工作的。假设一个三核系统(Core A, B, C)。
4.4.1 案例一:首次读取与共享
-
初始:地址
X在内存中值为0。所有核心的缓存中都没有X(状态I)。 -
Core A 读 X (PrRd):
-
A缓存未命中,发出
BusRd。 -
其他缓存(B, C)侦听到
BusRd,状态均为I,无响应。 -
内存响应,提供数据
0。 -
结果:Core A 缓存
X,状态为E(因为它是唯一缓存者)。A的CPU得到值0。
-
-
Core B 读 X (PrRd):
-
B缓存未命中,发出
BusRd。 -
Core A 侦听到
BusRd,发现自己是E状态。-
动作:A提供数据(或允许内存提供),并将其状态从
E降级为S。
-
-
B收到数据
0。 -
结果:Core A 和 Core B 的缓存中都有
X,状态均为S。
-
这个案例展示了数据如何从独占 (E) 变为共享 (S)。
4.4.2 案例二:独占写入与无效化
承接案例一。
4. Core A 写 X (PrWr),例如 X = 5:
* A缓存命中,但状态为 S,不能直接写入。
* A发出 BusUpgr (或 BusRdX)。
* Core B 和 Core C 侦听到 BusUpgr。
* Core B:状态为 S,将其副本状态从 S 变为 I(无效化)。
* Core C:状态为 I,无动作。
* A收到无效化确认后,执行写入操作。
* 结果:Core A 缓存 X 状态为 M,值为 5。Core B 的缓存中 X 为 I。内存中 X 仍为 0(过时)。
这个案例展示了写共享数据时,如何通过无效化其他副本来获得独占权。
4.4.3 案例三:O状态的作用与数据提供
承接案例二。
5. Core C 读 X (PrRd):
* C缓存未命中(状态 I),发出 BusRd。
* Core A 侦听到 BusRd,状态为 M。
* 动作:Core A 必须响应,因为它拥有最新数据。它将数据 5 提供到总线上。同时,由于现在有另一个读者,A的状态从 M 转换为 O。
* 内存控制器可能也准备响应,但看到A提供了数据,则放弃。
* Core C 收到数据 5。
* 结果:Core A 状态为 O,Core C 状态为 S。数据 5 在A和C之间共享,但内存中仍是 0。A是“所有者”。
这个案例展示了 O 状态的诞生:一个被共享的脏数据。它优化了性能,避免了立即写回内存。
4.4.4 案例四:竞争条件与仲裁
-
Core B 写 X (PrWr),例如
X = 10:-
B缓存未命中(状态
I),发出BusRdX。 -
Core A 和 Core C 侦听到
BusRdX。-
Core A (状态
O):必须响应,提供最新数据5,并将其状态转换为I。 -
Core C (状态
S):将其状态转换为I。
-
-
Core B 收到数据
5,然后执行写入,将值覆盖为10。 -
结果:Core B 缓存
X状态为M,值为10。Core A 和 Core C 状态为I。
-
这个案例展示了在 O 状态存在时,写未命中如何工作。拥有 O 状态的缓存负责提供数据,然后和所有其他缓存一样被无效化。
本章小结:
本章我们深入剖析了MOESI协议的核心机制——状态转换。我们详细学习了由本地核心请求(读/写命中/未命中)和远端侦听请求(BusRd/BusRdX)所触发的各种状态转换路径、动作及其原理。通过完整的转换表和状态图,我们系统地构建了协议的全局视图。最后,通过四个循序渐进的典型案例,我们亲眼见证了MOESI协议如何在实际系统中优雅地维护数据一致性,并特别强调了 O 状态在优化共享脏数据处理上的关键作用。在下一章,我们将把视角从状态机提升到系统级,分析这些转换所依赖的具体事务类型和消息流。
第5章 事务类型与消息流
MOESI协议是一个分布式状态机,其运转依赖于缓存控制器之间、以及缓存与内存之间可靠的消息传递。本章将详细定义这些消息(事务),并通过时序图和流程图清晰地展示在不同场景下,消息是如何在系统中流动的,从而完成一致性的维护。
5.1 请求事务类型
这些事务通常由发起请求的缓存控制器(Requestor)在处理核心未命中或升级请求时发出。
5.1.1 BusRd (总线读)
-
目的:获取一个缓存行的只读副本。发起者意图读取数据,但不打算修改它。
-
触发条件:本地核心发生读未命中(状态为
I)。 -
期望结果:
-
从系统中获取数据。
-
将本地缓存行状态置为
S(如果系统中已有其他副本)或E(如果系统中无其他副本)。
-
-
对系统的影响:
-
其他缓存控制器侦听此请求。处于
M或O状态的缓存需要准备提供数据;处于E状态的缓存需要将其状态降级为S。
-
5.1.2 BusRdX (总线独占读)
-
目的:获取一个缓存行的独占的、可写的副本。发起者意图写入数据。
-
触发条件:
-
本地核心发生写未命中(状态为
I)。 -
本地核心发生写命中但状态为S/O(需要升级)。
-
-
期望结果:
-
从系统中获取数据(对于写未命中)或获得独占权(对于升级)。
-
无效化所有其他缓存中的副本。
-
将本地缓存行状态置为
M。
-
-
对系统的影响:
-
其他缓存控制器侦听此请求。任何持有有效副本(状态
M, O, E, S)的缓存都必须将其状态转换为I,并且处于M或O状态的缓存必须提供最新数据。
-
5.1.3 Upgrade (升级)
-
目的:将本地已有的只读副本(
S状态)升级为独占权,而无需获取数据本身。 -
触发条件:本地核心发生写命中且状态为
S。 -
期望结果:
-
无效化所有其他缓存中的副本。
-
将本地缓存行状态从
S升级为M。
-
-
对系统的影响:
-
与
BusRdX的无效化部分相同,但不引发数据传输(因为请求者已有数据)。这节省了带宽。
-
-
注意:有些协议实现可能不区分
BusRdX和Upgrade,对于所有写操作都使用BusRdX,但这在某些场景下(如从S状态升级)会带来不必要的数据传输。
5.1.4 Flush / Victim (回写/替换)
-
目的:将一个被修改过的(“脏的”)缓存行(状态
M或O)从缓存中驱逐出去,并将其最新内容写回下一级缓存或主内存。 -
触发条件:缓存需要为新数据腾出空间(缓存替换算法,如LRU,决定驱逐该行)。
-
期望结果:
-
确保脏数据被持久化到内存(或下一级共享缓存)。
-
本地缓存行状态变为
I。
-
-
对系统的影响:
-
增加了总线/网络流量。
-
更新内存中的数据,使其与最新副本一致。
-
5.2 响应事务类型
这些事务是对请求事务的回应,可以由其他缓存控制器或内存控制器发出。
5.2.1 数据响应
-
目的:提供所请求的缓存行数据。
-
数据来源:
-
内存:当没有缓存能提供数据时(所有副本都是
I或只有S状态的干净副本),或者作为最后的保障。 -
缓存:当某个缓存处于
M或O状态时,它拥有最新数据,有责任提供数据。这被称为 "缓存到缓存" 的传输 或 "干预",是降低访问延迟的关键优化。
-
-
响应方式:
-
在基于总线的系统中,数据被放到总线上,所有侦听者都能看到,但只有请求者会接收它。
-
在基于目录的点对点系统中,数据被直接发送给请求者。
-
5.2.2 确认响应
-
目的:通知请求者,某个操作(通常是无效化)已经完成。
-
典型应用:对于
BusRdX和Upgrade请求,收到无效化命令的缓存必须向请求者发送一个无效化确认。 -
重要性:请求者通常需要收集到所有潜在共享者的确认后,才能安全地完成状态转换并进行写入。这确保了在写入发生时,真的没有其他副本存在。
-
类型:
-
显式确认:每个被无效化的缓存单独发送一个确认消息。
-
隐式确认:通过总线协议或超时机制推断出无效化已完成(在简单的总线系统中常见)。
-
5.3 基于总线的消息流时序图
让我们通过具体的时序图,在基于总线侦听的系统中可视化上述事务的交互。
场景:Core A 写未命中,Core B 干预提供数据
初始状态:地址 X 在 Core B 的缓存中,状态为 M,值为 5。Core A 和 Core C 的缓存中 X 为 I。内存中 X 的值为 0(过时)。
Core A 执行 X = 10(写未命中)。
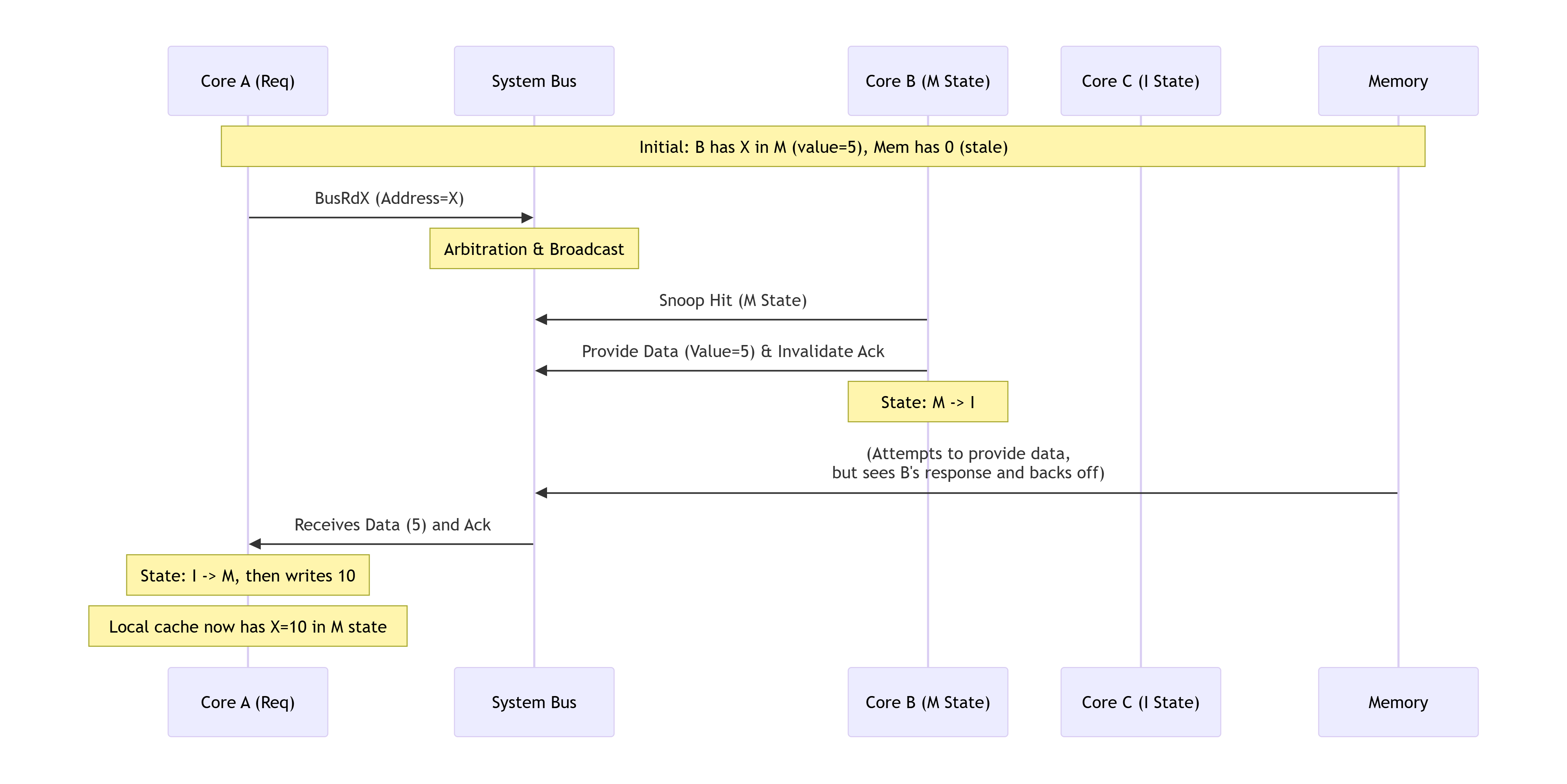
流程解析:
-
Core A 发出
BusRdX请求到总线。 -
所有核心(B, C)和内存控制器侦听到该请求。
-
Core B 侦听命中,发现自己处于
M状态。-
它必须提供数据,并将数据
5放到总线上。 -
同时,它将自己的副本状态从
M改为I,并发出无效化确认(在总线协议中,提供数据本身常被视为一种确认)。
-
-
内存控制器也侦听到请求,但看到有缓存提供了更新的数据,因此放弃响应。
-
Core A 收到数据和确认,将缓存行状态置为
M,并随后完成核心的写入操作,将值更新为10。 -
Core C 侦听到
BusRdX,但状态为I,无动作。
关键点:这个例子展示了 "缓存干预" ,脏数据直接从 Core B 的缓存传输到 Core A,避免了访问慢速内存,极大地降低了延迟。
5.4 基于点对点互联的消息流
在基于目录的系统中,消息流不再是广播,而是精准的点对点通信。我们以相同的场景为例。
初始状态:目录记录显示,地址 X 仅被 Core B 缓存,且处于 M 状态。
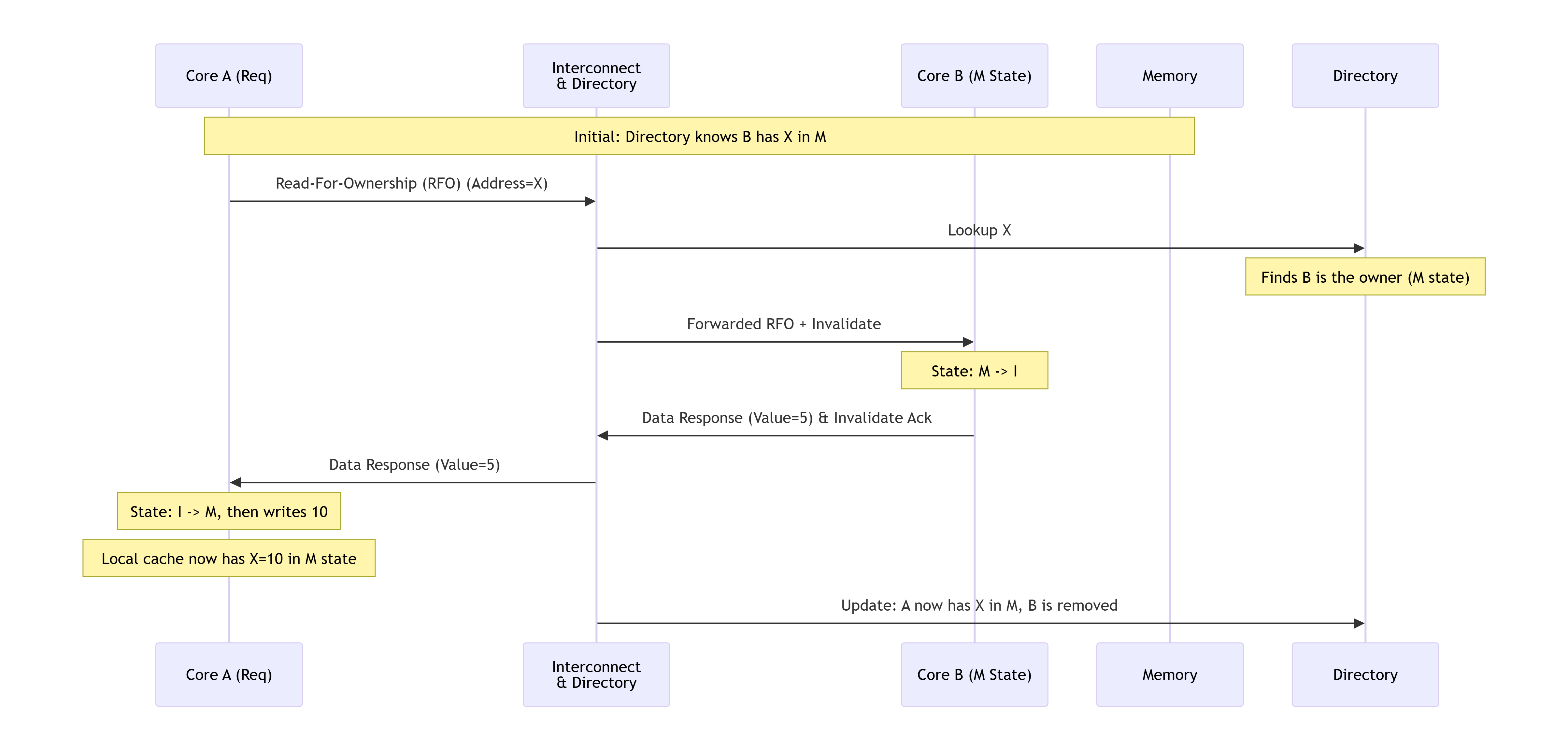
流程解析:
-
Core A 向互联网络发送一个
Read-For-Ownership请求(等同于BusRdX)。 -
请求被路由到目录。
-
目录查询其记录,发现 Core B 是
X的唯一所有者,状态为M。 -
目录不再广播,而是:
a. 向 Core B 发送一个点对点的消息,包含转发请求和无效化命令。
b. 同时,它可能会阻止内存响应。 -
Core B 收到消息后:
a. 将状态从M改为I。
b. 将数据5和无效化确认直接发送给 Core A(或通过目录转发)。 -
Core A 收到数据后,将状态置为
M并完成写入。 -
目录更新其记录,现在标记为 Core A 拥有
X,状态为M,并移除 Core B 的记录。
关键点:基于目录的协议将广播流量(O(N))转换为了点对点流量(O(1)),显著提升了系统的可扩展性。目录是系统的“交通指挥中心”,精准地管理着数据的归属和共享者集合。
本章小结:
本章我们将MOESI协议的行为具体化为了系统组件间的消息交互。我们详细定义了 BusRd, BusRdX, Upgrade, Flush 等核心请求事务,以及数据响应和确认响应。通过基于总线的时序图,我们直观地看到了经典的广播-侦听机制如何工作,特别是“缓存干预”这一关键优化。随后,通过基于目录的点对点消息流,我们揭示了现代大规模多核处理器是如何解决可扩展性问题的。理解这些消息流,对于后续的架构设计、性能分析和验证工作都至关重要。在下一章,我们将深入微架构层面,探讨如何将这些协议逻辑用硬件电路实现。
第6章 MOESI的微架构实现
将MOESI协议规范转化为实际可综合的硬件设计,是芯片研发中最具挑战性的任务之一。本章将深入探讨缓存控制器、侦听处理单元、互连网络协同设计等关键微架构模块,并介绍一系列提升性能和能效的优化技术。
6.1 缓存控制器设计
缓存控制器是MOESI协议的“大脑”,它附着在每一级私有缓存(如L1 D-Cache)上,负责处理来自CPU核心的请求和来自互联网络的侦听请求,并驱动状态转换。
6.1.1 状态位存储与管理
每个缓存行(Cache Line)的元数据(Tag Store)中,除了地址标签(Tag)外,还必须包含MOESI状态位。
-
状态编码:由于有5个状态,至少需要3位来进行编码。一种常见的编码方式是:
-
000- Invalid -
001- Shared -
010- Exclusive -
011- Owned -
100- Modified -
(其他编码组合可作为保留或用于调试)
-
-
并发访问与原子性:缓存控制器必须能够原子性地(atomic)更新状态位。这意味着在处理一个请求时,需要防止其他请求(如同时到来的核心访问和侦听请求)对同一缓存行的状态进行破坏性更新。这通常通过为每个缓存行或每个Cache Set设置锁(Lock) 或状态机仲裁来实现。
-
面积与功耗考量:这些额外的状态位增加了缓存标签阵列的面积和静态功耗。在设计大规模共享缓存(L3)时,这是一个重要的权衡因素。
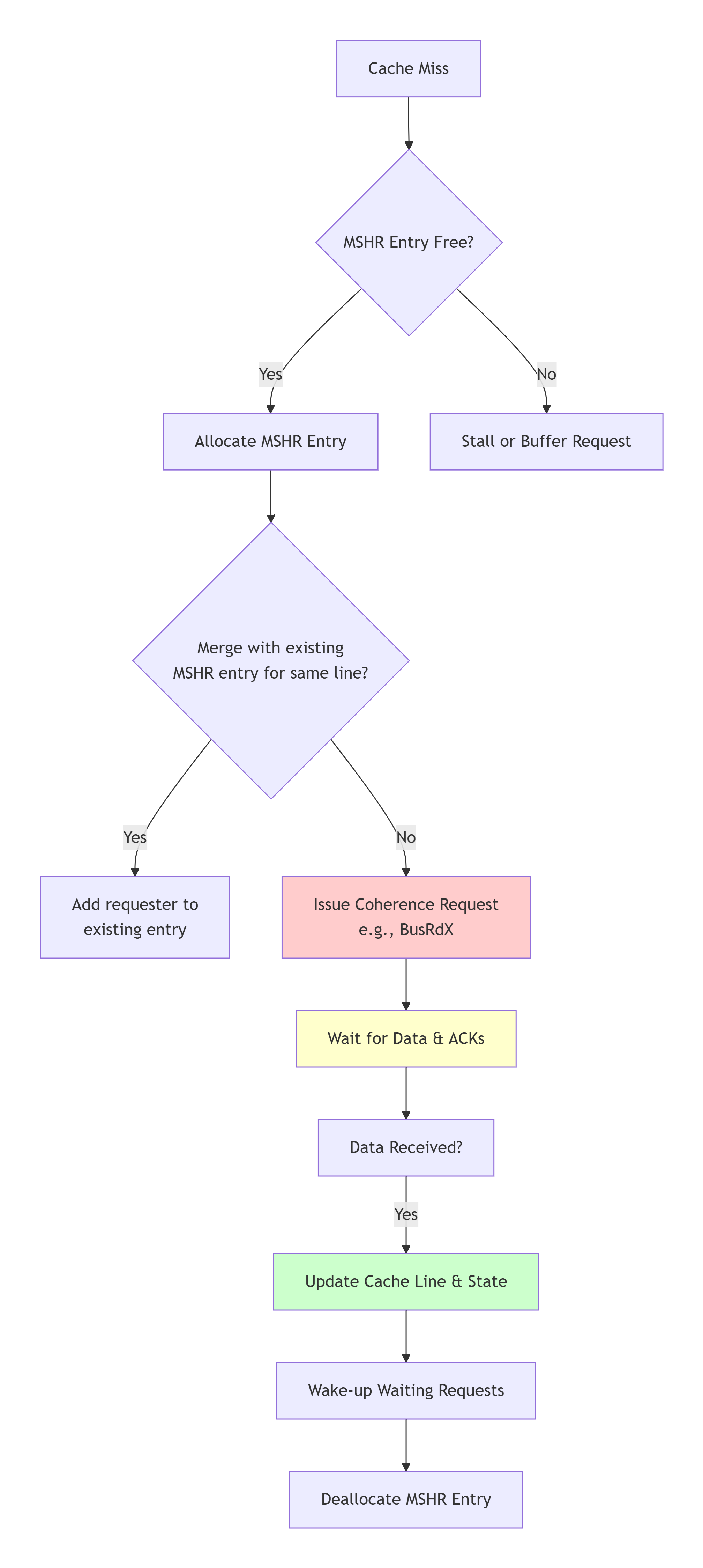
6.1.2 未命中处理逻辑
当发生缓存未命中时,缓存控制器会启动一个复杂的未命中处理流程。现代处理器通常使用 MSHR 来高效管理这些未命中。
-
MSHR:未命中状态保持寄存器。它是一个小型缓存,用于跟踪所有正在进行中的未命中请求。
-
MSHR的工作流程:
-
分配:当发生读或写未命中时,控制器检查MSHR是否有空闲条目。如果有,则分配一个,记录请求的地址、类型、目标核心等。
-
合并:如果在同一个缓存行的未命中请求完成之前,又来了一个新的对同一行的未命中请求,MSHR可以将这个新请求合并到现有条目中,避免重复发出总线事务。这对于利用访问的时空局部性、减轻互联网络压力至关重要。
-
发出请求:控制器根据请求类型(读/写)和当前已知的系统状态(如果有的话),向互联网络发出
BusRd或BusRdX事务。 -
等待与收集:MSHR条目等待来自系统其他部分的响应(数据和确认)。对于需要无效化多个副本的请求,它需要收集足够数量的确认。
-
唤醒:当所有数据和确认都收到后,MSHR条目被标记为完成。缓存行被填充,状态被更新,所有等待该数据的核心请求被唤醒并获得数据。
-
6.1.3 侦听过滤器
在基于侦听的协议中,每个缓存控制器必须检查每一个在总线上传播的请求,这被称为“全相联侦听”,功耗和复杂度很高。侦听过滤器 是一种优化技术,用于快速判断一个外部请求是否与本地缓存相关,从而决定是否需要访问庞大的标签阵列。
-
工作原理:维护一个比完整标签阵列小得多的结构,用于快速判断“某个地址肯定不在本缓存中”。
-
常见实现:
-
稀疏目录:一种常见形式。它为整个缓存维护一个简化的目录,只记录哪些地址可能在缓存中。如果过滤器显示“不在”,则无需访问主标签阵列,节省了功耗。
-
布隆过滤器:使用多个哈希函数将地址映射到一个位向量中。它可能有误报(即过滤器说“可能在”,但实际不在),但绝不会有漏报(即过滤器说“肯定不在”,那就一定不在)。对于“肯定不在”的情况,可以安全地跳过侦听处理。
-
-
价值:在大规模多核系统中,侦听过滤器能显著降低由无效侦听访问引起的动态功耗。
6.2 侦听处理单元
这是缓存控制器中专门处理来自互联网络请求的模块。
6.2.1 侦听队列
为了避免在处理一个侦听请求时阻塞后续的请求,缓存控制器会使用一个 侦听队列。
-
作用:将到达的侦听请求进行缓冲,使其能够被异步、流水线化地处理。
-
设计挑战:
-
队列深度:需要足够深以吸收请求突发,防止互联网络背压。
-
优先级:侦听请求与核心本地访问请求会竞争标签阵列的访问权。通常需要设计仲裁逻辑。在某些情况下,处理侦听请求的优先级可能更高,以防止整个系统死锁。
-
依赖处理:如果侦听队列中的某个请求与一个正在由MSHR处理的未命中请求地址相同,则需要等待MSHR处理完成后再处理该侦听请求,以避免状态机出现竞态条件。
-
6.2.2 一致性与内存顺序冲突处理
这是实现中最复杂的部分之一。
-
冲突场景:当一个来自核心的本地访问(如写回退)与一个侦听到的无效化请求同时针对同一缓存行时,就会发生冲突。
-
解决方案:需要精细的锁机制和排序规则。
-
缓存行锁:在处理任何可能改变缓存行状态的操作(无论是本地请求还是侦听请求)时,先获取该缓存行的“锁”。这确保了状态的原子性更新。
-
内存顺序模型:硬件必须遵守目标架构的内存模型(如x86-TSO, RISC-V RVWMO)。例如,在x86中,写操作是全局有序的。这意味着,对于同一个核心发出的两个写操作
W1和W2,所有其他核心都必须以相同的顺序观察到它们。这要求无效化请求的发出和完成必须遵循严格的顺序。
-
6.3 互连网络设计对MOESI的影响
互联网络不仅是通信通道,其特性也深刻影响着MOESI协议的实现和性能。
6.3.1 有序与无序网络
-
有序网络(如总线):
-
优点:天然提供了全局有序的通信媒介,简化了一致性协议的设计。所有缓存控制器以相同的顺序观察到所有请求,避免了复杂的排序逻辑。
-
缺点:可扩展性差,成为性能瓶颈。
-
-
无序网络(如Mesh):
-
挑战:请求和响应可能通过不同路径,以乱序到达。这可能导致死锁、活锁和一致性违反。
-
解决方案:
-
虚拟网络:将不同类型的流量(如请求、响应、无效化)分配到逻辑上独立的虚拟网络中,每个网络有独立的缓冲区和路由资源,从而打破资源依赖引起的死锁。
-
端到端确认/排序协议:在协议层增加序列号、确认和重传机制,确保逻辑上的顺序。
-
-
6.3.2 延迟与带宽考量
-
延迟:MOESI协议中关键操作的延迟(如
BusRdX从发出到收到所有确认的时间)直接影响到写操作的延迟。低延迟的互联网络(如高时钟频率的Ring或低直径的Mesh)对性能至关重要。 -
带宽:在多核工作负载下,一致性通信会产生巨大的带宽需求。例如,“共享-写”型工作负载会产生大量
Upgrade和无效化流量。互联网络必须提供足够的对分带宽以避免成为系统瓶颈。
6.4 优化技术
除了上述基本结构,工业级设计还包含大量优化技术以提升性能和能效。
6.4.1 静默降级
-
概念:当一个缓存行从
E状态降级到S状态时,或者从M状态降级到O状态时,由于数据仍然是有效的(并且对于E->S,数据是干净的),不需要通知任何其他组件(如目录或内存)。这种不需要向外发送消息的状态降级称为“静默降级”。 -
价值:减少了不必要的网络流量和控制器功耗。
6.4.2 预取与一致性
-
问题:硬件预取器会预测核心未来需要的数据并将其提前加载到缓存中。但如果预取的是共享数据,并且以
E状态缓存,当其他核心后来真的写入该数据时,会触发不必要的无效化和BusRdX流量。 -
解决方案:
-
预取提示:提供ISA支持,让软件或预取器可以标记预取数据是“只读”的还是“即将写入”的。对于只读预取,可以主动以
S状态获取;对于写预取,则以E状态获取。 -
非一致性预取:预取的数据被标记为“临时”状态,不参与一致性协议,直到被核心实际访问。这避免了污染全局状态。
-
6.4.3 写合并缓冲区
-
概念:对于短时间内核心对同一缓存行进行的多次写入,缓存控制器可以将其在缓冲区中合并,最终只产生一次一致性事务。
-
工作流程:
-
核心第一次写入未命中,发出
BusRdX,但数据返回后不立即写入缓存。 -
后续对同一缓存行的写入被导向一个小的、高速的写合并缓冲区。
-
当缓冲区满、或遇到屏障指令、或核心需要读取该行时,再将合并后的最终结果一次性写回到缓存中。
-
-
价值:
-
显著减少了一致性事务的数量。
-
将多次对缓存阵列的写入转化为一次,节省了动态功耗。
-
-
挑战:增加了微架构的复杂性,并需要处理与侦听请求的交互(如果收到对该行的侦听请求,必须首先将缓冲区内容写回,以保证数据一致性)。
本章小结:
本章我们揭开了MOESI协议硬件实现的神秘面纱。我们看到了状态位如何被编码和存储,MSHR如何高效管理未命中,以及侦听过滤器和队列如何优化功耗和性能。我们探讨了处理核心访问与侦听请求冲突的复杂性,以及互连网络的有序/无序特性对协议设计的深远影响。最后,我们介绍了几种关键的微架构优化技术。理解这些实现细节,是设计高性能、高能效、高可靠多核处理器的基石。在下一章中,我们将视角从单个芯片扩展出去,探讨如何将MOESI协议的思想应用于超大规模的多核系统——基于目录的一致性协议。
第7章 基于目录的MOESI协议
随着处理器核心数量的不断增加,基于总线侦听的MOESI协议面临着根本性的挑战。广播通信方式成为系统的性能和功耗瓶颈。基于目录的协议通过将广播流量转换为精准的点对点流量,成功地解决了这一可扩展性问题。本章将深入解析目录协议的原理、结构和实现。
7.1 可扩展性问题与侦听的局限
在侦听协议中,每个一致性请求(如 BusRdX)都需要广播到系统中所有其他的缓存控制器。这带来了几个严重问题:
-
带宽瓶颈:一致性通信所需的总带宽随核心数 N 的增加而呈 O(N) 增长。共享的互联媒介(如总线)无法支撑数十上百个核心的通信需求。
-
可扩展性墙:广播本身是一个串行化过程。随着核心数增加,仲裁延迟和广播传播延迟都会显著增加,限制了系统规模的扩大。
-
功耗问题:每个一致性请求都导致 *N-1* 个缓存控制器去访问它们的标签阵列进行侦听检查,产生了巨大的动态功耗。大部分侦听检查的结果是“未命中”,这是一种能源浪费。
结论:对于超过约8-16个核心的系统,基于广播的侦听协议不再适用。必须采用一种能够将通信流量与核心数解耦的机制。
7.2 目录的结构与设计
基于目录协议的核心思想是:为系统中被缓存的数据维护一个集中的“通讯录”(即目录),记录每一行数据被哪些核心缓存了。当一个核心需要修改数据时,它只需查询目录,然后由目录精准地通知那些持有副本的核心,而非广播给所有人。
目录通常与最后一级共享缓存(如L3 Cache)的各个切片(Slice)相关联,或者是一个独立的结构。
7.2.1 全映射目录
这是最直接但成本最高的目录设计。
-
结构:对于每一个物理内存地址(对应一个缓存行),目录都维护一个长度为 N 的位向量(Bit Vector),其中 N 是系统中处理器核心的数量。
-
位向量中的第 *i* 位为
1,表示核心 *i* 缓存了该数据的副本。 -
通常还会包含几个状态位,用于记录该缓存行的全局状态(如:未缓存、共享、独占)。
-
-
工作方式:
-
读未命中:目录收到请求,检查位向量。如果没有其他缓存者,则将状态置为共享,置位请求核心的位,并从内存提供数据。如果已有其他缓存者,则同样置位请求核心的位,并从内存(或某个缓存)提供数据。
-
写未命中/升级:目录收到请求,检查位向量。向所有位向量中被置位的核心发送点对点的“无效化”消息。等待所有核心回复确认后,再将请求核心的位向量置为独占(并清除其他所有位),并授权其写入。
-
-
优点:精确知道每一个共享者,无效化消息最少。
-
缺点:存储开销巨大。存储开销与(内存容量 × 核心数)成正比。例如,一个64核CPU,64GB内存,缓存行64B,目录项开销为 64 bits/line。那么目录存储开销为:
(64 GB / 64 B) * 64 bits = 64 Gb = 8 GB!这本身就是一个巨大的片上SRAM,成本无法接受。
7.2.2 有限指针目录
为了克服全映射目录的存储爆炸问题,有限指针目录被提出。
-
核心思想:假设在大多数情况下,一个缓存行不会被系统中所有核心共享,而只被少数几个核心共享。因此,可以为每个目录项分配固定数量的指针(如 4、8 个),而不是一个完整的位向量。
-
结构:每个目录项包含:
-
少量(K 个)核心ID指针。
-
一个状态位,指示当前是“未缓存”、“共享”(指针数 <= K)还是“独占”。
-
当处于共享状态且共享者数量超过 K 时,目录会进入一个特殊的 “广播” 状态。
-
-
工作方式:
-
当共享者数量不超过 K 时,工作方式与全映射目录类似,目录只向指针列表中的核心发送消息。
-
当一个新的读请求到来,且指针已满(共享者数 = K)时,目录项进入“广播”状态。此后,对于任何写请求,目录将退化为广播无效化给所有核心,就像侦听协议一样。
-
-
优点:大幅降低了存储开销。存储开销与(内存容量 × 指针数 * log2(N))成正比。
-
缺点:在共享者很多的工作负载(如高频共享计数器)下,会退化为性能较低的广播模式。
7.2.3 稀疏目录
这是现代处理器中最常用的一种折中方案,它认识到一个关键点:目录无需为所有可能的内存地址都保留条目,只需为那些当前确实被缓存了的地址保留条目即可。
-
核心思想:将目录组织成一个与共享缓存(LLC)分离的、容量小得多的全相联或组相联缓存。这个目录缓存只保存那些至少在一个私有缓存中有副本的缓存行的信息。
-
结构:稀疏目录本质上是一个内容寻址的存储器。
-
Tag:物理地址的一部分。
-
Data:共享者信息(可以是位向量或有限指针)和状态。
-
-
工作方式:
-
当一个核心发生缓存未命中,请求到达LLC和目录。
-
在LLC中查找数据。
-
在稀疏目录中查找该地址的条目。
-
如果目录命中,说明该行已被其他核心缓存。目录根据其记录的共享者信息发送无效化消息。
-
如果目录未命中,说明没有其他核心缓存该行。目录可以分配一个新条目来记录这个新的缓存者。
-
-
-
溢出处理:当稀疏目录已满,而需要分配新条目时,需要驱逐一个旧条目。驱逐一个目录条目意味着隐式地无效化该条目所记录的所有远程缓存副本。这通常通过向那些共享者发送“强制无效化”消息来完成。
-
优点:
-
存储开销与核心的“工作集”(即被缓存的远程副本数量)成正比,而不是与总内存容量成正比,开销可控。
-
避免了全映射目录的巨额静态功耗。
-
-
缺点:
-
目录未命中处理逻辑复杂。
-
溢出处理会引入额外的延迟和一致性流量。
-
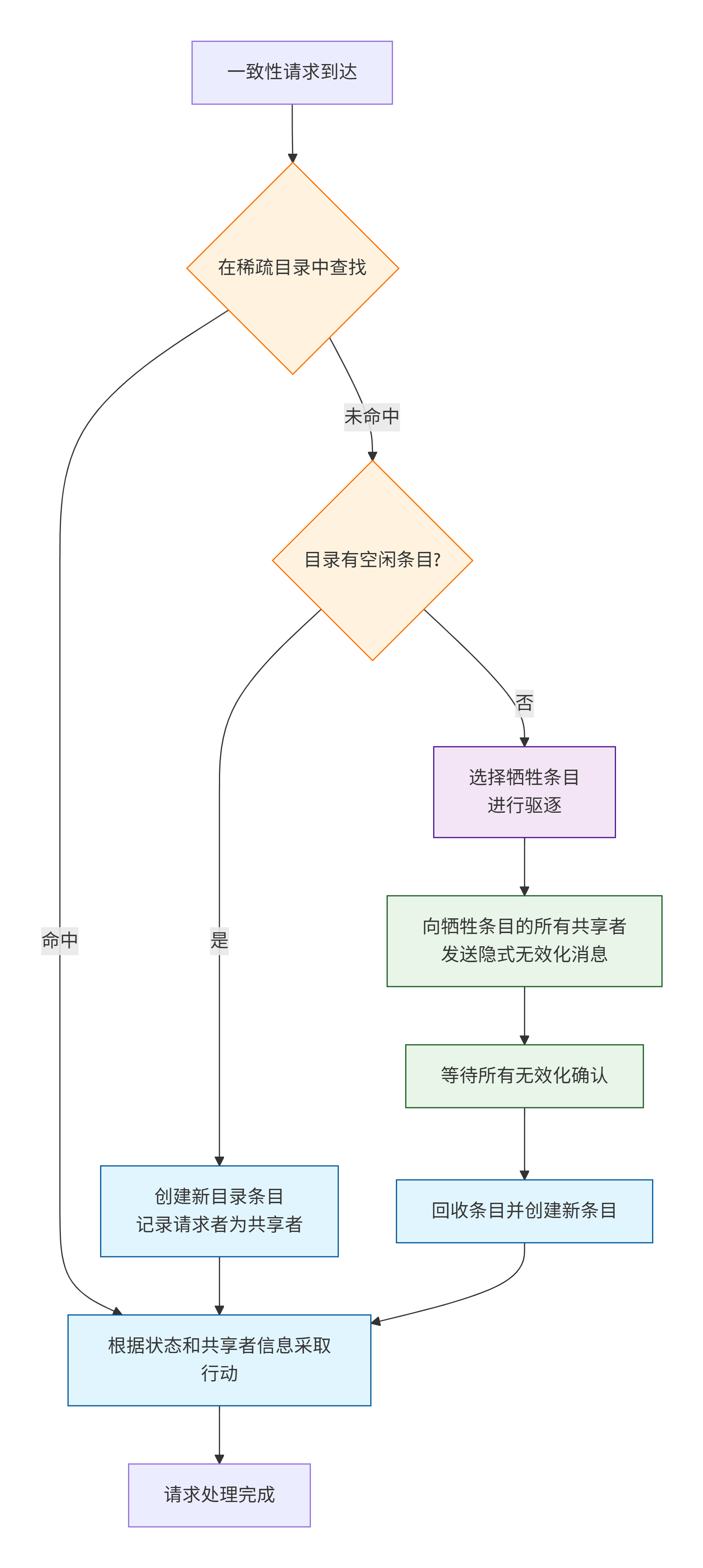
7.3 基于目录的协议流程
让我们以MOESI状态为基础,描述在基于目录的系统中,典型的读/写未命中是如何处理的。我们假设目录使用位向量或等效机制。
7.3.1 读未命中处理
-
请求阶段:核心 Ci 发生读未命中,向其本地L1缓存发出
PrRd。L1缓存控制器向目录(通常通过LLC)发送一个Read请求。 -
目录查询:目录收到
Read请求,查找对应地址的目录项。-
情况A:状态为“未缓存”或“独占”(但独占者是其他核心)
-
目录将状态更新为“共享”。
-
在共享者位向量中设置核心 Ci 的位。
-
如果数据在LLC中是干净的,目录指示LLC将数据返回给 Ci。
-
如果状态是“独占”(其他核心 Cj 持有),目录会向 Cj 发送一个“降级”消息,要求其将状态从
E变为S或O,并提供数据。数据由 Cj 直接发给 Ci(或通过目录转发),同时目录更新共享者信息。
-
-
情况B:状态为“共享”
-
目录只需在共享者位向量中设置核心 Ci 的位。
-
数据可以从LLC或任何一个已有副本的核心提供。
-
-
-
完成:核心 Ci 收到数据,将其缓存行状态置为
S。
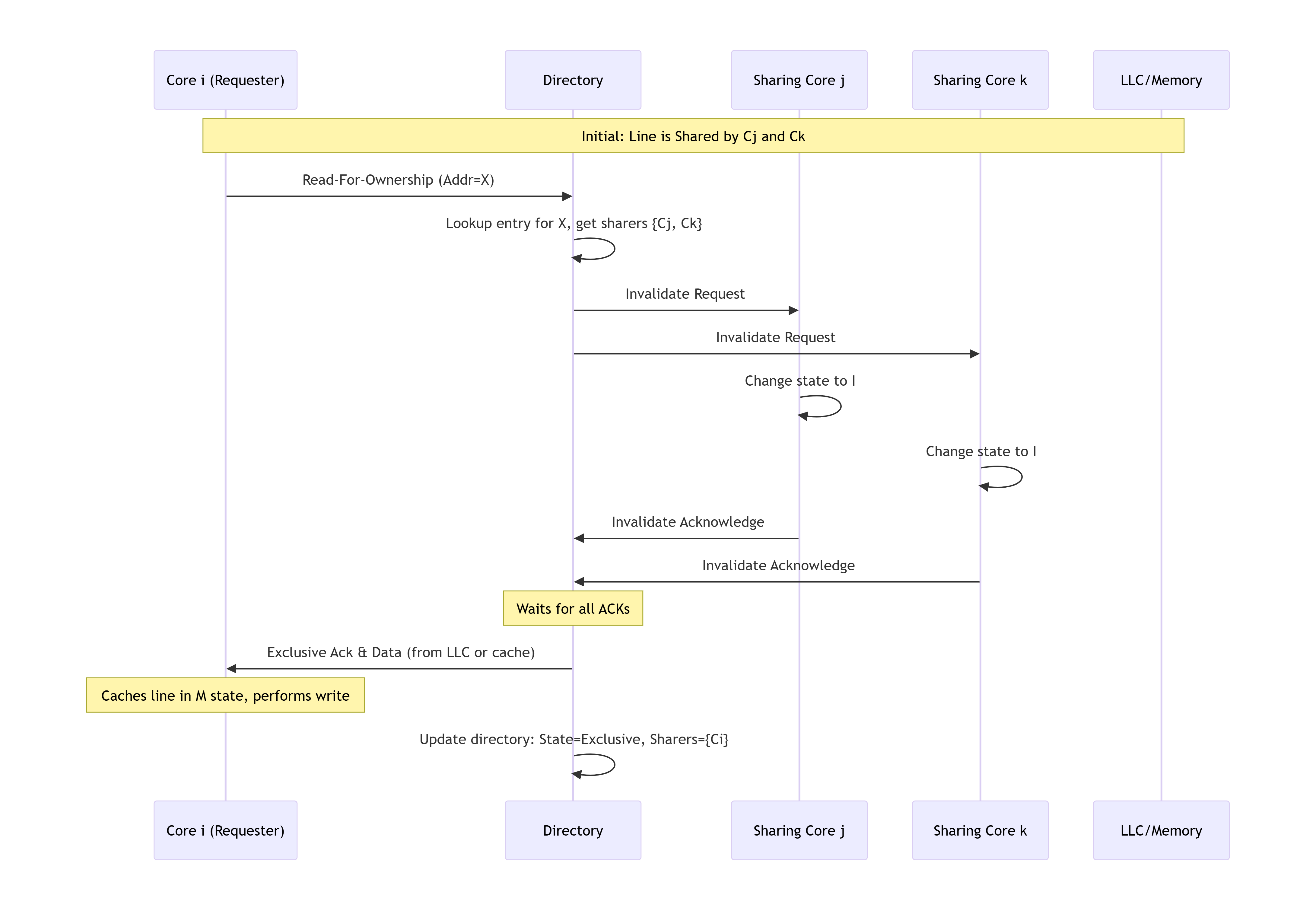
7.3.2 写未命中/升级处理
-
请求阶段:核心 Ci 发生写未命中(或对
S状态行进行写命中),向目录发送Read-For-Ownership (RFO)请求。 -
目录查询与无效化:目录收到
RFO请求,查找目录项。-
目录动作:
-
目录将状态更新为“独占”。
-
它读取当前的共享者位向量。
-
向位向量中所有被置位的核心(除了请求者 Ci,如果有的话)发送“无效化”消息。
-
目录清空位向量,然后只设置核心 Ci 的位。
-
-
共享者动作:每个收到无效化消息的核心,将其本地副本状态置为
I,并回复一个“无效化确认”给目录或请求者。
-
-
收集确认:目录(或请求者 Ci)需要等待所有被通知的核心的确认。
-
授权与完成:当所有确认收到后,目录向核心 Ci 发送“独占授权”消息(可能随数据一起)。Ci 收到后,将缓存行状态置为
M,并完成写入操作。
7.4 与侦听协议的对比与混合方案
| 特性 | 基于侦听的MOESI | 基于目录的MOESI |
|---|---|---|
| 可扩展性 | 差 (通常 ≤ 16 cores) | 优秀 (可达数百/数千 cores) |
| 通信方式 | 广播 | 点对点 |
| 带宽需求 | 高 (O(N) 广播流量) | 低 (O(1) 或 O(共享者数) 流量) |
| 存储开销 | 低 (仅每个缓存行的状态位) | 高 (需要额外的目录存储) |
| 实现复杂度 | 相对简单 (总线仲裁,全相联侦听) | 复杂 (目录一致性,点对点网络,死锁避免) |
| 最佳场景 | 小规模、低核心数CMP,嵌入式系统 | 大规模多核/众核,服务器CPU |
混合协议:
在实际设计中,有时会采用混合方法。例如,在一个多芯片模块(MCM)或单路服务器中:
-
片内:使用基于目录的协议,因为核心数量多。
-
片间(插槽间):使用基于侦听的协议(如通过快速互联QPI/UPI),因为插槽数量少(2-8个),广播开销可控。
这种混合方案在实现复杂度和性能之间取得了良好的平衡。
本章小结:
本章我们系统地学习了基于目录的MOESI协议,这是构建大规模可扩展多核系统的基石。我们分析了侦听协议的局限性,并详细介绍了三种主要的目录结构:全映射(精确但昂贵)、有限指针(折中)、稀疏目录(实用且高效)。我们一步步剖析了在目录协议下的读/写请求处理流程,清晰地展示了点对点无效化是如何取代广播的。最后,我们对比了侦听与目录协议的优劣,并简要介绍了混合方案。理解基于目录的一致性,是驾驭现代数据中心CPU和高性能计算芯片架构的关键。在下一章,我们将探讨MOESI协议在更复杂场景下的应用与变种。
第8章 高级主题与变种
MOESI协议虽然强大,但在面对现代处理器架构的复杂性时,需要进一步的扩展和调整。本章将深入探讨这些高级主题,展示MOESI协议如何适应并服务于最前沿的计算需求。
8.1 多级缓存层次中的MOESI
现代处理器拥有复杂的多级缓存 hierarchy(如L1、L2、L3)。如何在这一 hierarchy 中高效地维护MOESI协议是一个关键问题。
8.1.1 包含性与非包含性策略
缓存层次之间的关系策略,深刻影响了一致性协议的设计和效率。
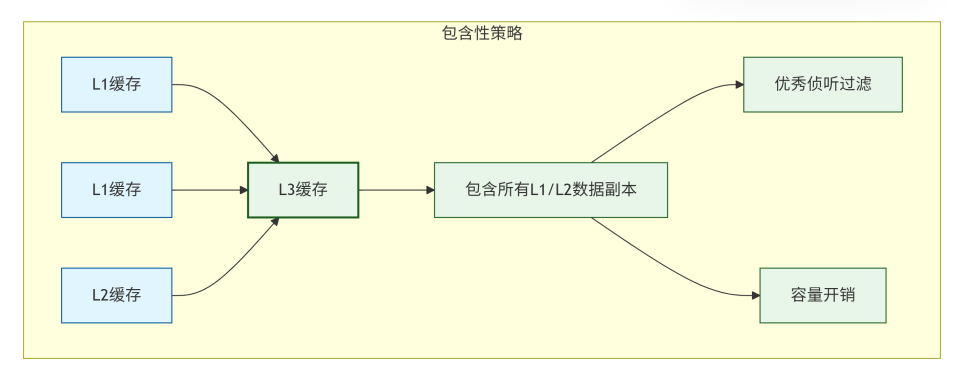
-
包含性策略:
-
定义:上一级缓存(如L2)中包含的数据,也必然存在于下一级缓存(如L3)中。即
L1 ⊆ L2 ⊆ L3。 -
对MOESI的优势:
-
高效的侦听过滤:L3缓存可以作为整个芯片的“侦听过滤器”。一个外部侦听请求首先到达L3。如果L3中没有该数据的副本,则可以确定所有L1/L2缓存中也没有,从而无需打扰各个核心。这极大地减少了不必要的侦听流量和功耗。
-
简化目录实现:在基于目录的协议中,与L3关联的目录可以准确反映所有核心的缓存情况,因为所有被缓存的数据都在L3中有副本。
-
-
缺点:容量浪费。L3缓存中保存了大量可能在L1/L2中也存在的副本,导致有效缓存容量降低。
-
MOESI实现:每一级缓存都维护自己的MOESI状态。当L1缓存一个行时,其对应的L2和L3中的该行状态会相应变化(例如,从
I变为S或E)。
-
-
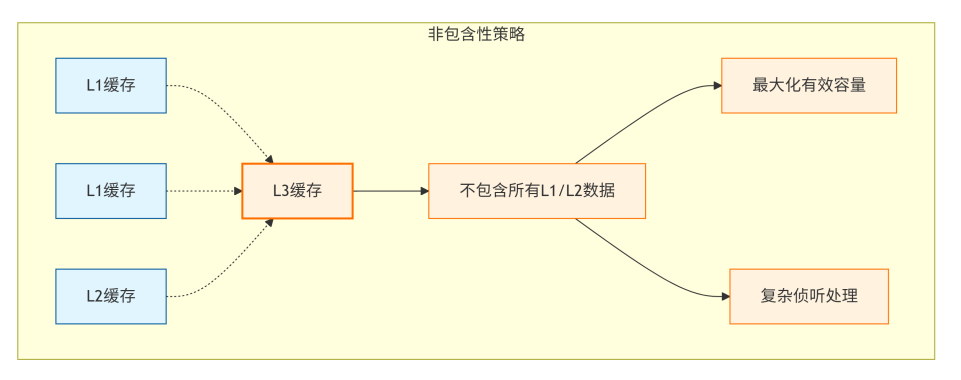
非包含性策略:
-
定义:各级缓存之间没有严格的包含关系。L3中可能不包含某些L1/L2中独有的数据。
-
优点:最大化有效缓存容量。避免了重复存储,使得整个缓存 hierarchy 的总有效容量接近各级缓存容量之和。
-
缺点:
-
侦听复杂:无法用L3作为简单的过滤器。一个L3未命中的侦听请求,仍然必须广播到所有L1/L2缓存,因为数据可能存在于其中任何一个。这增加了侦听延迟和功耗。
-
目录复杂:目录必须直接跟踪所有L1缓存的状态,因为L3不再拥有所有数据的副本。
-
-
MOESI实现:更为复杂,需要协议确保即使数据不在L3中,也能在L1/L2之间正确维护一致性。通常需要更精细的目录结构或广播机制。
-
-
非独占性策略:一种折中方案。允许数据存在于多级缓存中,但当L1缓存一个数据时,会驱逐L2中对应的数据。这试图在包含性和非包含性之间取得平衡。
8.1.2 L2/L3缓存的角色
在多层结构中,中间级缓存(如L2)和最后级缓存(LLC,如L3)扮演着特殊角色。
-
L2缓存(通常是私有的或共享的):
-
MOESI状态维护:L2为其每个缓存行维护MOESI状态。这个状态可能与对应L1缓存中的状态不同。
-
请求聚合:如果多个L1缓存未命中指向同一个L2行,L2的MSHR可以合并这些请求,只向L3/目录发起一次一致性事务。
-
写回缓冲区:当L1中一个脏行(
M或O状态)被替换时,它首先被写回到L2。L2负责处理将这个更新进一步传播到L3或其它核心的复杂性。
-
-
L3缓存(通常是共享的):
-
系统的锚点:L3是片上所有一致性流量的枢纽。在包含性系统中,它是全局状态的权威来源。
-
数据提供者:在基于目录的协议中,L3(或其关联的目录)是协调所有一致性操作的中心。
-
“拥有者”的默认角色:在MOESI中,当没有缓存处于
M或O状态时,L3通常是干净数据的“拥有者”,负责响应数据请求。当有缓存处于O状态时,L3的数据可能是过时的。
-
8.2 异构系统中的一致性
传统的MOESI协议是为同构多核CPU设计的。然而,现代SoC集成了多种计算单元,如GPU、AI加速器、DSP等,形成了异构计算系统。将这些单元纳入统一的一致性域是巨大的挑战和机遇。
8.2.1 CPU与GPU的一致性
历史上,CPU和GPU拥有独立的内存空间,通过显式拷贝(如DMA)来交换数据,开销巨大。现代架构趋势是实现CPU-GPU一致性。
-
挑战:
-
不同的访问模式:GPU是大规模并行架构,有成千上万个线程,对缓存一致性的规模和带宽要求远超CPU。
-
不同的内存模型:GPU传统上使用更弱的内存模型,对一致性要求不如CPU严格。
-
I/O Coherence:GPU通常通过PCIe总线与CPU连接,而PCIe本身不支持缓存一致性。
-
-
解决方案:
-
硬件支持的统一内存:CPU和GPU共享同一个物理地址空间。硬件自动管理数据迁移和一致性。
-
AMD的hUMA:CPU和GPU集成在同一芯片上,共享最后一级缓存和内存控制器,使用扩展的MOESI类协议维护一致性。
-
NVIDIA的NVLink-C2C:通过高速NVLink互联,并采用基于目录的协议,将CPU和GPU纳入同一个一致性域。
-
-
GPU对MOESI的适应:
-
缩放协议:GPU的缓存层次(L1$ per CU, L2$ shared)也需要维护MOESI状态。但由于核心数极多,通常采用高度可扩展的基于目录的协议。
-
区域一致性:有时为了性能,会为GPU定义特定内存区域,在这些区域内使用更弱的一致性模型,以减少协议开销。
-
-
8.2.2 IO设备与DMA的一致性
IO设备(如网卡、存储控制器)通过DMA直接访问内存,这也会引入一致性问题。
-
问题描述:当CPU缓存了某个数据(状态为
M),而IO设备要读取该数据进行DMA操作时,如果IO系统不感知CPU缓存,它会直接从内存读取过时的数据。反之,当IO设备通过DMA写入数据后,CPU可能从其缓存中读取到过时的数据。 -
传统解决方案(软件维护):
-
在启动DMA读取之前,CPU驱动程序必须先将脏缓存行写回内存(
Flush)。 -
在完成DMA写入之后,CPU需要无效化其缓存中对应的行,迫使下次读取时从内存获取新数据。
-
缺点:软件开销大,且容易出错。
-
-
现代解决方案(硬件IO一致性):
-
IOMMU/SMMU:IO内存管理单元。它类似于CPU的MMU,但为IO设备服务。
-
与一致性协议集成:当IO设备发起DMA访问时,IOMMU会查询CPU的一致性协议(如通过侦听或查询目录)。
-
对于DMA读:如果数据在某个CPU缓存中是脏的(
M状态),一致性协议会拦截该请求,并将最新的数据从缓存提供给IO设备(或先写回内存再提供)。 -
对于DMA写:IOMMU会向CPU缓存发送无效化消息,确保后续CPU读取能获得DMA写入的新数据。
-
-
效果:对软件透明,实现了CPU和IO设备之间的自动缓存一致性,简化了编程,提升了性能。ARM的CCIX和CXL等先进互联协议都支持这种特性。
-
8.3 MOESI与其他一致性模型的结合
MOESI协议主要解决的是多副本的单一地址问题(缓存一致性)。它需要与更广义的内存一致性模型协同工作。
8.3.1 与TSO(全存储排序)的交互
x86架构采用TSO内存模型。
-
TSO的核心规则:在单个核心上,写操作的顺序对所有其他核心可见的顺序,与程序顺序一致。但允许读操作提前到写操作之前(Store-Load重排序)。
-
对MOESI实现的影响:
-
写缓冲区:为了实现TSO,每个核心都有一个写缓冲区。核心可以将写操作放入写缓冲区后立即继续执行,而无需等待写操作在全局可见。
-
协议复杂性:MOESI协议必须与写缓冲区协同工作。当一个核心的写操作还在缓冲区中时,如果收到对同一地址的侦听无效化请求,处理起来非常复杂。通常需要将写缓冲区中的相关条目与侦听请求进行匹配,并确保全局写顺序。
-
内存屏障:在需要更强顺序的地方(如
MFENCE指令),硬件必须清空写缓冲区,并等待所有正在进行的写操作在全局可见(即,相关的无效化确认已全部收到)之后,才能执行屏障后的指令。MOESI协议的确认机制是实现这些屏障的基础。
-
8.3.2 与弱内存模型(如RISC-V RVWMO)的交互
RISC-V等架构采用了更弱的内存模型(Weak Memory Ordering, WMO)。
-
弱内存模型的特点:硬件和编译器可以对内存操作进行大量的重排序,以最大化性能。只有在显式使用内存屏障(FENCE)时,才会保证操作的顺序。
-
对MOESI实现的机遇与挑战:
-
机遇:协议实现可以更灵活。例如,它可以批量处理多个无效化请求,或者延迟响应某些请求,只要最终结果符合弱内存模型的规则即可。这可以减少流水线停顿,提升性能。
-
挑战:验证极其困难。由于可能的操作顺序组合爆炸式增长,证明协议在所有情况下都符合弱内存模型的定义是一个巨大的挑战,严重依赖于形式化验证方法。
-
MOESI的角色不变:尽管内存模型是“弱”的,但缓存一致性(即对单个地址的读写语义)必须是“强”的。MOESI协议确保了对单个地址的读写,仍然遵循“写最终对所有读者可见”以及“对同一地址的写操作有全局顺序”这些基本不变性。弱内存模型主要约束的是不同地址的操作之间的顺序。
-
本章小结:
本章我们将MOESI协议的应用场景推向了更广阔的边界。我们探讨了在多级缓存中,包含性策略如何优化侦听,而非包含性策略如何最大化容量。我们深入分析了将MOESI扩展到异构系统的挑战,特别是CPU-GPU一致性和硬件IO一致性的实现原理。最后,我们厘清了MOESI协议(解决缓存一致性)与内存一致性模型(如TSO和RVWMO,解决操作顺序)之间的关系和交互。理解这些高级主题,对于架构师设计下一代复杂SoC,以及对于软件开发者在异构平台上编写高性能、正确的并发程序,都具有至关重要的意义。在接下来的章节中,我们的焦点将从设计转向验证,探讨如何确保如此复杂的协议在实现中是正确无误的。
第9章 MOESI协议的验证策略
验证缓存一致性协议是芯片验证中最具挑战性的任务之一。其复杂性来源于协议的并发性、状态空间的庞大以及微架构实现细节的多样性。本章将围绕如何构建一个完整的验证环境,如何生成有效的测试场景,以及如何应用形式化验证等高级技术来确保协议的正确性。
9.1 验证的挑战与复杂性
验证MOESI协议面临以下主要挑战:
-
状态空间爆炸:考虑一个具有N个核心的系统,每个缓存行有5种状态,理论上仅缓存行状态组合就有5^N种。再乘以内存地址空间、可能的操作序列和时序变化,状态空间变得无比庞大,无法通过穷举测试覆盖。
-
并发与竞态条件:多个核心同时发起请求,同时处理侦听请求,这些操作以任意顺序交错执行,容易产生难以复现的竞态条件。一个在单核测试中工作完美的设计,在多核并发场景下可能出现微妙错误。
-
微架构实现的影响:实际实现中的优化,如MSHR、写缓冲区、预取器、流水线等,可能会引入协议规范之外的行为和时序特性,增加了验证的复杂度。
-
死锁、活锁和饥饿:协议必须保证在任意操作序列下都不会出现死锁(系统完全卡住)、活锁(不断操作但无法前进)和饥饿(某个请求永远无法完成)。
-
与内存模型的一致性:协议实现必须符合架构定义的内存模型(如TSO、RVWMO),这要求验证时不仅要考虑缓存一致性,还要考虑内存操作的全局顺序。
9.2 参考模型与检查器设计
为了验证协议实现的正确性,我们需要一个独立于设计的"黄金参考模型"以及运行时检查器。
9.2.1 黄金参考模型
黄金参考模型是一个高层次的、经过严格验证的协议行为模型,它通常以软件或高级硬件描述语言实现。
-
功能:
-
模拟每个缓存行的全局状态。
-
模拟核心请求和总线事务的交互。
-
维护一个全局的、一致的内存状态视图。
-
预测在给定操作序列下,系统应该表现出的行为。
-
-
实现层次:
-
事务级模型:在事务级别模拟协议行为,不关心具体时序。
-
周期近似模型:考虑大致的时序行为,用于性能评估和早期验证。
-
-
使用方法:在仿真过程中,将设计(DUT)的行为与参考模型的行为进行对比。任何不一致都表明设计错误。参考模型通常比RTL设计简单几个数量级,因此更容易保证其正确性。
9.2.2 运行时一致性检查器
除了参考模型,我们还可以在仿真过程中动态检查一致性不变式。这些不变式是协议必须始终满足的条件。
-
常见不变式:
-
单一写者多读者:在任何时刻,对于一个缓存行,要么只有一个核心可以拥有写权限(M状态),要么有多个核心拥有读权限(S、O状态),但不能同时存在写权限和读权限(除了正在转换的过程中)。
-
数据值一致性:所有非I状态的缓存副本必须包含相同的数据值,除非其中一个正处于被修改的过程中。
-
所有权唯一性:对于任何一个缓存行,最多只能有一个缓存处于M或O状态(即拥有最新数据并负责最终写回)。
-
内存最终一致性:当所有进行中的事务完成后,处于M或O状态的缓存行最终必须写回内存,确保内存与缓存保持一致。
-
-
实现方式:在仿真中,通过后台监控进程周期性地扫描所有缓存的状态和数据,或者在某些关键点(如事务完成时)触发检查,验证上述不变式是否被违反。
9.3 测试场景生成与测试平台构建
一个强大的验证环境需要能够产生各种可能的操作序列,以覆盖尽可能多的协议状态和转换。
9.3.1 定向测试
定向测试针对协议中特别复杂或容易出错的场景设计特定的测试用例。
-
典型场景:
-
S->M转换:多个核心共享同一数据,其中一个核心尝试写入。
-
M->O转换:独占脏数据被其他核心读取。
-
O状态数据提供:拥有O状态的缓存必须响应读请求,同时保持O状态。
-
缓存替换:替换处于M和O状态的脏行,验证写回行为。
-
同时请求:多个核心同时对同一地址发起请求,测试仲裁和排序逻辑。
-
9.3.2 受限随机测试
由于状态空间巨大,完全随机测试效率低下。受限随机测试通过添加约束来引导随机性,覆盖更多有意义的情况。
-
随机因素:
-
核心选择(哪个核心发起请求)。
-
操作类型(读、写、原子操作)。
-
地址(可以选择同一个地址以引发竞争,或不同地址以测试并行性)。
-
请求的时间间隔和并发度。
-
-
约束与权重:
-
设置地址热点,使部分地址被频繁访问。
-
控制读写比例,模拟不同类型的工作负载。
-
对已知的复杂协议转换增加测试权重。
-
9.3.3 并发与压力测试
这类测试旨在暴露竞态条件和资源冲突。
-
方法:
-
让所有核心在尽可能接近的时间点发起对同一地址的访问。
-
长时间运行测试,以积累罕见事件。
-
使MSHR、侦听队列、写缓冲区等微架构结构满负荷运行。
-
-
死锁测试:特意构造可能引起死锁的场景,如循环依赖的请求,验证系统能否正常恢复或避免死锁。
9.4 形式化验证在一致性协议中的应用
形式化验证使用数学方法证明设计在所有可能的输入序列下都满足规范。对于一致性协议,形式化验证可以弥补模拟验证的不足,因为模拟无法覆盖所有可能的状态。
9.4.1 模型检测
模型检测通过穷举搜索设计的状态空间来验证属性是否满足。
-
流程:
-
创建设计的抽象模型,通常比RTL层次更高,以减少状态空间。
-
定义要验证的属性,如一致性不变式、死锁自由等。
-
模型检测工具自动遍历所有可能的状态,检查属性是否在所有状态下都成立。
-
-
工具示例:SPIN, NuSMV, TLA+。
-
挑战与技巧:
-
状态空间爆炸:采用对称性简化、抽象解释、偏序归约等技术。
-
数据抽象:将宽数据路径抽象为简单的符号值,专注于控制逻辑验证。
-
9.4.2 定理证明
定理证明使用数学逻辑来推导出设计的正确性。
-
流程:
-
将设计和规范形式化为数学逻辑中的定理。
-
使用定理证明器(如Isabelle, Coq)来证明设计实现满足规范。
-
-
优点:能够处理无限状态空间,适用于参数化验证(例如,对任意数量的核心都正确)。
-
缺点:需要大量的人工指导和专业知识,通常只用于最关键的协议组件。
-
应用场景:验证精简的核心协议逻辑,或作为其他验证方法的补充。
第10章 设计与验证实例
本章将通过一个简化的实例,展示如何设计一个基于总线的MOESI缓存控制器,并搭建一个基于UVM的验证平台对其进行验证。
10.1 一个简化的MOESI缓存控制器RTL设计
10.1.1 接口定义
我们假设一个基于总线的多核系统,每个缓存控制器有以下主要接口:
module cache_controller #( parameter CORE_ID = 0 )( input wire clk, input wire rst_n, // Core interface input wire core_req_valid, input wire [31:0] core_req_addr, input wire core_req_type, // 0: read, 1: write input wire [63:0] core_req_data, output reg core_req_ready, output reg core_rsp_valid, output reg [63:0] core_rsp_data, // Bus interface output wire bus_req_valid, output wire [2:0] bus_req_type, // BusRd, BusRdX, Upgrade, etc. output wire [31:0] bus_req_addr, input wire bus_req_ready, input wire bus_snoop_valid, input wire [2:0] bus_snoop_type, input wire [31:0] bus_snoop_addr, output reg bus_snoop_ready, output reg [63:0] bus_snoop_data, output reg bus_snoop_invalidate_ack );
10.1.2 状态机实现
以下是高度简化的状态机关键部分,展示了MOESI状态转换的核心逻辑:
// MOESI States
typedef enum logic [2:0] {
STATE_I = 3'b000,
STATE_S = 3'b001,
STATE_E = 3'b010,
STATE_O = 3'b011,
STATE_M = 3'b100
} state_t;
// Bus transaction types
typedef enum logic [2:0] {
BUSRD = 3'b001,
BUSRDX = 3'b010,
UPGRADE = 3'b011,
FLUSH = 3'b100
} bus_req_type_t;
// Cache line storage
state_t [255:0] cache_state; // 256 cache lines
logic [21:0] cache_tag [255:0]; // 22-bit tag for 32-bit address, 256 sets
logic [63:0] cache_data [255:0]; // 64B cache lines
// State machine for handling core requests
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
// Initialize all cache lines to Invalid
foreach(cache_state[i]) cache_state[i] <= STATE_I;
core_req_ready <= 1'b1;
end else begin
if (core_req_valid && core_req_ready) begin
integer index = core_req_addr[7:0]; // Simple direct-mapped, 256 sets
logic [21:0] tag = core_req_addr[31:10];
if (cache_tag[index] == tag && cache_state[index] != STATE_I) begin
// Cache hit
case (cache_state[index])
STATE_S: begin
if (core_req_type == 1'b0) begin // Read hit in S
core_rsp_valid <= 1'b1;
core_rsp_data <= cache_data[index];
end else begin // Write hit in S - need upgrade
core_req_ready <= 1'b0;
issue_bus_request(UPGRADE, core_req_addr);
end
end
STATE_M: begin // Read or Write hit in M
core_rsp_valid <= 1'b1;
core_rsp_data <= cache_data[index];
if (core_req_type == 1'b1) begin // Write
cache_data[index] <= core_req_data;
end
end
// ... handle other states (E, O)
endcase
end else begin
// Cache miss
core_req_ready <= 1'b0;
if (core_req_type == 1'b0) begin // Read miss
issue_bus_request(BUSRD, core_req_addr);
end else begin // Write miss
issue_bus_request(BUSRDX, core_req_addr);
end
end
end
// Handle bus responses and completions
// ... (detailed implementation omitted for brevity)
end
end
// Snoop handling state machine
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
bus_snoop_ready <= 1'b1;
end else if (bus_snoop_valid && bus_snoop_ready) begin
integer index = bus_snoop_addr[7:0];
logic [21:0] tag = bus_snoop_addr[31:10];
if (cache_tag[index] == tag) begin // Snoop hit
case (bus_snoop_type)
BUSRD: begin
case (cache_state[index])
STATE_M: begin
bus_snoop_data <= cache_data[index];
cache_state[index] <= STATE_O; // M -> O transition
end
STATE_E: begin
cache_state[index] <= STATE_S; // E -> S transition
end
// S and O states remain unchanged
endcase
end
BUSRDX, UPGRADE: begin
if (cache_state[index] == STATE_M || cache_state[index] == STATE_O) begin
bus_snoop_data <= cache_data[index]; // Provide data for BusRDX
end
cache_state[index] <= STATE_I; // Invalidate line
bus_snoop_invalidate_ack <= 1'b1;
end
endcase
end
end
end
10.1.3 仲裁逻辑
缓存控制器需要仲裁本地核心请求和外部侦听请求对标签阵列的访问:
// Priority arbitration: snoop requests have higher priority
// to prevent protocol deadlocks
always_comb begin
if (bus_snoop_valid) begin
tag_array_ce = 1'b1;
tag_array_index = bus_snoop_addr[7:0];
core_req_ready = 1'b0; // Stall core request during snoop
end else begin
tag_array_ce = core_req_valid;
tag_array_index = core_req_addr[7:0];
core_req_ready = 1'b1;
end
end
10.2 基于UVM的验证平台搭建
UVM(Universal Verification Methodology)是业界标准的验证方法学,适用于构建模块化、可重用的验证环境。
10.2.1 验证组件
一个典型的UVM验证平台包括以下组件:
// Testbench top module
module tb_top;
// Clock and reset
bit clk;
bit rst_n;
// Instantiate DUT (cache controller)
cache_controller #(.CORE_ID(0)) dut (.*);
// UVM initial block
initial begin
uvm_config_db#(virtual cache_controller_interface)::set(null, "*", "vif", cif);
run_test("moesi_base_test");
end
endmodule
// UVM test class
class moesi_base_test extends uvm_test;
`uvm_component_utils(moesi_base_test)
test_env env;
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
env = test_env::type_id::create("env", this);
endfunction
task run_phase(uvm_phase phase);
// Create and start sequences
core_sequence seq = core_sequence::type_id::create("seq");
phase.raise_objection(this);
seq.start(env.agent.sequencer);
phase.drop_objection(this);
endtask
endclass
10.2.2 序列与激励生成
使用UVM序列来生成核心请求和总线事务:
// Base sequence for core requests
class core_sequence extends uvm_sequence #(core_transaction);
`uvm_object_utils(core_sequence)
rand int num_transactions;
rand bit [31:0] base_address;
virtual task body();
repeat (num_transactions) begin
core_transaction tx = core_transaction::type_id::create("tx");
start_item(tx);
assert(tx.randomize() with {
addr inside {[base_address:base_address+1023]};
});
finish_item(tx);
end
endtask
endclass
// Concurrent access sequence - multiple cores accessing same address
class race_condition_sequence extends uvm_sequence #(core_transaction);
`uvm_object_utils(race_condition_sequence)
rand bit [31:0] race_address;
virtual task body();
fork
begin // Core 0: read then write
`uvm_do_on_with(seq, p_sequencer, {addr == race_address; req_type == 0;}) // Read
#10;
`uvm_do_on_with(seq, p_sequencer, {addr == race_address; req_type == 1;}) // Write
end
begin // Core 1: simultaneous write
#5; // Slight offset to create race
`uvm_do_on_with(seq, p_sequencer, {addr == race_address; req_type == 1;}) // Write
end
join
endtask
endclass
10.2.3 记分板与覆盖率收集
// Scoreboard - compares DUT behavior with reference model
class moesi_scoreboard extends uvm_scoreboard;
`uvm_component_utils(moesi_scoreboard)
// Reference model
moesi_ref_model ref_model;
// Coverage collectors
covergroup state_transition_cg;
pre_state: coverpoint pre_state { bins states[] = {I, S, E, O, M}; }
post_state: coverpoint post_state { bins states[] = {I, S, E, O, M}; }
operation: coverpoint op_type { bins ops[] = {PrRd, PrWr, BusRd, BusRdX}; }
transition: cross pre_state, post_state, operation;
endgroup
function new(string name, uvm_component parent);
super.new(name, parent);
state_transition_cg = new();
ref_model = new();
endfunction
// Check each transaction against reference model
virtual function void check_transaction(core_transaction tx);
ref_model_state expected_state = ref_model.get_expected_state(tx.addr);
dut_state actual_state = get_dut_state(tx.addr);
if (expected_state != actual_state) begin
`uvm_error("SCOREBOARD", $sformatf("State mismatch for addr %h: expected %s, got %s",
tx.addr, expected_state.name(), actual_state.name()))
end
// Update coverage
state_transition_cg.sample();
endfunction
endclass
10.3 典型Bug分析与调试技巧
典型Bug案例:
-
状态机错误:某个状态转换缺少或错误。
-
症状:缓存行卡在某个状态无法前进,或者出现不应该存在的状态组合。
-
调试:在波形中查看状态转换序列,与协议规范对比。
-
-
竞态条件:由于仲裁优先级问题,导致请求处理顺序错误。
-
症状:偶尔出现数据不一致,问题难以稳定复现。
-
调试:使用同步检查点,在可疑区域增加日志记录,分析并发操作的时序关系。
-
-
死锁:两个核心互相等待对方释放资源。
-
症状:仿真挂起,无进一步进展。
-
调试:检查MSHR、队列等资源的使用情况,分析请求依赖关系。
-
调试技巧:
-
波形分析:在波形中查看缓存行状态、总线事务和核心请求,追溯错误发生时的操作序列。
-
// Assertion: M state should be exclusive assert_m_state_exclusive: assert property ( @(posedge clk) (cache_state[index] == STATE_M) |-> !$countones(sharers_vector) == 1 ) else `uvm_error("ASSERT", "M state not exclusive"); -
日志记录:在仿真中记录每个重要事件(状态转换、事务发起/响应),便于离线分析。
-
压力测试:构造极端场景,如满负荷运行、资源耗尽等情况,暴露边界条件错误。
本章小结:
本章我们深入探讨了MOESI协议的验证策略和工程实践。我们从验证的巨大挑战入手,介绍了参考模型、运行时检查器、定向测试、随机测试和形式化验证等综合验证方法。通过一个简化的RTL设计实例和基于UVM的验证平台搭建示例,我们展示了如何将理论转化为实践。最后,我们分析了典型Bug模式和调试技巧。扎实的验证是确保复杂协议在芯片中正确运行的唯一途径,需要结合多种验证方法学,构建多层次、全方位的验证体系。在接下来的章节中,我们将转向性能分析与优化,探讨如何让正确实现的协议达到最佳性能。
第11章 性能建模与评估
在深入优化MOESI协议之前,我们必须首先建立一套科学的性能评估体系。本章将系统性地介绍衡量缓存一致性协议性能的关键指标、主流的评估工具与方法,以及如何分析不同工作负载对协议行为的影响。
11.1 性能度量指标
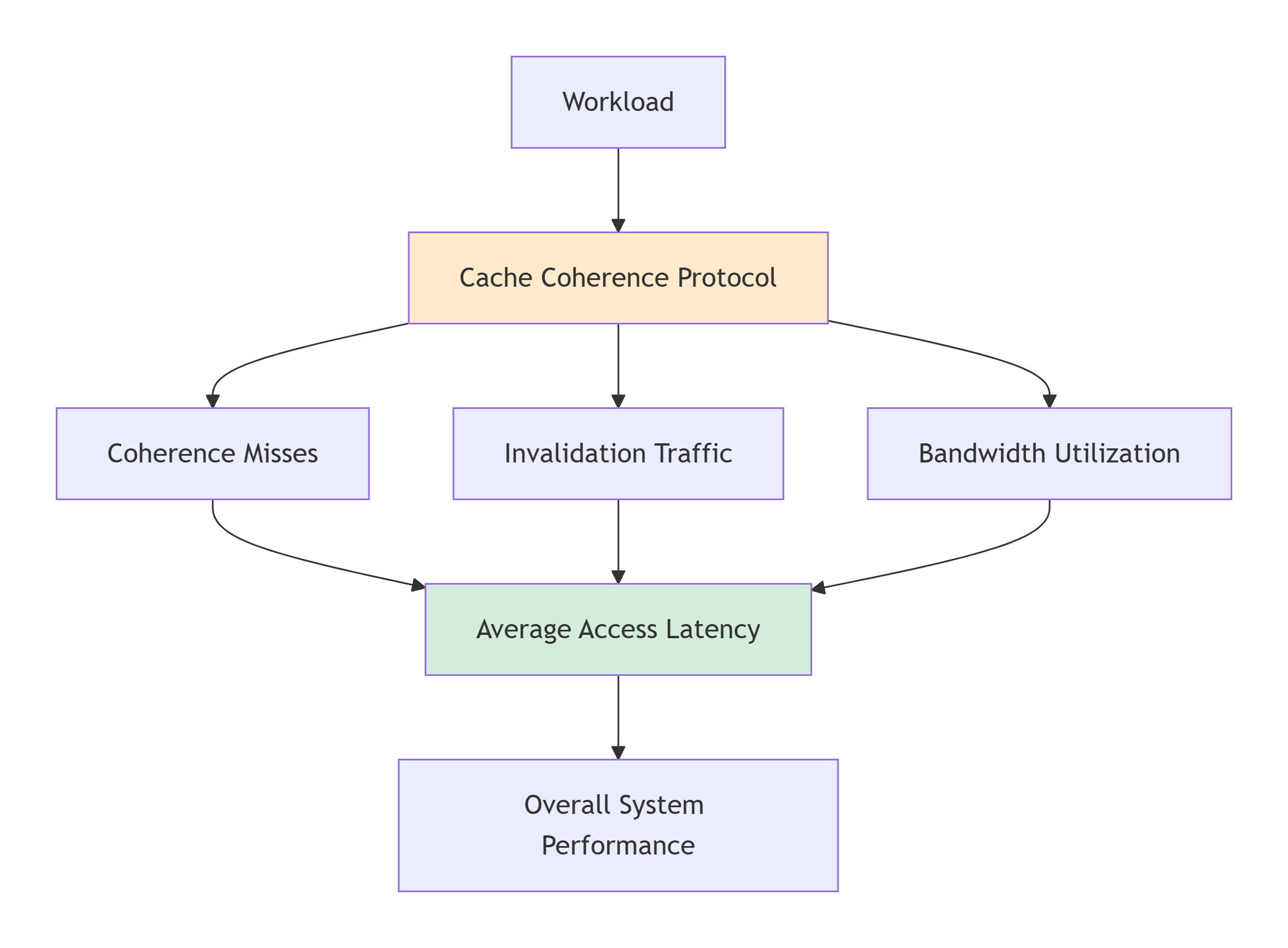
评估MOESI协议的性能需要从多个维度进行考量,以下是最核心的度量指标:
11.1.1 平均访问延迟
这是最直观的性能指标,衡量CPU核心发出内存访问请求到获得数据所需的平均时间。
-
计算公式:
平均访问延迟 = (总访问周期数) / (总访问次数) -
组成部分:
-
命中延迟:访问本地缓存命中的延迟,通常最低(1-4周期)。
-
未命中延迟:访问未命中时,需要从其他缓存或内存获取数据的延迟。这又包括:
-
一致性未命中:由于维护一致性而产生的额外延迟,如发送无效化消息、等待确认等。
-
容量/冲突未命中:与一致性无关的传统缓存未命中。
-
-
-
协议影响:MOESI协议主要通过影响一致性未命中的延迟来影响平均访问延迟。例如,
O状态的存在避免了某些情况下的内存写回,从而降低了读未命中的延迟。
11.1.2 带宽利用率
衡量互联网络和内存子系统在单位时间内传输的数据量。
-
协议相关带宽:
-
一致性请求带宽:用于传输
BusRd,BusRdX,Upgrade等命令消息的带宽。 -
数据响应带宽:用于传输实际缓存行数据的带宽。
-
无效化确认带宽:用于传输确认消息的带宽。
-
-
协议影响:MOESI协议通过减少不必要的数据传输来优化带宽。例如:
-
Upgrade事务相比BusRdX节省了数据传输带宽。 -
O状态允许脏数据在缓存之间直接传输,避免写回内存,节省了内存带宽。
-
-
瓶颈分析:高带宽利用率可能导致互联网络拥塞,进而增加所有请求的延迟。需要分析是命令带宽还是数据带宽成为瓶颈。
11.1.3 无效化流量
这是衡量协议可扩展性的关键指标,特别是在多核环境下。
-
定义:单位时间内产生的无效化消息(包括
BusRdX,Upgrade以及目录协议中的点对点无效化)的数量。 -
协议影响:
-
在侦听协议中,每次写操作都需要广播无效化,无效化流量与写操作频率和核心数成正比。
-
在目录协议中,无效化只发送给实际的共享者,流量与共享者数量成正比,可扩展性更好。
-
-
缓存乒乓:当多个核心频繁交替读写同一缓存行时,会产生大量的无效化消息和缓存未命中,导致性能急剧下降。这是无效化流量过高的典型表现。
11.2 模拟器与仿真工具
由于在真实硬件上评估不同协议变体成本高昂且不灵活,计算机架构研究严重依赖于周期精确的模拟器。
主流模拟器介绍
-
gem5:
-
描述:最主流、模块化程度最高的开源计算机系统模拟器。
-
对一致性协议的支持:内置了经典的MSI、MESI、MOESI等侦听协议模型,并支持基于目录的协议。用户可以通过Python配置不同的协议参数、缓存层次和互联网络。
-
适用场景:学术研究、工业界原型评估。
-
-
GEMS (General Execution-driven Multiprocessor Simulator):
-
描述:与Simics全系统模拟器配合使用,以其详细的Ruby内存系统模型而闻名。
-
特点:提供了极其灵活的一致性协议建模框架,允许用户自定义各种协议状态和转换。
-
适用场景:深入的内存系统研究。
-
-
Sniper:
-
描述:基于Interval Core模型,在速度和准确性之间取得了良好平衡。
-
特点:模拟速度比gem5快一个数量级,适合评估多核性能趋势。
-
适用场景:面向多核架构的早期探索和设计空间探索。
-
模拟器工作流程
使用gem5评估MOESI协议的典型流程如下:
# 1. 编译gem5
scons build/X86/gem5.opt -j8
# 2. 运行模拟,指定协议和系统配置
build/X86/gem5.opt configs/example/se.py \
--cpu-type=TimingSimpleCPU \
--num-cpus=4 \
--caches \
--l2cache \
--cacheline_size=64 \
--ruby \ # 使用Ruby内存系统
--network=simple \ # 互联网络类型
--topology=Mesh_XY \ # 拓扑结构
--coherence-protocol=MOESI_hammer \ # 指定MOESI协议
-c benchmarks/hello --options=""
结果分析与可视化
模拟器会生成详细的统计文件(stats.txt),包含大量性能计数器数据:
system.ruby.l1_cntrl0.L1Dcache.demand_hits::total 985432 system.ruby.l1_cntrl0.L1Dcache.demand_misses::total 12345 system.ruby.l1_cntrl0.L1Dcache.coherence_misses::total 5678 system.ruby.l1_cntrl0.L1Dcache.avg_miss_latency::total 45.6 system.ruby.network.average_packet_latency 12.3
通过分析这些数据,可以计算出一系列性能指标,并绘制图表进行比较。
11.3 工作负载特征分析
不同的应用程序对缓存一致性协议的压力截然不同。理解工作负载特征是指引性能优化的罗盘。
工作负载分类
根据数据共享模式,可以将多线程工作负载大致分为以下几类:
-
私密型:
-
特征:线程主要操作各自私有的数据,极少共享。
-
对MOESI的压力:极低。大部分时间缓存行处于
E或M状态,几乎不产生一致性流量。 -
例子:Embarrassingly parallel计算,如独立的图像帧处理。
-
-
只读共享型:
-
特征:多个线程频繁读取同一数据,但从不或极少写入。
-
对MOESI的压力:低。数据在所有读者缓存中保持
S状态,仅在首次读取时产生BusRd,之后无一致性流量。 -
例子:查询只读数据库、共享配置信息。
-
-
生产者-消费者型:
-
特征:一个线程(生产者)写入数据,一个或多个线程(消费者)读取数据。数据单向流动。
-
对MOESI的压力:中等。生产者写入时会使消费者的副本无效(
S->I),消费者下次读取时会发生未命中。会产生规律的无效化和BusRd流量。 -
例子:流水线并行应用。
-
-
频繁读-写共享型:
-
特征:多个线程频繁地读写同一小块内存区域(如共享计数器、锁、任务队列)。
-
对MOESI的压力:极高。这是最坏的情况,会导致严重的缓存乒乓。
-
线程A读取数据,状态为
S。 -
线程A写入,发出
Upgrade,无效化B、C...,状态变为M。 -
线程B读取,发生未命中,发出
BusRd,A提供数据并降级为O(或S)。 -
线程B写入,发出
Upgrade,无效化A、C...,状态变为M。 -
如此循环,产生大量一致性流量和未命中。
-
-
例子:自旋锁、高频计数器、某些图算法。
-
案例分析:自旋锁的性能灾难
让我们分析一个简单的自旋锁实现,它如何导致缓存乒乓:
// 简单的测试与设置自旋锁
typedef struct lock {
volatile int flag;
} lock_t;
void lock(lock_t *lock) {
while (__atomic_test_and_set(&lock->flag, __ATOMIC_ACQUIRE)) {
// 自旋等待
}
}
void unlock(lock_t *lock) {
__atomic_clear(&lock->flag, __ATOMIC_RELEASE);
}
MOESI协议下的消息流(假设两个核心竞争锁):
-
核心A获得锁,将
flag置为1(状态M)。 -
核心B尝试获取锁,执行
test_and_set。-
B发出
BusRdX请求。 -
A侦听到后,提供数据并将状态改为
I。 -
B获得独占权,执行操作,发现锁已被占用,进入自旋。
-
-
核心B在自旋循环中不断读取
flag。-
每次读取都发出
BusRd。 -
A(或后来持有锁的核心)每次都要响应,状态在
M和O之间切换。
-
-
当核心A释放锁时,同样会触发
BusRdX和无效化。
结果:即使没有真正的数据共享(只有一个核心能持有锁),对锁变量的竞争也会产生巨大的一致性流量,严重浪费带宽和增加延迟。
本章小结:
本章我们建立了评估MOESI协议性能的科学框架。我们定义了平均访问延迟、带宽利用率和无效化流量这三个核心指标,并解释了MOESI协议如何影响它们。我们介绍了gem5等主流模拟器工具链,它们是进行架构探索和性能分析的基石。最后,我们深入分析了不同工作负载特征对协议的压力,并通过自旋锁的例子生动展示了缓存乒乓的危害。在下一章中,我们将基于本章的评估方法,深入探讨一系列旨在提升MOESI协议性能的优化技术。
第12章 优化技术深入
在建立了性能评估体系之后,我们现在可以系统地探讨如何优化MOESI协议。优化可以从多个层面进行:协议本身的改进、微架构的增强,以及针对特定应用模式的定制化优化。
12.1 协议级优化
这些优化通过修改或扩展MOESI协议的状态和转换规则来直接提升性能。
12.1.1 写合并与批处理无效化
-
问题:当多个核心频繁修改同一缓存行的不同部分时(例如,一个结构体中的不同字段),传统的MOESI协议会对整个缓存行进行多次无效化和获取独占权的操作,即使这些修改并不冲突。
-
解决方案:写合并。
-
机制:缓存控制器检测到对同一缓存行的多次写请求。它将这些写操作在缓冲区中合并,最终只发起一次
BusRdX事务,获得独占权后,将合并后的结果一次性写回缓存行。
-
-
协议扩展:这通常不需要改变MOESI状态定义,但需要在缓存控制器中实现一个写合并缓冲区。
-
收益:显著减少了一致性事务的数量和互联网络带宽消耗。
12.1.2 推测执行与预取
-
问题:一致性未命中带来的延迟无法被传统的、针对单一核心的预取器有效隐藏。
-
解决方案:
-
一致性感知预取:预取器在预取数据时,不仅考虑地址模式,还考虑一致性状态。例如,对于可能被写入的共享数据,可以推测性地以
E状态而不是S状态进行预取,从而避免后续写入时的升级延迟。 -
推测性状态提升:当缓存控制器预测到某个处于
S状态的行很可能即将被写入时,它可以提前发出Upgrade请求,在核心实际发出写操作之前就获得独占权。
-
-
风险:推测错误会导致不必要的带宽消耗,并可能无效化其他核心的有用副本。
12.2 架构级优化
这些优化通过改进支撑协议的硬件架构来提升性能。
12.2.1 非阻塞缓存与MSHR优化
-
基础:第6章已介绍MSHR。其设计质量直接决定性能。
-
高级优化:
-
MSHR合并范围:扩大MSHR的合并能力,不仅能合并对同一缓存行的未命中,还能合并对同一缓存组甚至虚拟地址页的未命中请求。
-
优先级调度:为MSHR中的不同请求赋予优先级。例如,处理侦听无效化请求的优先级可能高于处理核心读未命中的优先级,以防止协议死锁。
-
分布式MSHR:在大型多核中,采用分布式的MSHR结构,避免集中式MSHR成为瓶颈。
-
12.2.2 优化的互联网络设计
互联网络是协议的血管,其效率至关重要。
-
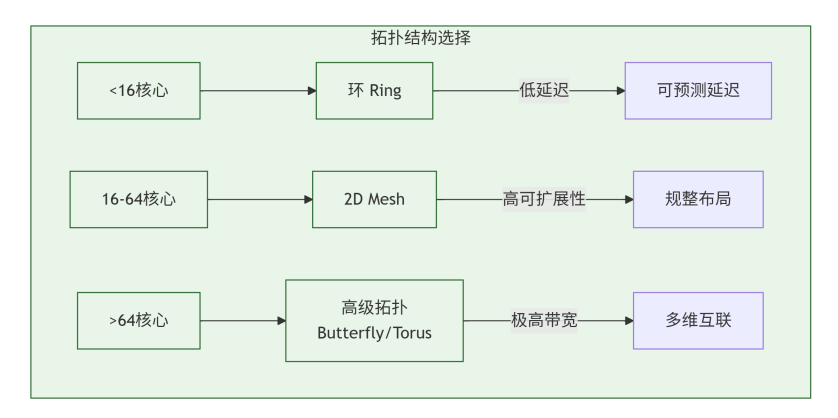
拓扑优化:对于不同规模的核心数,选择最优拓扑。
-
小规模(<16 cores):Ring(延迟可预测)或 Crossbar(高带宽)。
-
中大规模(16-64 cores):2D-Mesh(布局规整,可扩展性好)。
-
超大规模(>64 cores):2.5D/3D集成、Butterfly等更高维度的拓扑。
-
-
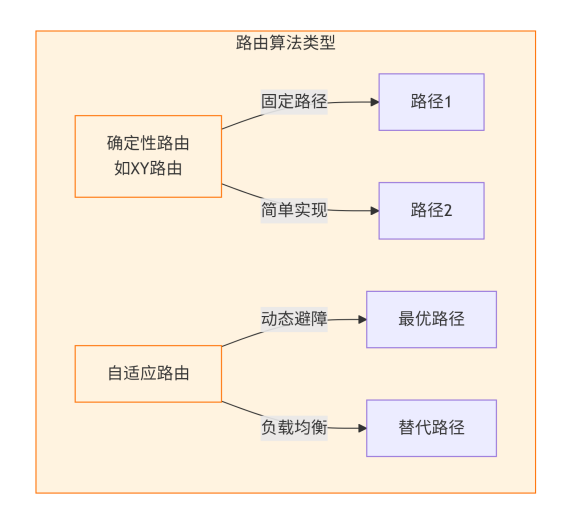
路由算法优化:
-
自适应路由:允许数据包根据网络当前拥塞情况动态选择路径,避免热点。
-
优先级路由:为一致性请求(如无效化确认)分配更高的路由优先级,以降低关键路径延迟。
-
12.3 针对特定应用模式的优化
某些优化是针对已知的、性能极差的特定应用模式而设计的。
12.3.1 锁消除与事务内存
-
目标:解决因细粒度锁(如自旋锁)导致的缓存乒乓。
-
锁消除:
-
原理:通过硬件或编译器分析,识别出某些锁保护的操作实际上并不冲突,从而完全避免获取锁。
-
例子:如果两个线程对同一个链表进行插入操作,但插入的是不同的节点,硬件可以探测到它们访问的是不同的内存地址,从而允许它们并发执行。
-
-
硬件事务内存:
-
原理:将一段临界区代码标记为一个“事务”。硬件会跟踪事务内访问的内存地址。如果事务执行过程中没有与其他线程发生冲突,则提交所有修改。如果发生冲突(如其他线程修改了事务访问的数据),则中止当前事务,回滚所有操作,并重试。
-
对一致性的影响:HTM在底层仍然依赖MOESI协议来检测冲突(通过缓存行的无效化消息),但它将频繁的锁竞争转化为了偶尔的事务中止,极大地降低了一致性流量。
-
12.3.2 亲和性感知的数据布局与迁移
-
问题:在NUMA(非统一内存访问)架构中,数据的物理位置对性能影响巨大。如果数据总是被远程核心访问,延迟会很高。
-
解决方案:
-
操作系统/运行时支持:操作系统可以尝试将线程调度到靠近其频繁访问数据的CPU核心上(调度器亲和性)。
-
页面迁移:如果某个物理页被一个远程节点频繁访问,内存管理系统可以将该页面迁移到访问者所在的本地内存中。
-
协议支持:MOESI协议本身不直接负责数据迁移,但目录协议需要能够处理页面迁移后地址与目录项之间的映射关系更新,这是一个复杂的工程问题。
-
12.3.3 针对“单生产者-多消费者”的优化
这是一种非常常见的模式,值得特殊优化。
-
问题:传统MOESI下,生产者每次更新数据,都需要无效化所有消费者,导致大量
BusRd流量。 -
解决方案:基于更新的协议 或 多播。
-
选择性更新:在目录协议中,当生产者更新数据时,目录不是发送无效化,而是将更新后的数据多播给所有当前注册的消费者。消费者收到后更新其本地副本,状态保持为
S。 -
权衡:这违背了写无效协议的原则。如果消费者很多,但只有少数会真正读取新数据,那么多播更新会浪费带宽。因此,这种优化通常只在共享者数量稳定且读取概率很高时才有效。
-
现代实现:一些现代互联网络(如Intel的UPI)支持有保证的交付多播,可以高效地实现这种优化。
-
本章小结:
本章我们深入探讨了提升MOESI协议性能的多种技术路径。在协议层面,我们看到了写合并和推测性预取如何减少事务数量和延迟。在架构层面,MSHR的优化和高效互联网络的设计是支撑协议性能的基础。最后,我们针对锁竞争、NUMA访问和生产者-消费者等特定瓶颈模式,介绍了锁消除、事务内存、数据迁移和多播等高级优化技术。这些优化并非孤立的,在实际芯片设计中,它们往往被组合使用,形成一个多层次、自适应的性能优化体系。一个优秀的架构师需要深刻理解这些技术背后的权衡,根据目标工作负载的特征,做出最合适的设计决策。在接下来的第六部分,我们将对全书内容进行总结,并展望缓存一致性技术的未来发展方向。
第13章 总结
经过前面十二章的系统性学习,我们已经构建了关于MOESI协议的完整知识体系。本章将对整个专题的核心内容进行梳理和总结,帮助读者巩固关键概念和实践要点。
13.1 MOESI协议精髓回顾
MOESI协议之所以能够成为现代多核处理器缓存一致性的基石,源于其精巧的状态设计和转换逻辑。让我们回顾其核心精髓:
核心状态的价值
-
M (Modified):代表"独占且最新",是性能的巅峰状态。核心可以无干扰地进行本地读写,无需任何外部通信。这是写操作的理想终点。
-
O (Owned):MOESI协议的灵魂所在。它优雅地解决了共享脏数据的困境:
-
允许多个读者同时存在,避免了重复的内存读取。
-
明确了数据责任方,确保脏数据能够被正确写回。
-
充当了M状态和S状态之间的智能缓冲,优化了"读-改-写"模式下的性能。
-
-
E (Exclusive):代表"静默的潜力",是读操作的理想状态。核心拥有数据的唯一副本,可以随时升级为M状态而无需通知任何人。
-
S (Shared):代表"经济的并行",允许多个核心同时安全地读取数据,最大化数据复用。
-
I (Invalid):系统的"重置按钮",确保过时数据不会被错误使用,是维护正确性的基石。
设计哲学
MOESI协议体现了几个关键的设计哲学:
-
懒惰更新:除非必要,否则不更新内存。O状态的存在就是这一哲学的完美体现。
-
精准通信:只在需要时才进行核心间通信,通过精确的状态转换最小化一致性流量。
-
分布式责任:每个缓存控制器都是自主的状态机,通过本地决策和有限通信维护全局一致性。
13.2 设计验证要点总结
基于工程实践的角度,我们总结出MOESI协议实现和验证的关键要点:
对于设计工程师
-
状态机的原子性:确保对缓存行状态的任何更新都是原子的,防止核心访问和侦听请求之间的竞态条件。
-
死锁避免:仔细设计MSHR、侦听队列等资源的依赖关系,确保不会出现循环等待。
-
内存模型合规性:协议实现必须严格遵守目标架构的内存模型要求,特别是在操作排序方面。
-
可扩展性考量:在设计初期就要考虑协议从侦听到目录的演进路径,保持微架构的灵活性。
对于验证工程师
-
多层次验证策略:结合定向测试、受限随机测试和形式化验证,构建完整的验证闭环。
-
不变式检查:实现运行时的一致性不变式检查器,这是捕捉复杂并发Bug的最有效手段。
-
压力测试:构造极端场景,如全系统并发访问、资源耗尽等,暴露边界条件问题。
-
参考模型的重要性:建立一个简单但正确的黄金参考模型,作为判断设计正确性的最终标准。
性能优化平衡
在实践中,需要在多个维度间进行权衡:
-
延迟 vs 带宽:某些优化(如预取)可能降低延迟但增加带宽消耗。
-
存储开销 vs 性能:更精细的目录设计可能提升性能但增加芯片面积。
-
复杂度 vs 正确性:过于复杂的优化可能引入难以发现的Bug。
第14章 未来展望
缓存一致性协议的发展远未结束。随着计算范式和应用需求的不断演进,MOESI协议及其后续发展面临着新的挑战和机遇。
14.1 一致性协议面临的挑战
规模扩展的极限
当前基于目录的协议虽然理论上可以支持数百个核心,但在实际实现中面临严峻挑战:
-
目录存储开销:在千核级别的处理器中,即使采用稀疏目录,其存储开销仍然巨大。
-
网络延迟:在大规模Mesh网络中,最远节点间的通信延迟可能达到数百个周期,成为性能瓶颈。
-
能耗效率:一致性通信的能耗在总芯片功耗中的占比持续上升。
异构集成的复杂性
未来的计算系统将是高度异构的,这对一致性协议提出了全新要求:
-
混合一致性模型:CPU、GPU、FPGA和专用加速器可能对一致性有不同的需求和代价模型。
-
跨芯片一致性:在Chiplet架构中,需要实现跨不同工艺、不同供应商的芯片粒子的缓存一致性。
-
异构内存一致性:在包含HBM、DDR、非易失内存等的混合内存系统中,一致性协议需要感知不同内存介质的特性。
安全性的考量
缓存一致性协议正在成为新的安全攻击面:
-
侧信道攻击:通过观察一致性消息模式可以推断其他核心的访问模式,泄露敏感信息。
-
一致性协议漏洞:协议实现中的Bug可能被利用来获得未经授权的数据访问。
-
可信执行环境:在安全飞地(如Intel SGX、AMD SEV)中维护缓存一致性同时防止信息泄漏极具挑战性。
14.2 新兴技术与研究方向
面对上述挑战,学术界和工业界正在探索多个前沿方向:
协议创新
-
令牌一致性协议:
-
核心思想:将写权限抽象为有限数量的"令牌",只有持有令牌的核心才能写入相应数据。
-
优势:天然避免了写冲突,简化了协议状态机,特别适合大规模系统。
-
挑战:令牌管理的开销和复杂性。
-
-
区域一致性模型:
-
核心思想:允许程序员或编译器为不同的内存区域指定不同的一致性强度。
-
应用:对一致性要求不高的数据可以使用弱一致性模型以减少开销,关键数据使用强一致性保证正确性。
-
实现:需要在硬件中支持多种一致性协议并行运行。
-
架构革新
-
近内存计算:
-
概念:将计算单元放置在内存控制器附近或内存芯片内部。
-
对一致性的影响:重新定义了"缓存"的概念,需要新的协议来处理计算单元与主机CPU之间的一致性。
-
-
光学互连:
-
前景:使用光信号代替电信号进行芯片内和芯片间通信。
-
影响:极低的延迟和能耗可能彻底改变一致性协议的设计假设,使得更频繁的细粒度一致性通信成为可能。
-
-
3D堆叠集成:
-
现状:通过硅通孔(TSV)实现芯片的垂直堆叠。
-
机会:极大地缩短了缓存之间的物理距离,为一致性协议提供了全新的拓扑结构优化空间。
-
软件定义的一致性
-
可编程一致性控制器:
-
愿景:像可编程网络交换机一样,允许系统软件根据工作负载特征动态调整一致性协议。
-
潜力:为不同的应用阶段选择最优的一致性策略,实现极致的性能优化。
-
-
机器学习驱动的协议优化:
-
方法:使用机器学习模型预测数据的共享模式,提前进行状态转换或数据迁移。
-
应用:智能预取、动态协议选择、自适应缓存管理等。
-
量子计算的影响
虽然尚属远期展望,但量子计算对经典计算架构的冲击值得关注:
-
量子经典混合计算:在量子处理器与经典处理器协同工作时,需要定义全新的"量子-经典"一致性模型。
-
量子内存模型:量子比特的特殊性质(叠加、纠缠)可能需要彻底重新思考一致性的基本定义。
结语:缓存一致性的永恒价值
从最初的MSI协议到今天的MOESI,再到未来的各种创新,缓存一致性协议的发展历程体现了计算机体系结构的一个核心特质:在抽象与实现之间、在正确性与性能之间、在简单性与效率之间寻找精妙平衡的艺术。
MOESI协议之所以经久不衰,正是因为它在这多个维度上都达到了相当优秀的平衡。它的五个状态几乎构成了一个"最小完备集",能够优雅地处理多核环境下的各种数据共享模式。
对于计算机架构师、设计工程师和验证工程师而言,深入理解MOESI协议不仅仅是为了掌握一个具体的技术规范,更是为了培养一种系统性的思维方式——如何设计分布式的状态机,如何在并发环境中保证正确性,如何在复杂约束下优化性能。这种思维方式的价值远远超出了缓存一致性本身,适用于任何复杂的分布式系统设计。
随着计算技术进入后摩尔定律时代,架构创新将成为性能提升的主要驱动力。缓存一致性协议作为连接计算单元、定义系统行为的核心基础设施,必将在未来的计算创新中继续扮演关键角色。掌握MOESI协议的深刻内涵,就是我们参与和推动这一创新浪潮的重要起点。


















 3565
3565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









