







视频教程:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习
在第一篇中,我们采用了鸢尾花的数据集进行了测试,这次我们采用boston的数据集进行测试,boston也是sklearn自带的数据库
程序示例:
from sklearn import datasets##导入datasets
from sklearn.linear_model import LinearRegression##导入线性回归模型
loaded_data=datasets.load_boston()##加载boston数据
data_X=loaded_data.data##数据值
data_y=loaded_data.target##目标值
modele=LinearRegression()##用线性回归模型
modele.fit(data_X,data_y)##data_X是训练数据输入,data_y是训练数据输出
print(modele.predict(data_X[:4,:]))##对前四个数据进行预测
print(data_y[:4])##前四个数据实际值,形成对比,观察其预测的准确度
输出结果:
[30.00384338 25.02556238 30.56759672 28.60703649]##预测值
[24. 21.6 34.7 33.4]##实际值
可以看到,预测的结果并没有那么准确,因为我们并没有将对模型进行改善,所以作为入门学习,采用sklearn默认的模型就足够了
接下来我们创造一些数据,赋值给X,y
程序示例:
from sklearn import datasets##导入datasets
from sklearn.linear_model import LinearRegression##导入线性回归模型
import matplotlib.pyplot as plt##使用图像化工具
X,y=datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1)##创造100个例子,1个特征值,1个回归目标,1noise
plt.scatter(X,y)##画图
plt.show()##展示出画图的结果
输出结果:
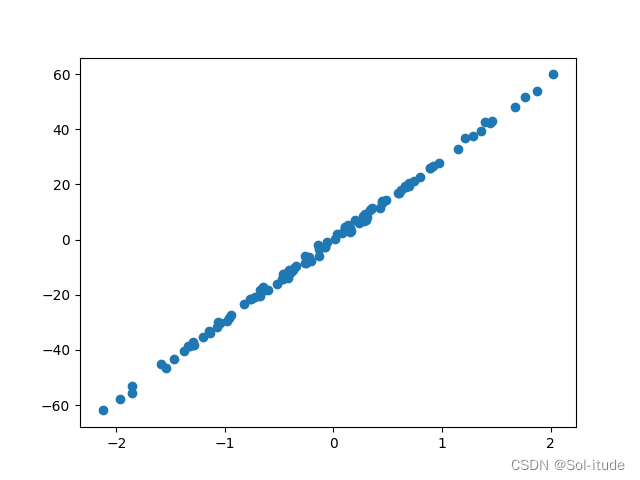
若noise变大,noise=10,离散会更大
noise=10的输出结果:
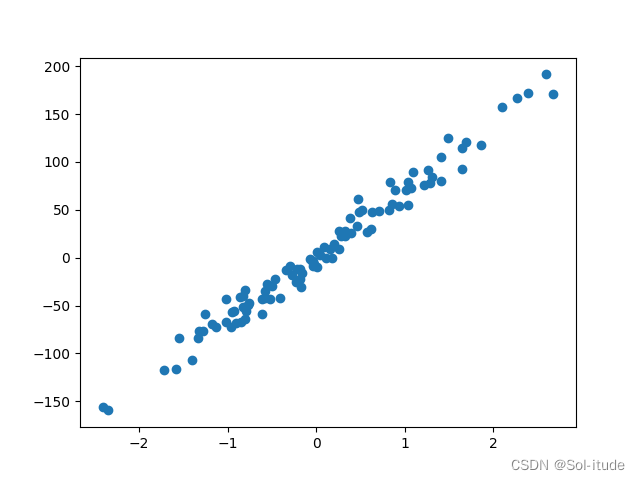
运用我们创造出的数据进行机器学习,可以让我们更有目的性的去进行训练
















 6626
6626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











