







这是一篇经典论文,诞生于2012,很有仔细阅读的必要。
论文连接:ImageNet Classification with Deep Convolutional Networks
摘要
这里的摘要主要是凸显了这一神经网络再ImageNet上面所获得的成绩,并且在比赛中拿下了第一名的好成绩,具体的实现方法没有细说。
Introduction
第一段首先说明了大数据的重要性。第二段就说了自己的CNN的好处,说CNN的参数少,容易训练,但是实际上我们在自己写论文的时候,不要只写自己这个领域的东西,也要照顾到其他领域的内容。第三段讲的是目前的GPU已经足够来训练CNN,ImageNet数据集中包含足够多的有标签的数据,所以不会使CNN出现过拟合。第四段讲的是我们怎样避免过拟合,还说了网络有5个卷积层和3个全连接层。这里还说网络有一些unusual features,所以说这一工作是有创新性和启发性的。最后一段,作者抱怨了GPU的限制,如果有好的GPU会有更好的结果。
THE DATASETS
前面是介绍了一些ImageNet,而重要的时候后面部分,因为ImageNet是没有把图片裁剪好的,所以作者先把图片的短边减少到256,然后长边按照比例往下降,如果长边多于256,他会把图片裁剪成256x256的,他这个是直接在RGB raw上处理的,就是原始的图像。
THE ARCHITECTURE
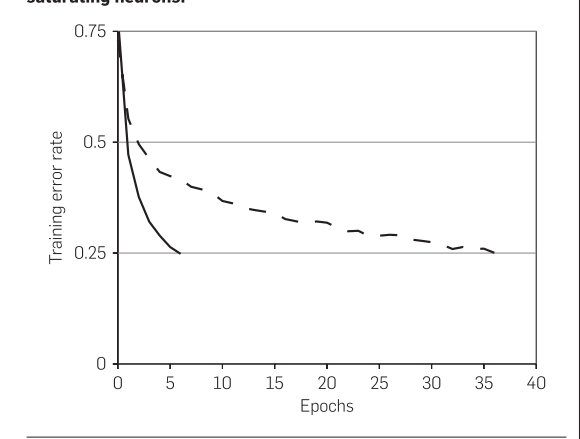
这个图的意思就是我们在用了relu之后,训练的速度变快了,实线是relu,虚线是tanh。但是为什么变快,这里也没有说,需要自己去看一下。正确答案在这里:RNN 中为什么要采用 tanh,而不是 ReLU 作为激活函数? - 何之源的回答 - 知乎
https://www.zhihu.com/question/61265076/answer/186347780因为用tanh或者sigmoid会引起梯度消失的问题。
下一节讲到的是工程上如何用多个GPU去训练。
后面说道Relu不需要归一化防止他们饱和,这是为什么?可以看出来,这一篇文章里面讲了很多是什么,而没有讲为什么?
这里的公式是代表归一化操作。
OVERLAP POOLING
pooling就是降维压缩
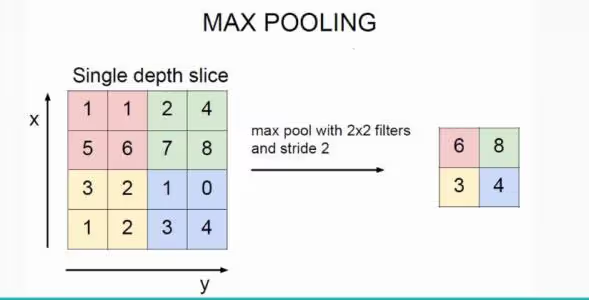
max pooling常用的操作就是filter=2,stride=2,效果就是特征图高度、宽度减半,通道数不变。他的作用是保留主要特征的同时减少参数和计算量,防止过拟合,相当于为了性能,我们在准确率上做了妥协。
Overall architecture
第一个卷积层的输入是224x224x3,红色就是输入进来的图片,首先是有一个11x11的卷积窗口,第一层卷积有48个输出通道,步长是4,我们看这有两个上下分开的,是因为作者是在GPU0和GPU1上分别处理的,但是在第2个卷积层到第3个卷积层的时候,他有一个交叉,相当于进行了一次通讯,第三层接收了第二层的结果,最后224x224的空间信息被压缩到13x13,通道数在慢慢增加,最后有两个全连接层,两个2048会被拼成4096的一个向量。全连接层的作用就是,是把feature map 整合成一个值,这个值大,可以分类,这个值小,那就无法进行分类。就是在最后一步再对13x13x128做卷积,得到1x2048全连接层中一层的一个神经元就可以看成一个多项式,我们用许多神经元去拟合数据分布,但是只用一层fully connected layer 有时候没法解决非线性问题,而如果有两层或以上fully connected layer就可以很好地解决非线性问题了。

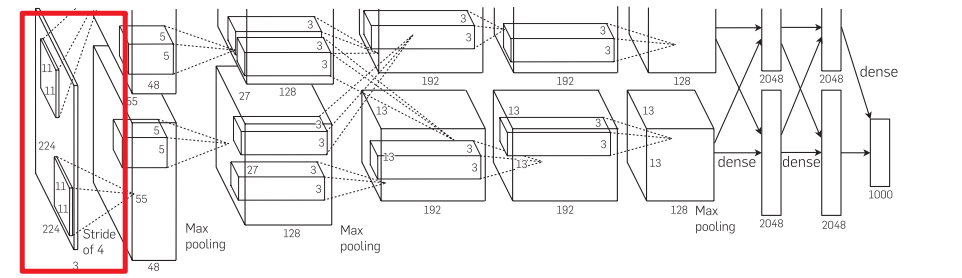
实际上以现在的角度看来,作者没必要分成两块GPU进行训练,当时3GB也是够用的。
REDUCING OVERFITTING
为了防止过拟合,作者用了两种操作,1是在256x256的图片上随机扣下来224x224的图片,然后作者说自己多了2048种,实际上这么说有失偏颇,是因为图片即使是随机的截取,也会出现大量相似的图片,2是对RGB的通道进行了一些改变,用了PCA的方法。
Dropout
Dropout就是在每一个epoch上都随机remove一半,通过忽略一半的特征检测器,减少了过拟合的现象,这样做可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
DETAILS OF LEARNING
这里采用的是SGD算法,SGD的噪声其实是对模型泛华有好处的,这里的权值用均值为0,方差为0.01的高斯随机变量来初始化了,作者一开始把学习率设置为0.01,然后错误率不动了,再将学习率除10.最后训练的模型,经过了5-6天才得出结果。
Results
这里讲作者报告了他们的错误率在ImageNet上,但实际上ImageNet的数据集是有890w张图片和1w多种类别的,比网上所说的120w张图片要更庞大。
最后作者提出了一个疑问,他在GPU1上的图片色彩是失色的,但是在GPU2上的图片的色彩却是完整的,原因仍未知。
DISCUSSION
最后作者没有给出一个结论,而是给出了一个讨论,他说CNN的深度很重要,如果深度少一层,那么性能就会减少2%,但是实际上今天再看这个结论,并非是完全正确的,并且他说自己没有采用无监督学习的预训练。
















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











