







缩写词
AMC:automatic modulation classification ,自动调制分类。
SIG:S for Sequence, I for Image and G for Graph。
LFGM:Limited Fixed Graph Mapping
摘要
目的:为了处理异构输入格式的无线电信号,文章提出了一种名为DeepSIG的混合异构调制分类架构,该架构将递归神经网络(RNN),卷积神经网络(CNN)和图神经网络(GNN)模型集成在单个框架中。传统的方式都是单独使用他们。
in-phase (I) and quadrature (Q) sequences,IQ信号即同相正交信号,I为in-phase同相分量,Q为quadrature正交分量,Q与I的相位相差了90度。
Introduction
第一章主要讲述了论文的研究背景、现有的调制分类方法及其局限性,以及提出的新的混合异构深度学习框架DeepSIG。以下是具体内容的概述:
研究背景与动机
- 无线通信技术的发展:随着物联网(IoT)、5G技术等无线通信技术的快速发展,电磁环境变得越来越复杂,频谱资源短缺问题变得更加严重。
- 频谱利用率的重要性:提高频谱利用率变得愈发重要。认知无线电技术是一种有效的提高频谱效率的方法,它可以动态管理频谱资源的使用。
调制分类的角色
- 调制识别在频谱感知中的作用:调制分类有助于频谱感知,是认知无线电中的关键技术之一。
传统调制分类方法
- 手工特征提取:传统的调制分类方法依赖于手工设计的特征提取步骤,需要专业知识支持,且在复杂环境下分类准确率可能不高。
基于深度学习的自动调制分类(AMC)
- 深度学习的发展:随着人工智能的发展,基于深度学习的AMC方法逐渐兴起,这些方法能够自动学习和提取特征,实现端到端的调制分类。
- 深度学习AMC的输入格式:根据输入格式,基于深度学习的AMC方法可以分为基于序列输入、图像输入和图形输入三类。
各类深度学习AMC方法的特点
- 基于序列输入:
- 输入一般为接收信号的同相(I)和正交(Q)分量,通常使用循环神经网络(RNN)模型来捕捉IQ信号的时间相关信息。
- 基于图像输入:
- 将IQ信号按照一定规则或通过可训练的神经网络层映射成图像,然后使用卷积神经网络(CNN)进行分类。该方法能够利用图像分类领域的技术,但可能会在转换过程中丢失原始信号中的某些信息。
- 基于图形输入:
- 将信号转换为图数据并进行分类。这类方法通过图嵌入方法或图神经网络(GNN)模型实现信号分类,但图映射算法的转换速度较慢,对长时间信号的处理有一定局限性。
DeepSIG框架
- 提出DeepSIG:为了充分利用不同输入格式的数据所包含的潜在信息,本文提出了一个混合异构框架DeepSIG,集成了基于序列、图像和图的三种AMC模型。
- 框架结构:DeepSIG包括四部分:序列网络、图像网络、图网络和融合分类网络。
- 序列网络:使用长短时记忆网络(LSTM)处理IQ信号,提取时间相关特征信息。
- 图像网络:提出了一种新的图像映射方法DWTDR,通过离散小波变换(DWT)的分解和重构将IQ信号映射为双通道窄边图像,然后使用ResNet18模型提取图像特征。
- 图形网络:提出了一种新的图映射方法LFGM,将IQ信号根据其过采样率映射为稀疏图,并使用DiffPool模型提取图特征。
- 融合分类(fusion)网络:将前面三部分提取的特征向量进行归一化和拼接融合,通过全连接层进行最终的调制分类。
主要贡献
- 提出DeepSIG框架:整合了基于序列、图像和图的三种AMC模型,提高了调制识别的准确性。
- 新图像映射方法DWTDR:将IQ信号转换为双通道窄边图像,保留了原始信号中的隐含信息,有助于后续分类。
- 新图映射方法LFGM:高效地将IQ信号映射为稀疏图,适合处理长时间信号。
- 实验验证:在多个数据集和少样本场景下验证了DeepSIG的性能,显示其优于单一输入格式的分类方法。
论文结构
- 第二章:介绍了基于序列、图像和图的调制分类方法的相关工作。
- 第三章:详细介绍了DeepSIG的架构。
- 第四章:提供了仿真结果。
- 第五章:对论文进行了总结。
总体而言,第一章为整个论文奠定了基础,介绍了研究的背景、现有方法的局限性以及提出的新的解决方案DeepSIG的整体框架和贡献。
Related Work
A.AMC Methods With Sequence Input
在当前无线电调制分类的领域,基于序列输入即IQ信号的AMC方法是最常见的。然后列举了一些其他学者所做的调制分类方法。

B.AMC Methods With Image Input
在AMC处理图像输入时,将无线电信号转换成图像的方法是其中的关键步骤之一。可以分为两类:基于固定规则的图像映射方法和基于可训练神经网络层的图像映射方法。在目前来看,前者是很常见的。
总的来说,目前基于固定规则的图像映射方法在转换过程中,容易丢失原始无线电信号的部分信息。基于可训练神经网络层的图像映射方法,需要人工设计再去与特定的网络模型相结合。
C.AMC Methods With Graph Input
在基于图形输入的AMC方法中,将信号映射成图形的方法是必不可少的。文章在这一节介绍了许多类似的基于图形输入的图形映射方法,现有的图映射方法都存在一个共同的问题,都不能很好地应用于长信号。
PROPOSED DEEPSIG FRAMEWORK
A.Problem Formulation
在无线通信领域,调制分类旨在通过对接收信号
r
(
n
)
r(n)
r(n)的分析来推断所发送的基带信号
s
(
n
)
s(n)
s(n)的调制方案。接收信号
r
(
n
)
r(n)
r(n)和发射信号
s
(
n
)
s(n)
s(n)的关系如下:
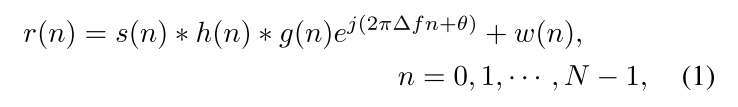
g
(
n
)
g(n)
g(n)是滤波器的响应,
h
(
n
)
h(n)
h(n)是无线信道的响应,
Δ
f
\Delta f
Δf是由接收器和发射器之间的时钟的多普勒频移或同步引起的载波频率偏差。
θ
\theta
θ是相位偏差,
ω
(
n
)
\omega(n)
ω(n)是加性白色高斯噪声,
N
N
N是信号长度,
∗
*
∗代表卷积操作。
C
C
C代表了调制方案的数量,因此,调制分类问题可以被视为具有
C
C
C类的分类问题。
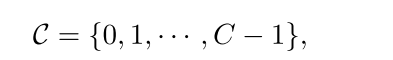
若接收信号是复函数的形式,则以下列I/Q的形式去表示,I代表实部,Q代表虚部。
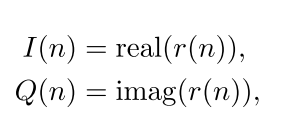
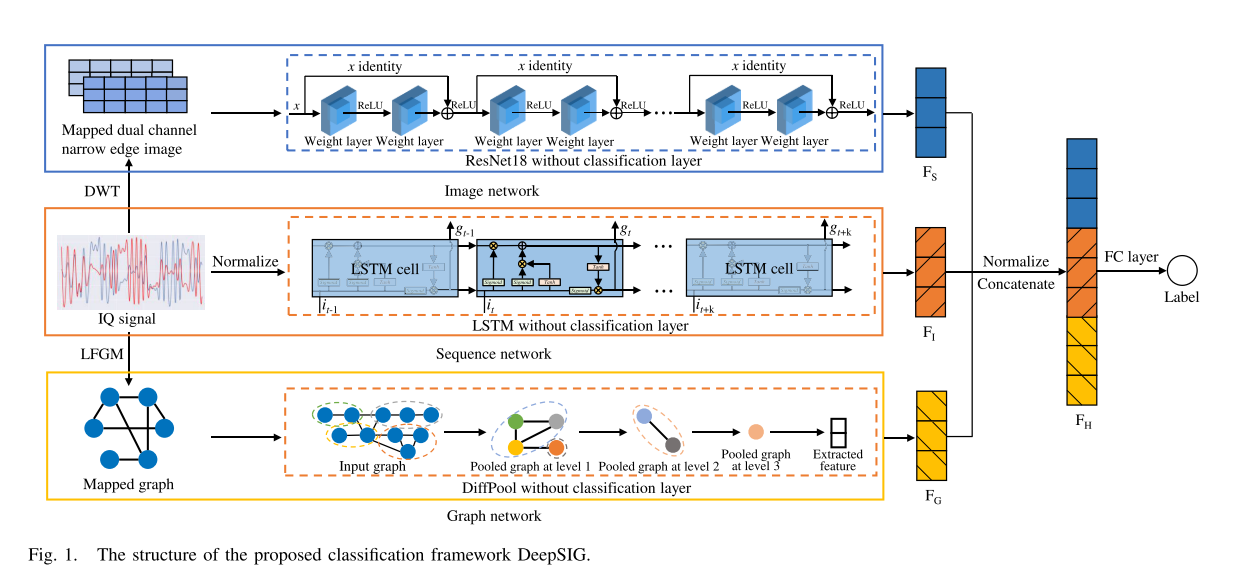
B.Overall Framework
整体的框架如下,对于图像,输入的是映射后的双通道窄边缘图像,经过了没有分类的resnet18,输出了
F
s
F_s
Fs,对于序列信号,输入的是IQ信号,经过了没有分类的 LSTM,输出了
F
I
F_I
FI,对于图形,输入的是映射后的图形,经过了没有分类的DiffPool,输出了
F
G
F_G
FG。其中图像和图形都是由IQ信号得到的,对IQ信号做DWT运算,得到了双通道窄边缘图像,对IQ信号做LFGM运算,得到了映射后的图形。这一框架里面还包含了全连接层,作为分类层。
对于输入进的信号,如果不是IQ信号,我们需要做一些预处理。
我们在DeepSIG的训练过程中做了一些处理,可以分为两步:
1.利用IQ信号序列、DWT得到的图像数据和LFGM得到的图形数据,分别训练LSTM、ResNet18和DiffPool;根据初步训练后保存的三个模型,可以提取每个无线电信号的三个特征向量
F
S
F_S
FS,
F
I
F_I
FI和
F
G
F_G
FG,它们是LSTM,ResNet18和DiffPool模型中最后一个全连接层的对应输入向量。
2.再对这三个特征向量进行归一化处理后,通过拼接处理可以得到融合的特征向量
F
H
F_H
FH,并将其作为输入向量训练新加入的全连接层,以获得最终的分类结果。
C.Sequence Network
在DeepSIG的序列网络部分,输入数据是IQ信号,属于一种时间序列数据,使用的网络模型是LSTM。目前,RNN通常用于通过深度学习处理时间序列。其中,LSTM是较为流行的一种,它可以有效地解决RNN的长期依赖问题。LSTM主要通过遗忘门、更新门和输出门三种门机制来控制从时间序列中提取的特征信息的流动和损失,从而解决普通RNN在训练长时间序列过程中的梯度消失和梯度爆炸问题。
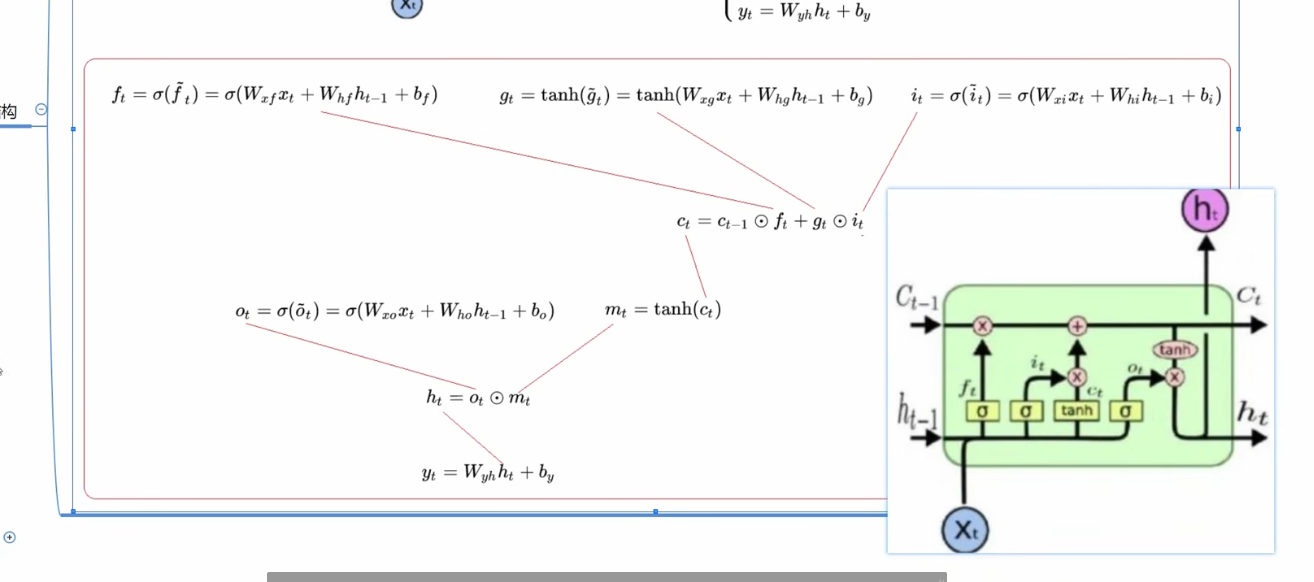
下图就是文中给出LSTM的详细构造,因为整个系统的容量是有限的,为了清除与本次过程无关的记忆内容,保留与本次有关的记忆内容,我们就引入了遗忘门
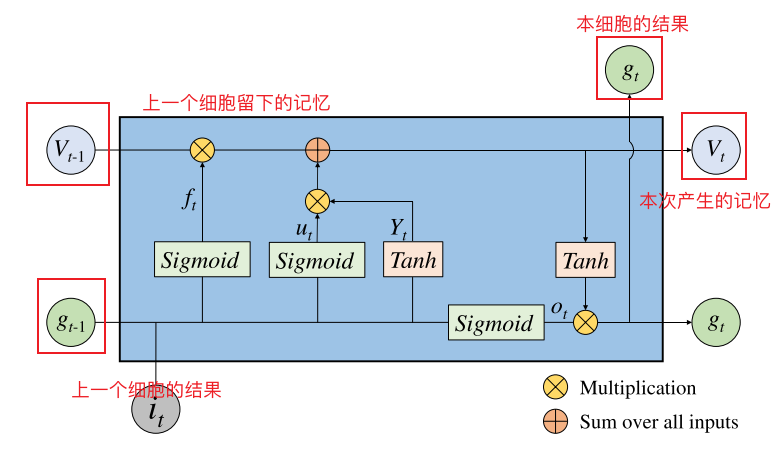
其中,遗忘门
f
t
f_t
ft的公式如下
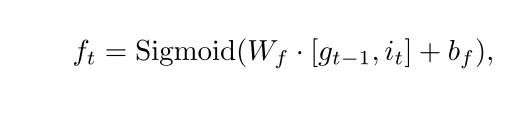
根据这公式所展示的sigmoid,其中
W
f
W_f
Wf和
b
f
b_f
bf分别表示当前神经网络层的可训练权重和偏置。我们会把有用的记忆保留为1,不需要的变为0,这样往上走,进行乘法运算。
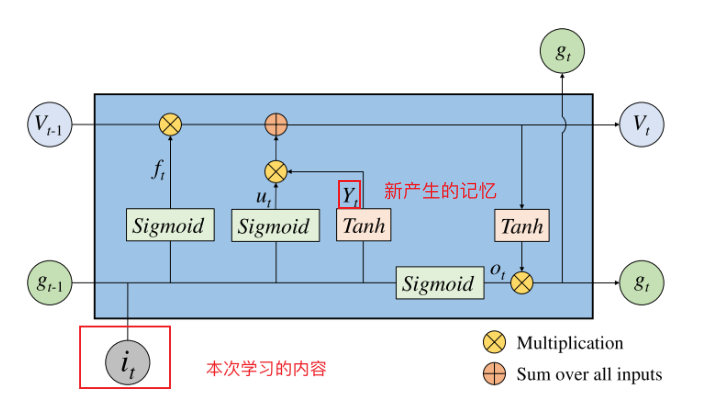
更新门代表经过本次的学习产生了新的内容,但是对于这些内容,我们需要进行筛选,再输出,所以用Sigmoid和Tanh进行了筛选。
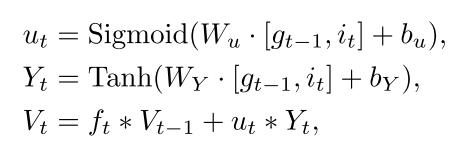
其中
W
u
W_u
Wu、
b
u
b_u
bu、&W_Y
和
和
和b_Y$表示相应神经网络层的权重和偏置。
输出门使用Sigmiod函数来确定需要输出单元状态
V
t
V_t
Vt的哪一部分,我们经过tanh就是为了筛选出我们需要的部分。
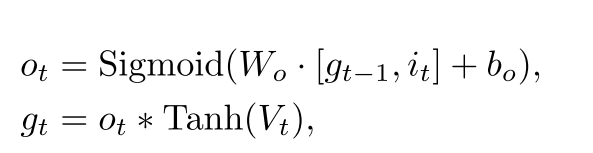
其中
W
o
W_o
Wo和
b
o
b_o
bo分别表示当前神经网络层的权重和偏置。
文章使用了两个LSTM层和一个全连接层来分类序列网络中归一化为[-1,1]的IQ信号数据。下面是归一化的算法伪代码:

第一层由128个LSTM细胞组成,第二层有4个细胞,最后一个全连接层是分类层,用于将第二个LSTM层的输出特征映射到数据集的调制类别数量。
D.Image Network
提出了一种图像映射方法,对IQ信号数据进行DWT处理,得到双通道窄边缘图像数据,然后使用ResNet18模型进行调制识别任务。
小波函数公式:
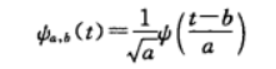
a,b都是整数
例如
a
=
2
j
,
b
=
k
a
,
(
j
=
1
,
2
,
3
,
.
.
.
.
.
.
)
a=2^j,b=ka,(j=1,2,3,......)
a=2j,b=ka,(j=1,2,3,......)
j是离散分解的水平(层数),k是整数
DWT会分解为两部分,approximation cofficients(cA):high scale ,low frequency, detail cofficients(cd):low scale ,high frequency
A是近似值,经过低通滤波器得到
D是细节值,经过高通滤波器得到。实际应用中,低频分量往往是最重要的,高频分量起到的是修饰作用。
1)算法:小波变换是一种具有多分辨率分析特点的时频分析方法,在低频区和高频区分别具有较高的频域分辨率和时间分辨率。用DWT分解信号的层次结构如图所示。
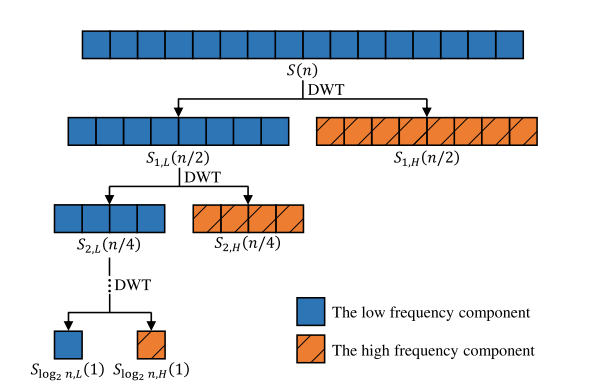
i阶段的DWT信号分解公式如下所示,
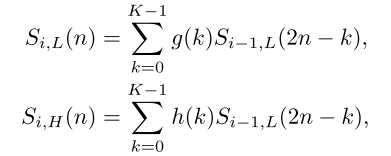
其中
g
(
k
)
g(k)
g(k)和
h
(
k
)
h(k)
h(k)分别表示低通滤波器和高通滤波器,
K
K
K是它们的长度。
k
k
k代表着信号中的时间索引或位置
每次进行DWT分解,得到的两个分量的长度将减少一半,因此我们最多可以对长度为N的序列进行
l
o
g
2
N
log_2 N
log2N阶DWT分解。
在实际应用中,对于包括无线电信号在内的许多序列数据,低频分量是重要的,它往往包含了信号的特征,而高频分量则显示了信号中的细节。
基于近似分量及其对应细节分量的DWT重建过程可以表示为:
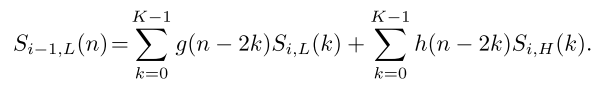
在DWT重构过程中,两个等长的信号分量可以合并为一个新的、长度为原来两倍的信号分量。
利用DWT的多层分解,可以将信号分解成多个高频和低频分量,然后通过多次DWT重构操作将这些分量组合回原始长度的信号。文章的方法与传统的信号重构方法不同之处在于,在DWTDR方法中,信号重构操作包含了一些预处理步骤,以便更好地处理信号分量。
从IQ信号到图像的算法如下所示:

通道1的重建过程如图所示:
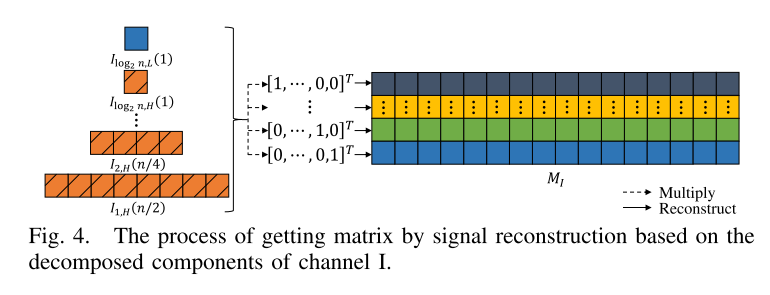
对I通道数据进行多次DWT分解,获取多个高频分量和一个低频分量。根据分解得到的频率分量进行多次重构操作。每次重构操作中,仅保留一个分量,其余设为零,通过多次重构得到新的序列。将所有重构序列组合成一个矩阵。对Q通道数据进行相同处理,得到对应矩阵。将I和Q通道的矩阵拼接,生成最终的图像。
总结一下,就是对I通道和Q通道数据分别进行多次DWT分解和重构操作,生成多个重构序列,然后将这些序列组合成矩阵,最终通过连接I和Q通道的矩阵,生成一个双通道窄边图像。这种方法通过保留和重构频率分量,确保了信号的时间和频率信息在图像映射中的保留和表达。
在得到每个IQ信号对应的
M
I
Q
M_{IQ}
MIQ图像后,文章利用resnet18进行调制分类。从理论上讲,神经网络模型的网络层越深,可以获得的信息越多,特征越丰富。但在实际中,当网络层数超过一定程度时,继续加深网络会造成梯度爆炸或梯度消失的问题,这将对网络的优化产生不利影响。
为了解决这一问题,文章使用了以残差块为核心的resnet18。下图展示了一个残差块的构造:
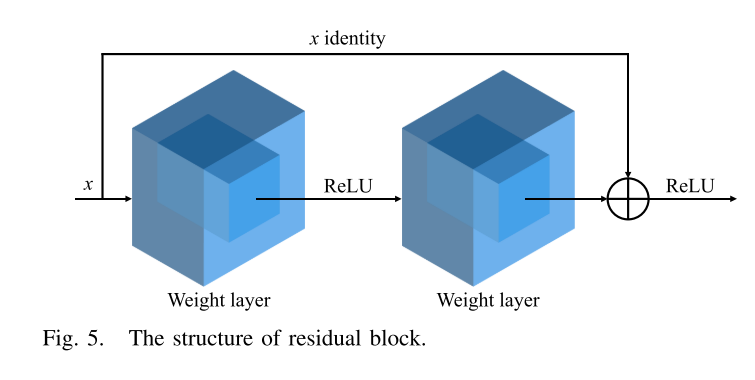
resnet为何能解决梯度爆炸等问题呢?
在深层神经网络中,随着层数的增加,梯度在反向传播过程中会逐层相乘,如果每一层的梯度都非常小(小于1),会导致梯度逐渐变得非常小,称为梯度消失;反之,如果每一层的梯度都非常大(大于1),会导致梯度逐渐变得非常大,称为梯度爆炸。这两种情况都会导致网络难以训练。
残差块通过引入跳跃连接,使得每一个块的输入可以绕过中间的层,直接连接到输出。跳跃连接(Skip Connections)使得梯度可以直接从较深的层传递到较浅的层,从而有效缓解梯度消失和梯度爆炸问题。
从图中可以看出,残差块之间有跳跃连接,跳跃连接提供了一条直接的梯度传播路径,使得梯度可以绕过多个中间层直接传递。这意味着即使中间层的梯度变得非常小或非常大,梯度仍然可以通过跳跃连接有效地传播。
2)Complexity Analysis:
文章在这里分析DWTDR的复杂性,以Haar小波为例子,首先分析时间复杂度,假设他的滤波器长度
K
=
2
K=2
K=2。当对具有长度
N
N
N的IQ信号的信道执行Haar离散小波分解时,需要总共
N
/
2
N/2
N/2次加法和
N
/
2
N/2
N/2次乘法运算。因此,Haar离散小波分解对长度为N的通道数据的时间复杂度为函数
O
(
N
)
O(N)
O(N)。对于2个通道的IQ信号,时间复杂度为
O
(
2
N
)
O(2N)
O(2N)。在DWTDR过程中,总共需要
l
o
g
2
N
log_2N
log2N分解,并且每个分解的序列长度是前一个分解长度的一半。
因此,在DWTDR中IQ信号的整个分解过程的时间复杂度为:
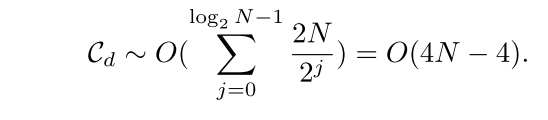
其次,在DWTDR的重构过程中,以处理长度为N的IQ信号的通道序列为例,基于从上述分解获得的一个低频分量和
N
N
N个高频分量,需要递归地执行
l
o
g
2
N
log_2N
log2N次DWT重构操作以获得长度为
N
N
N的序列,即一次信号重构。每次小波变换重构的时间复杂度与相应的小波变换分解的时间复杂度相同,均为
O
O
O(重建序列的长度)。因此,对信道序列执行信号重构操作的时间复杂度为:
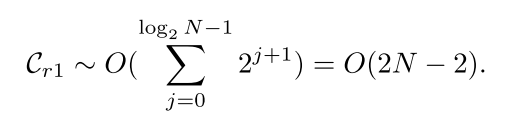
对于IQ信号,存在两个通道序列,并且每个通道序列在整个DWTDR重构过程中需要
(
1
+
l
o
g
2
N
)
(1+log_2N)
(1+log2N)个信号重构操作。
因此,IQ信号的DWTDR重建的时间复杂度为:
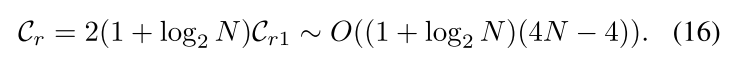
最后,我们可以知道DWTDR的时间复杂度是:
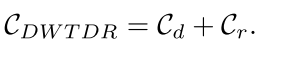
同样,DWTDR的空间复杂度也可以分为两部分:分解和重构。以IQ信号的信道序列为例,在分解过程中,
(
1
+
l
o
g
2
N
)
(1+log_2N)
(1+log2N)的数组空间,需要存储一个低频分量和分解后得到的N个高频分量。因此,在DWTDR分解过程中IQ信号的空间复杂度为:
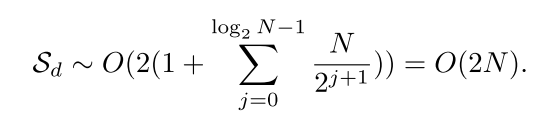
在重构过程中,我们需要一个数组来存储从当前DWT重构获得的分量,单通道信号重构包括
l
o
g
2
N
log_2 N
log2N DWT重构,而DWTDR重构包括
(
1
+
l
o
g
2
N
)
(1+log_2N)
(1+log2N)信号重构。因此,在DWTDR重构过程期间IQ信号的空间复杂度为:
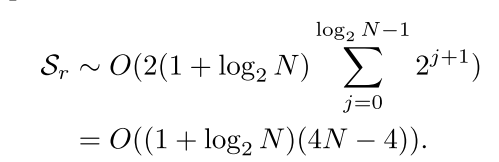
最后,我们可以得到DWTDR的空间复杂度:
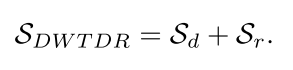
E.Graph Network
这里讲的是用图形表示IQ信号,然而,这些图映射方法很耗时,特别是在处理长信号时,所以我们提出了一种方法称为LFGM,来映射IQ信号到图形。通过LFGM,我们用相同结构的图来表示不同的IQ信号。不同之处在于不同图中节点的特征向量。将IQ信号映射到图形的过程见下面的伪代码:

以下是伪代码的详细步骤解释:
输入
- 超参数 ( k ) ( k ) (k):控制节点之间连接的范围。
- IQ信号 ( S I Q ) ( S_{IQ} ) (SIQ):包含 ( I ) ( I ) (I)(同相分量)和 ( Q ) ( Q ) (Q)(正交分量)的时间序列信号。
输出
- 图 ( G = ⟨ V N , E ⟩ ) ( G = \langle V_N, E \rangle ) (G=⟨VN,E⟩):包含节点集合 ( V N ) ( V_N ) (VN) 和边集合 ( E ) ( E ) (E)。


具体地,对于长度为N的无线电信号样本
S
I
Q
S_{IQ}
SIQ
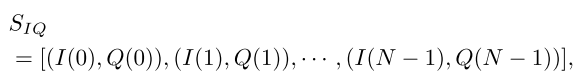
我们把它转换成相应的图
G
=
⟨
V
N
,
E
⟩
G = \langle V_N, E \rangle
G=⟨VN,E⟩。其中
V
N
V_N
VN和
E
E
E表示图G的节点集和边集。在图
G
G
G中,
N
N
N个节点对应于相应IQ信号的时间采样点,节点的属性值是由采样点对应的IQ通道的两个值组成的向量。图
G
G
G的边由时间采样点的距离决定。间隔小于
k
k
k的时间采样点可以形成边,其中
k
k
k是一个超参数,可以用来控制图
G
G
G的连接关系的稀疏性。
k
k
k越大,生成的图越密集。为了更好地保留原始IQ信号的隐含信息,我们将
k
k
k设置为无线电信号的过采样率。

我们以
v
3
v_3
v3为例子,
4
−
3
=
1
4-3=1
4−3=1小于2,所以
v
3
v_3
v3连接
v
4
v_4
v4,而不能连接其他的节点。
在将每个IQ信号映射到相应的图中之后,现有的用于图分类的GNN可以直接用于无线电信号调制分类。用GNN进行图分类是根据拓扑连接关系学习每个节点的嵌入表示向量,文章选择DiffPool对映射图进行分类,DiffPool实际上是一个可微分图池模块,可以生成图的层次表示,并且可以以端到端的方式与各种图神经网络架构相结合。DiffPool的架构图如图所示。
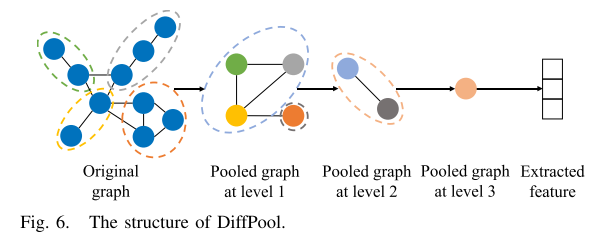
- 原始图经过第一层池化,节点被聚合成超节点。图中用不同颜色(例如绿色、灰色、黄色和橙色)表示不同的超节点,每个超节点代表了一组原始节点的聚合。
- 第一层池化后的图进一步经过第二层池化,超节点再次被聚合成更高层次的超节点。图中用蓝色和灰色表示这一级别的超节点。
- 第二层池化后的图继续进行第三层池化,形成更少的超节点,用橙色表示。
- 最终,经过多层池化后的图被转化为一个特征向量,提取出了代表图的全局信息的特征。

它为每一层中的节点学习可区分的集群分配,将节点映射到一组集群,然后形成下一个GNN层的粗糙化输入。图的边连通度一般用一个形状为
N
×
N
N×N
N×N的矩阵表示。为了保存存储空间,我们可以用
S
E
S_E
SE二进制群来表示边集,其中
S
E
S_E
SE表示图中边的个数。
通过算法3,我们得到了
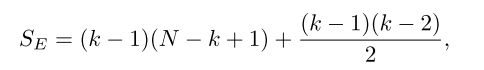
因此LFGM的空间复杂度为
O
(
2
S
E
)
O(2S_E)
O(2SE)
F.Fusion Training
通过这三个训练好的模型,可以分别得到输入格式为序列、图像和图形的分类模型的特征向量
F
S
F_S
FS、
F
I
F_I
FI和
F
G
F_G
FG。
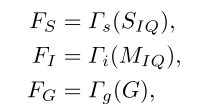
Γ
s
\Gamma s
Γs、
Γ
i
\Gamma i
Γi、
Γ
g
\Gamma g
Γg分别表示训练好的没有最后一个分类层的ResNet18、LSTM和DiffPool模型。然后,对所获得的三个特征向量
F
S
F_S
FS、
F
I
F_I
FI和
F
G
F_G
FG执行相同的归一化处理,并且将三个归一化向量拼接以获得如下融合特征向量
F
H
F_H
FH:
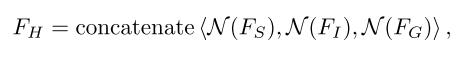

这个
N
N
N代表了归一化运算。其中
v
v
v是要处理的一维特征向量,
l
l
l是向量
v
v
v的长度,
v
i
v_i
vi表示
v
v
v的第
i
i
i个元素,
ϵ
\epsilon
ϵ是一个小值,用于避免被零除,
∥
v
∥
p
\left \| v \right \| _p
∥v∥p表示
v
v
v上的L-p范数运算,
p
p
p表示范数公式中的指数值,|·|是绝对值运算。随后,增加用于分类的全连接层,并将拼接后的融合特征向量
F
H
F_H
FH用作新层的输入:
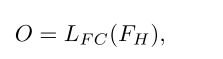
其中
L
F
C
L_{FC}
LFC表示添加的全连接层,
O
O
O是预测的标签.最后,将基于序列、图像和图形的前三个网络的最后一个全连接层去掉,并将神经网络与新增加的全连接层进行融合训练。在融合训练的过程中,新的全连接层需要用更大的学习率进行训练,其他神经网络层
Γ
s
\Gamma s
Γs、
Γ
i
\Gamma i
Γi、
Γ
g
\Gamma g
Γg需要用更小的学习率进行微调。
SIMULATIONS
A.Datasets
文章使用三个无线电信号数据集RML2016.10a [25],SigData18和SigData36来展示我们提出的DeepSIG的性能,其中第一个是公共数据集,另外两个是文章作者团队自己生成的。下表是其基本信息:
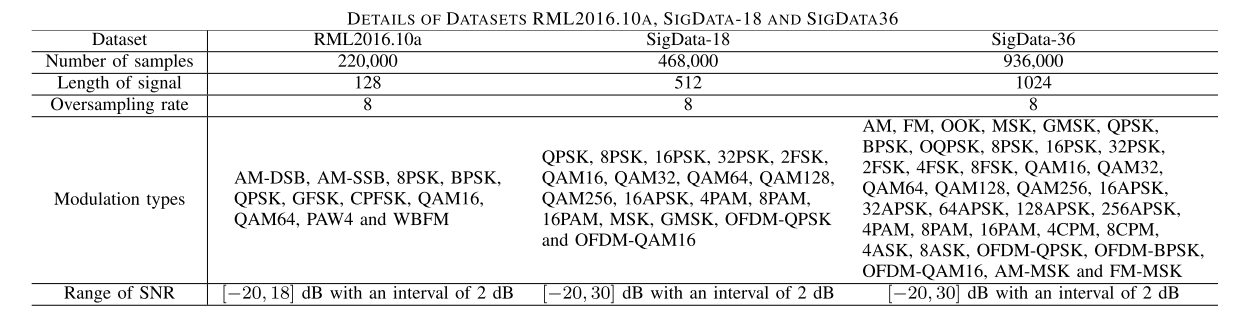
其中,RML2016.10a有11种调制方案。每种调制的信噪比(SNR)范围为−20 dB至18 dB,间隔为2 dB。每个信号的长度为128,过采样率为8。该数据集共有220000个样本。在仿真过程中,我们取800个从每个调制方案中,作为样本训练,剩下的作为测试样本。
SigData-18包含18种调制方案。信号长度为512,过采样率为8。脉冲整形采用升余弦滤波,滚降系数在[0.2,0.7]范围内随机选择。SNR范围为−20dB至30dB,间隔也为2dB。我们在每个调制方案的每个SNR下从该数据集中随机挑选800个信号作为训练集,并将剩余样本合并到测试集中。
SigData-36类似于SigData-18,除了SigData-36的信号长度为1024,并且它具有额外的18种调制方案,即BPSK,OQPSK,32APSK,64 APSK,128 APSK,256 APSK,4ASK,8ASK,4FSK,8 FSK,4CPM,8 CPM,OOK,AM,FM,AM-MSK,FM-MSK和OFDMBPSK。
B. Simulation Setting
所有仿真过程都在NVIDIA Tesla T4上运行。在训练过程中,我们使用的深度学习框架是PyTorch。我们使用PyTorch Geometric来构建GNN模型DiffPool。优化器和损失函数分别是Adam和交叉熵。在训练模型时,我们使用固定步长的学习率衰减策略,初始学习率为0.001,每5个epoch调整一次学习率,衰减到前一个值的80%。此外,在对DeepSIG进行融合训练时,除最终分类层外的其他网络层的初始学习率均设置为0.00001。在数据集RML2016.10a、SigData—18和SigData—36上训练时,minibatch大小分别设置为128、128和32。我们在通过DWTDR将IQ信号映射到图像的过程中使用的小波函数是Daubechies(db1),即Haar。当在0.5%、1%和完整训练集的数据集RML 2016.10a上训练DeepSIG时,(28)公式中提到的 p p p分别被设置为(50,1)和1,并且在其他情况下指数值 p p p被设置为2。
C. Performance of DWTDR and LFGM
为了验证DWTDR和LFGM的性能,文章采用了GAF和AVG(两种图形转化算法)作为对照。自适应可见性图(AVG)、Gramian角场(GAF)。然后下文给了选择GAF和AVG的一些理由。
为了公平起见,在用GAF和DWTDR将信号映射到图像后,使用ResNet18模型进行分类。对于AVG和LFGM,都结合DiffPool模型进行分类,结果展示如下:
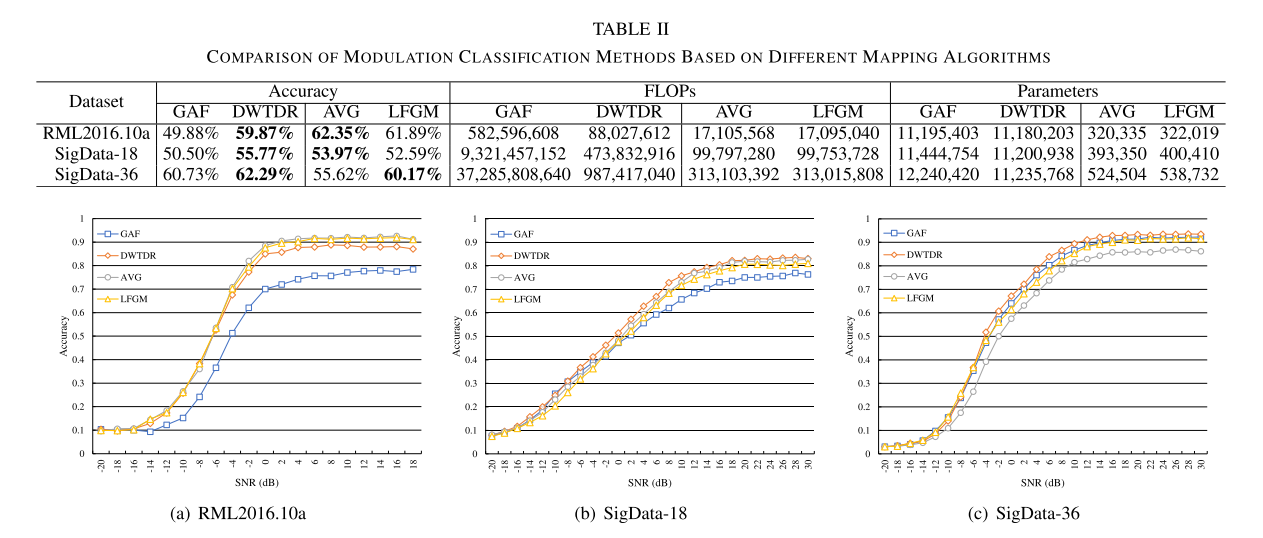
其中,表II中的“FLOP”和“Parameters”分别表示当推断IQ信号样本时计算中的相应浮点运算和存储中的参数的数量。我们可以看到,与GAF相比,基于我们提出的DWTDR的调制分类方法在三个数据集上具有更高的准确性,特别是在RML2016.10a和SigData-18上。由于LFGM得到的窄边矩阵比GAF得到的窄边矩阵小得多,因此基于LFGM的调制识别方法的总体计算复杂度和空间复杂度都明显小于基于GAF的调制识别方法。
通过比较基于可训练映射算法的AVG和基于固定映射规则的LFGM的结果可以看出,我们提出的LFGM在复杂长信号数据集SigData—36上具有更好的性能,准确率提高了约4%,但不可否认的是,RML 2016.10a和SigData—18上的平均分类准确率分别降低了约0.4%和1.4%。与通过神经网络层学习和调整映射图结构的AVG相比,虽然LFGM在两个信号相对较短的数据集上的性能略低,但LFGM更简单高效,直接使用相同结构的图来表示不同的信号,不需要在用于学习图结构的神经网络层上花费冗余的资源和时间。表II中的“FLOP”表明基于LFGM的分类方法的计算复杂度上级基于AVG的分类方法。因此表II中基于AVG的分类方法的“Parametes”不包括图形的边缘信息。
基于LFGM的分类方法的“Parameters”是通过考虑边缘信息参数和模型参数而获得的参数的数目。在上述三个数据集的仿真中,当处理相同的无线电信号时,基于AVG获得的映射图中的边的数量通常多于基于LFGM获得的映射图中的边的数量。因此,实际上,基于LFGM的分类方法的参数的数目少于基于AVG的分类方法的参数的数目。总的来说,我们提出的DWTDR和LFGM在分类精度和实现可行性方面具有良好的性能。
D. Results on Complete Datasets
文章首先讨论DeepSIG在上述三个数据集上的调制分类性能。使用了第二节中提到的序列、图像和图三种分类方法。单独使用图像、序列、图形方法分别和把它们结合在一起的DeepSIG方法去做一个比较。比较的结果如下表所示
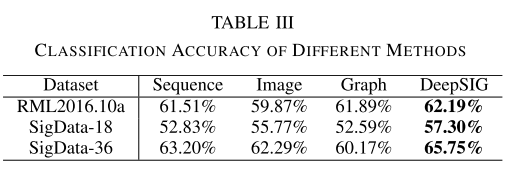
得出结论:DeepSIG可以将分类准确率大幅提高近2.5%。
下图展示出了在不同SNR上的调制分类精度:
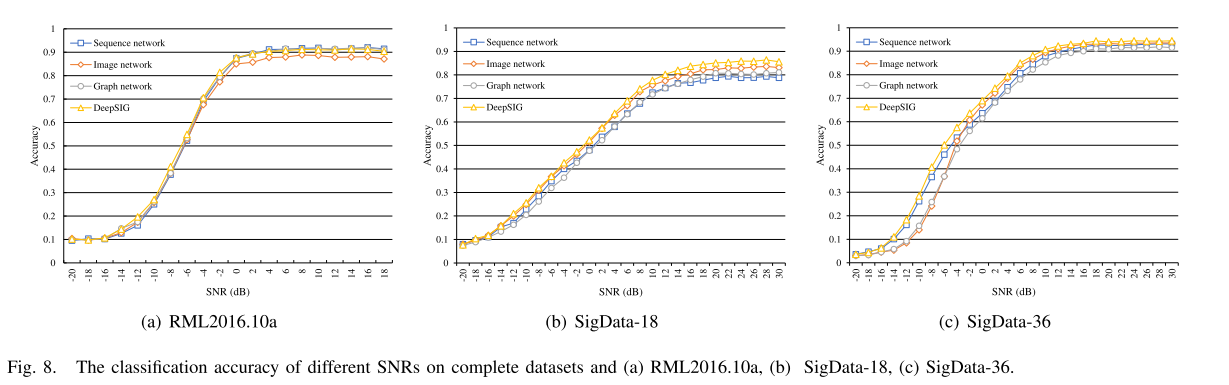
很明显,在数据集RML2016.10a上,我们提出的DeepSIG在− 12 dB和− 8 dB等低SNR下略有优势,在其他SNR下的性能与其他方法基本相同。根据图8(b)所示的数据集SigData-18的详细分类结果,我们可以看到DeepSIG的性能明显优于其他三个单独的分类网络,特别是在8 dB以上的高SNR下。
从图8(c)可以看出,集成了三个独立分类网络的DeepSIG也可以提高数据集SigData-36的调制分类精度,特别是在-12 dB和2 dB之间的SNR区域。
在一定程度上可以说明,DeepSIG通过LSTM处理IQ序列数据可以提取时间信息,也能够通过处理映射的图像和图形,挖掘原始信号潜在的图像表示特征和潜在的图形特征。它可以充分利用这三个不同尺度上的特征来提高调制分类的准确性。
为了进一步分析这些方法在不同调制类型下的识别性能,我们绘制了SNR = 10 dB时的混淆矩阵,如图所示
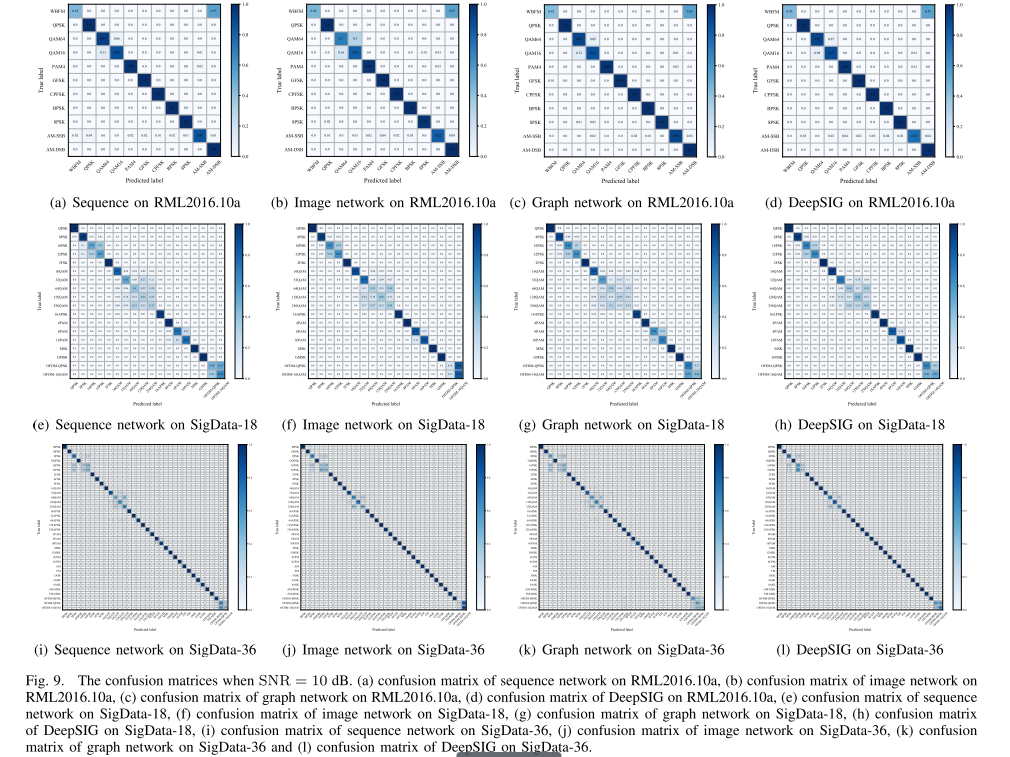
混淆矩阵就对其分类的结果进行了进一步的验证。
从图9(a)至图9(d)可以看出,在调制类别数量相对较少的数据集RML 2016.10a上,这些方法的分类精度相似,混淆矩阵差异不明显。这些方法都容易将WBFM误认为AMDSB。
图9(e)至图9(h)是数据集SigData-18上的混淆矩阵。可以很明显的观察出DeepSIG的性能更优越在8PAM和16PAM,图像网络容易将OFDM—QPSK误分类为OFDM—16QAM,相比之下,图网络和DeepSIG对OFDM—QPSK的识别准确率更高。
对于数据集SigData—36,从图9(i)到图9(l)可以看出,与其他三个单独的分类网络相比,混合异构DeepSIG在64QAM、128QAM和256QAM的识别能力上有一定的提升。
总的来说,基于深度学习的调制识别网络本质上可以分为特征提取和分类。前者可以自动学习和提取能够代表输入信号的特征表示,而后者基于提取的特征向量进行分类处理。简单的说就是,提取的特征越多,对分类越有利。文章提出的混合异构框架DeepSIG包括三种不同类型的神经网络,可以处理代表同一信号样本的三种不同类型的输入,并从不同方面从原始信号数据中提取三个包含隐含信息的特征向量。这三个特征向量的融合导致更丰富和更全面的特征表示,通过充分利用丰富的特征,允许更好的分类性能。
E. Results in Few-Shot Scenarios
现在是对少样本的场景分析DeepSIG的性能,模拟也是基于上述三个数据集。与上文不同的是,文章只使用训练集中的一部分数据来训练网络模型。三种少数情况,其中训练样本是从原始训练集中以不同比例随机提取的,分别是0.5%、1%和5%。仿真的结果如下表和图所示。
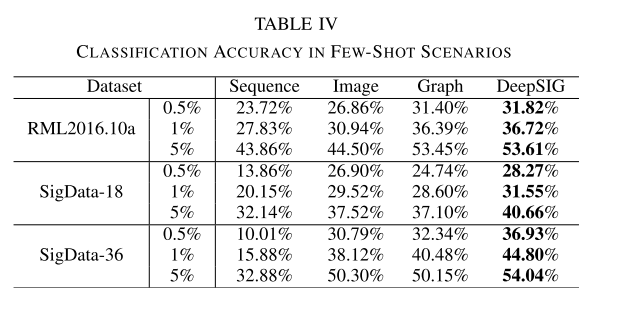
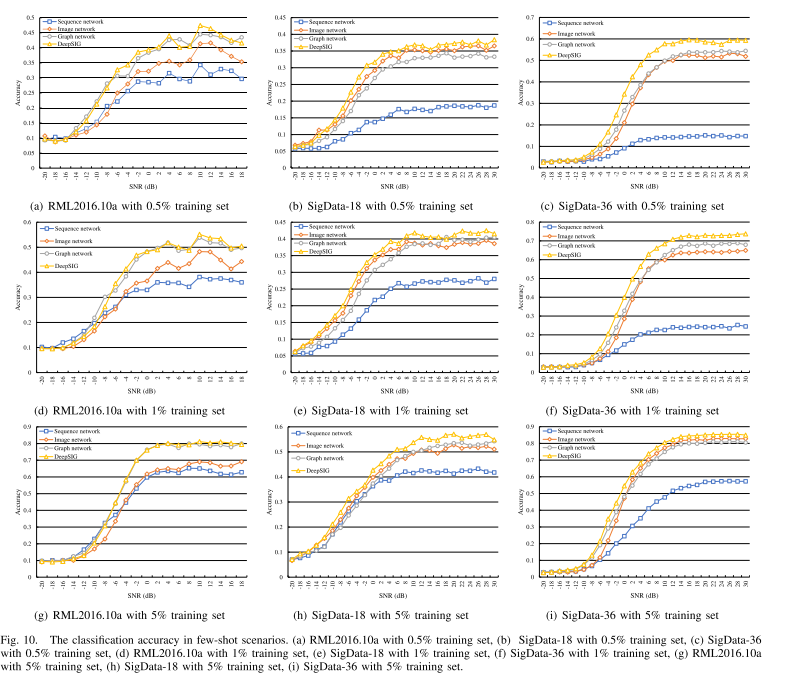
从表四可以看出,在三个少样本的场景中,DeepSIG的分类性能最好。RML2016.10a的类别较少,还有一定的进步空间。在另外两个数据集上,即,SigData-18和SigData-36,DeepSIG在分类准确性方面在少数场景中具有更好的分类性能。
在数据集SigData—18的三个少样本中,与三个单独的分类网络(图像、图形、序列)相比,DeepSIG的性能将提高至少2%。在数据集SigData-36上,性能增益至少为4%。
从图10中可以看出,DeepSIG在数据集SigData—18和SigData—36的几乎所有SNR中都具有比其他模型更高的分类准确度。这些结果表明,DeepSIG可以从不同角度充分挖掘和利用特征信息,以提高复杂无线电信号的少样本学习中的调制分类性能。
在实际的场景中,训练的样本常常是不足够的,此时,我们可以使用本文提到的三种不同形式的输入来表示同一个信号样本,然后从不同的角度提取、融合和使用信号特征表示,以在训练样本有限的场景下尽可能提高调制识别精度。
CONCLUSION
在本文中,我们提出了一种用于无线电调制分类的混合异构深度学习框架,即DeepSIG。DeepSIG接收输入数据,这些数据可以以三种不同的格式表示IQ信号:序列,图像和图形。更重要的是,DeepSIG集成了RNN,CNN和GNN领域的网络模型。在三个无线电信号数据集上的仿真结果表明,我们提出的DeepSIG比基于三个独立字段的模型具有更好的分类性能。它的性能增益更明显,特别是在少数镜头的情况下。
在未来,我们将尝试其他映射方法,将IQ信号映射到图像和图形中,并研究DeepSIG中的其他RNN,CNN和GNN架构。此外,我们将进行空中实验,以进一步验证所提出的方法的性能。
















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











